






















Instaclustr has made available a preview release of our managed service for Apache Spark running with Cassandra. This release makes the core features of Spark available for use while we work on building out the feature set to improve useability. This blog post explains the features of our current release and the additional features you can expect to see over the following month or two.
Apache Spark is a natural fit with Cassandra. Spark provides advanced analytics capabilities but requires a fast, distributed back-end data store. Cassandra is the most modern, reliable and scalable choice for that data store. Thanks to the Spark Cassandra Connector, the integration between Spark and Cassandra is seamless allowing for efficient distributed processing. You can read more about the benefits of using Spark with Cassandra in our white paper.
Instaclustr is excited to unveil the preview release of our managed Spark offering. This offering has been under development for several months and has been extensively tested by a number of alpha customers. Our integrated offering is now also ready for multi datacenter support.
The primary focus of our Spark offering is to provide a managed service for people who wish to use Spark and Cassandra together as a component of their production application. This preview release provides sufficient functionality to support this use case.
With this release you can:
- provision a Cassandra datacenter with Spark 1.4.1 along with Cassandra 2.1.x or DSE 4.8.x with the click of one extra option in our provisioning screen;
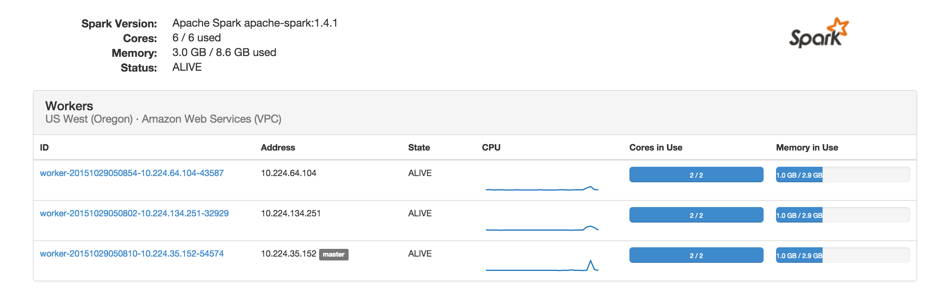
- view key information about the status of your Spark cluster directly within the Instaclustr console; and
- view the native Spark Monitoring UI from your Spark cluster directly from the Instaclustr console with integrated access control.
As this release does not provide any application-level security over Spark job submission, it is most suited to use in a peered-VPC environment in AWS. In this configuration, all network access can be restricted to trusted internal IPs. However, the core of the offering is cloud-provider agnostic and we’re happy to work with any customers interested in running Spark on Azure or IBM SoftLayer to determine an appropriate network security set up for those environments.
We have provided a detailed, step-by-step guide to configuring your environment and submitting your first Spark jobs here.
Of course, labelling this a preview release signals that we don’t quite consider it done yet. The key additional features that we are planning to add over the next month or two include:
- Deploying spark job-server as part of the closer (now released 24 November 2015): this will allow submission of Spark jobs with a less complex client set up and allow us to provide application-level security control over spark job submission.
- Automated fail-over of the Spark Master: currently we are deploying a single Spark master. If this fails, then the whole Spark cluster will become unavailable while our support team manually fixes the issue or provisions a new master. Future releases will automate this fail-over process for minimal downtime.
- Automatically provisioning Apache Zeppelin for Spark clusters: Apache Zeppelin provides a notebook style user interface for performing analysis with Spark. This will allow you to start using Spark to interactive query and analyse Cassandra data without any special client set up.
During our preview period, we are pricing Spark at a 10% premium on top of the existing Cassandra node pricing (as little as $8/month/node on t2.medium size). This pricing will change when we move to full release. Please contact [email protected] if you would like more information or need to lock in longer term pricing. During the initial release period, the ability to request Spark as part of a cluster is not enabled by default. Please contact [email protected] to have it enabled for your account.
For existing customers, you can use the Instaclustr console to add a new Cassandra datacenter with Spark to your existing cluster (in most case this is the recommended configuration to avoid analytic load impacting production load). Spark can be added to an existing Cassandra datacenter by our support team (email [email protected]).
We’re really excited to be announcing the major extension to our offering and capability. Please get in touch via [email protected] if you have any feedback or questions.