A lot of people new to data science don’t know what to do after they write their first Python or R script. While that web scraper may have run well on your laptop—one time, you need to think about a streaming architecture that can handle multiple datasets. You need to not only store the results but you want to visualize them and transform and merge the data to derive meaningful results. Thinking about your data as a stream where you can pipe in multiple datasets is a useful way of thinking about it. You also want to architect a solution that is scalable, pluggable, and reusable.
Recently I’ve been seeing, and using myself, an EKK stack (Elastic, Kibana, and Kafka) instead of ELK stack to solve problems like these. Pairing Elasticsearch and Kibana with the enterprise connectivity and event-driven and powerful ETL features of Kafka yields a very robust and adaptable stack. Below I’ll work with some COVID-19 data using the EKK stack.
The Problem
The general task at hand is to make sense of a wide variety of JSON datasets, visualize them, and transform the data into resulting streams. To solve this problem, first we use Docker to remove the overhead of setting up the environment. Once everything is Dockerized, we have to figure out how to connect the various technologies for our workflow engine.
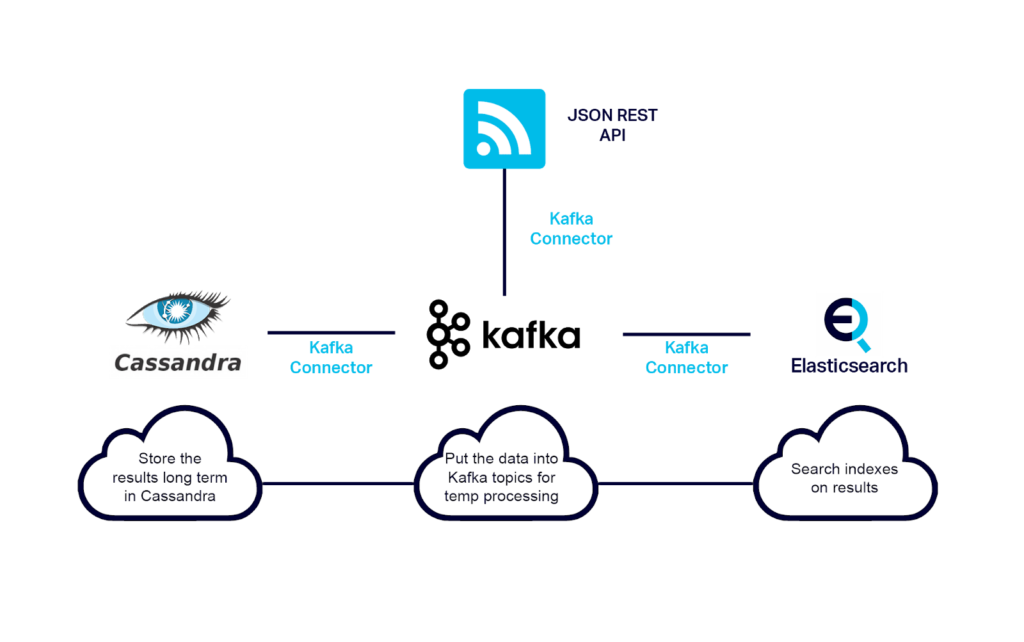
The Technology Stack: EKK stack and more
- Python: the industry standard for most data science
- Kafka: the industry standard for a streaming platform/application messaging/distributed commit log
- Kafka Connectors: these allow us to move data cleanly between various data systems and with zero maintenance overhead
- REST connector: pull data from a REST API and put into Kafka
- Elasticsearch Sink Connector: read data from Kafka and put into Elasticsearch
- Elasticsearch: arguably the industry open source standard for big data pattern recognition and visualization engines
- Kibana: the main Elasticsearch visualization engine
Technology Overviews
Kafka and Connectors
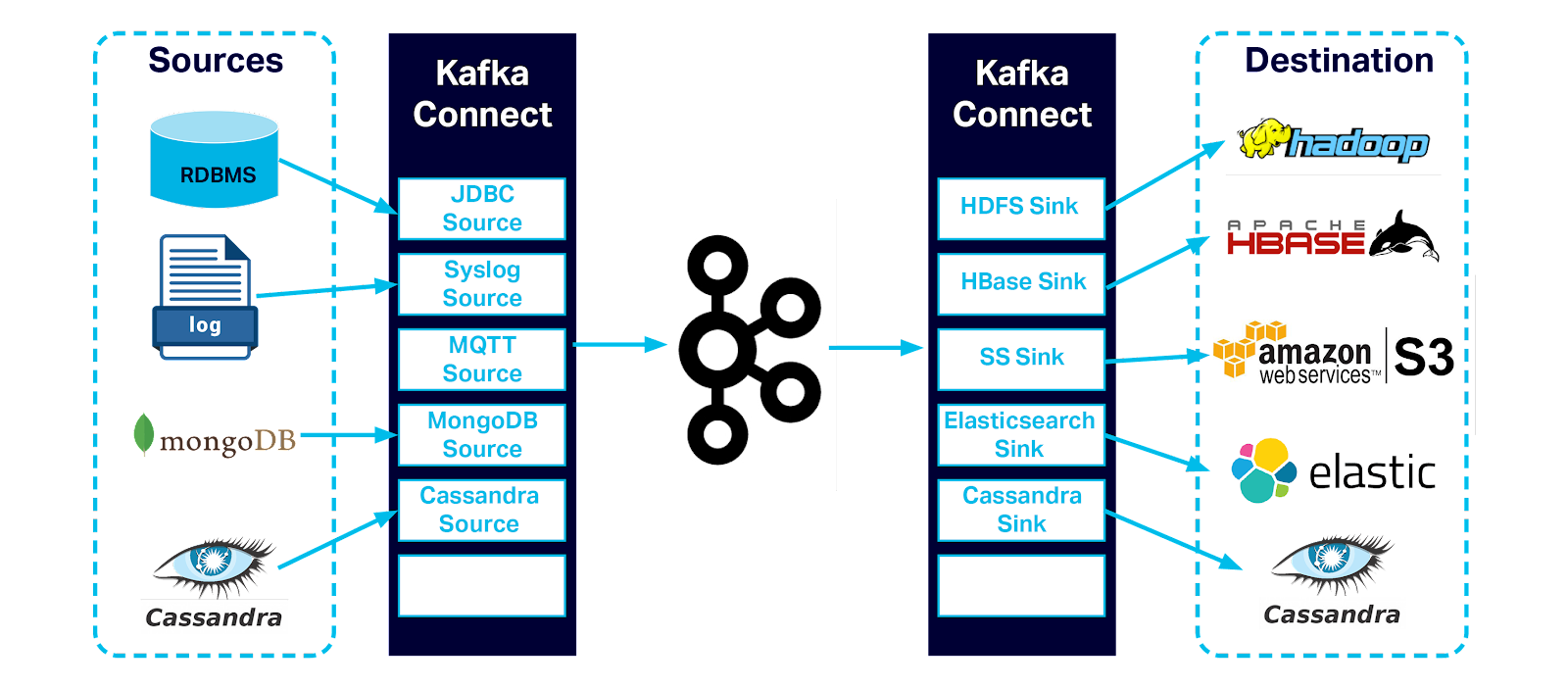
Kafka is a real time streaming platform based on a distributed commit log. You can store any kind of data in it and read it with any programming language. This is a reliable highway infrastructure system. Producers write data to Kafka and Consumers read data from Kafka.
Kafka Connectors are mature and purpose built producers/consumers for specific data systems. There is a connector for reading/writing data from Elasticsearch to Kafka. There is also a connector for reading from web API(s) and storing the data in a Kafka topic.
A move to EKK from ELK Stack – Elasticsearch + Kibana

In this workflow we use Elasticsearch as our pattern recognition engine and its built-in Kibana as our visualization frontend. Elasticsearch is an open source scalable search engine used for monitoring, alerting, and pattern recognition. Elasticsearch works with highly structured JSON documents which are placed into an index. You interact with Elasticsearch using a REST API.
Writing a Data Scrubber
In this exercise, we will be using Python 3 to clean the data stored in Kafka and place it into Elasticsearch. You can use any Kafka client library, however, Python is very easy to use and is readable to anyone.
Solution Architecture Overview
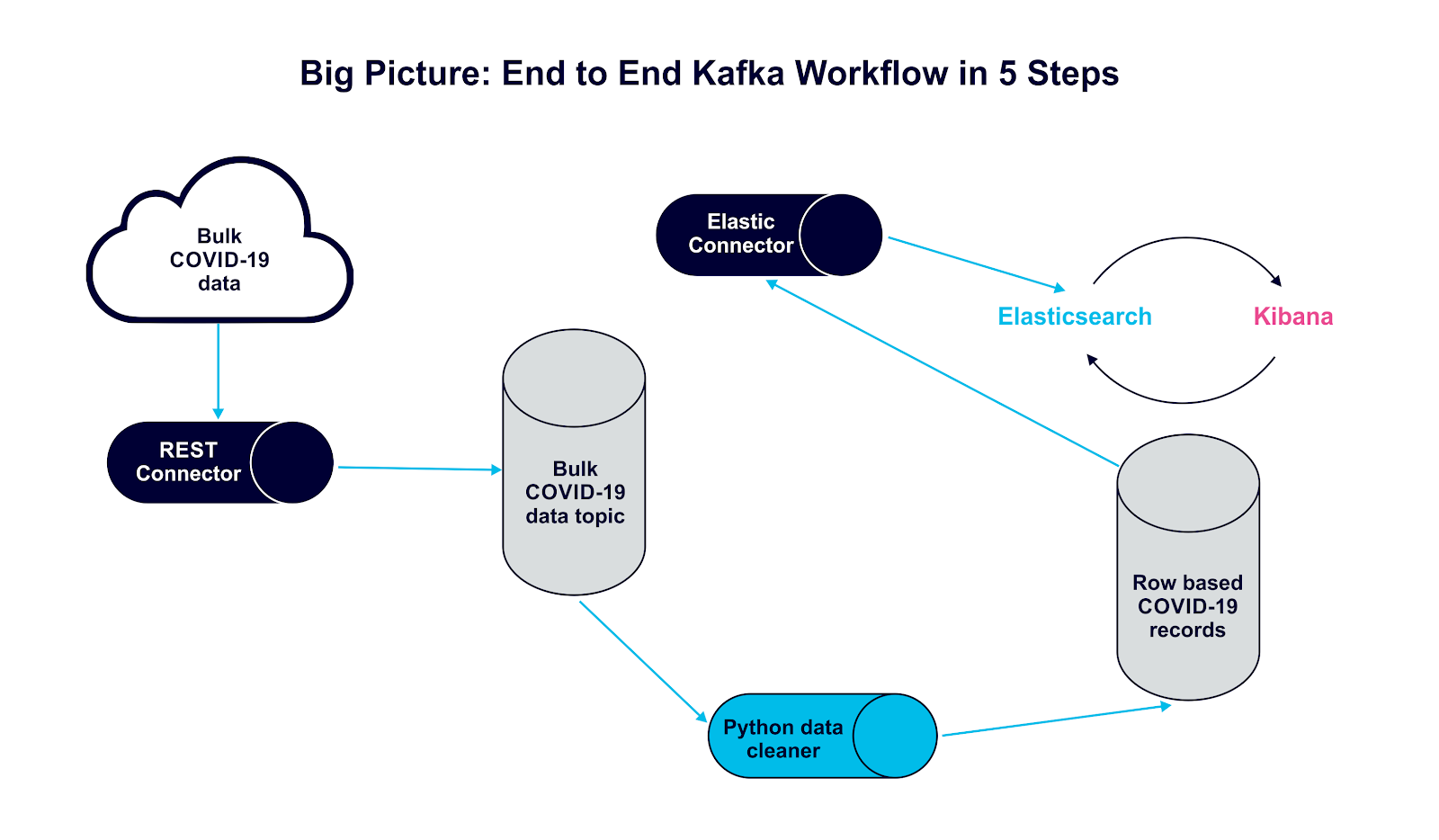

Essentially, our Kafka connector will pull new COVID_19 data every 24 hours and put it into a Kafka topic called Covid19Global. Our Python application will pull the latest record, go through all the data, and send each record one by one with a country key to another Kafka topic called covid19.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | import json import datetime from kafka import KafkaConsumer from kafka import KafkaProducer #if you want to run outside of docker, simply change bootstrap_servers="localhost:29092" # Here we connect to the kafka cluster and grab just one record, all covid data is a giant data dump, we are converting into a stream consumer = KafkaConsumer('covid19Global',max_poll_records=1,bootstrap_servers="kafka:9092", group_id=None, auto_offset_reset="earliest") # we will also be producing our records producer = KafkaProducer(bootstrap_servers="kafka:9092", key_serializer=str.encode,value_serializer=lambda v: json.dumps(v).encode('utf-8')) for message in consumer: covid = json.loads(message.value) for key in covid: # print(key) for i in covid[key]: # we need to ensure our data format is correct to merge the data streams # i.e. -> “date”:“2020-01-02" != “date”:“2020-1-2", record_date = datetime.datetime.strptime(i['date'], '%Y-%m-%d') record_date = record_date.strftime('%Y-%m-%d') i['date'] = record_date i['country'] = key #we are sending our records to a new topic called covid19US producer.send('covid19', key=record_date, value=i ) print(i) |
You can run this code using docker instead of setting up a Python environment on your machine.
Running the Solution
First you need to set up Docker and Git on your machine
1 | git clone https://github.com/meticulo3366/cassandra-kafka-elasticsearch-open-source.git |
Open the readme here and follow the instructions
Also you can read them directly below.
Turn on docker if you have not done so already
1 | docker-compose up --force-recreate -V --remove-orphans --always-recreate-deps |
Open another terminal and push in COVID19 Data.
1 | curl -X POST -H 'Accept: application/json' -H 'Content-Type: application/json' http://localhost:8083/connectors -d @connector-configs/covid19restALL.json |
Open another terminal and push in Stock Trading Volatility VIX Data.
1 | curl -X POST -H 'Accept: application/json' -H 'Content-Type: application/json' http://localhost:8083/connectors -d @connector-configs/vixrest.json |
Run the Python data cleaner.
To run the data cleaner, follow the instructions below
Open another terminal and Run the code to clean the data.
1 | docker run --rm -ti --network cassandra-kafka-elasticsearch-open-source_default -v `pwd`:/usr/src/app jfloff/alpine-python:3.7-slim -A /usr/src/app/apk-requirements.txt -B /usr/src/app/build-requirements.txt -r /usr/src/app/requirements.txt -- python3 /usr/src/app/covid19_datacleaner.py |
Open another terminal and validate that you have cleaned the data successfully.
1 | docker exec -it cassandra-kafka-elasticsearch-open-source_connect_1 bash -c "kafka-console-consumer --bootstrap-server kafka:9092 --topic covid19 --from-beginning" |
Open another terminal and send the data to Elasticsearch.
1 | curl -X POST -H 'Accept: application/json' -H 'Content-Type: application/json' http://localhost:8083/connectors -d @connector-configs/covid19elk.json |
Open another terminal and validate Elasticsearch has ingested the data.
1 | curl http://127.0.0.1:9200/covid19/_search/?size=1000&pretty=1 |
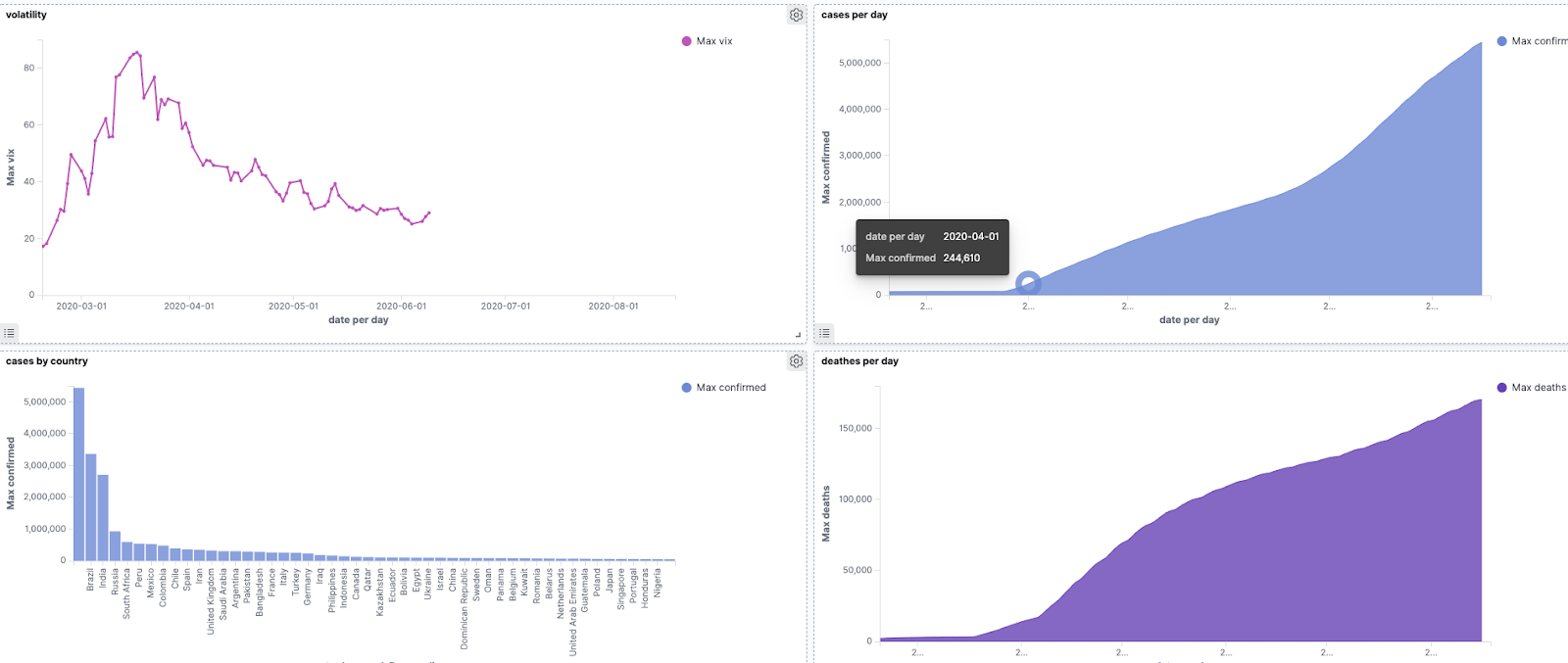
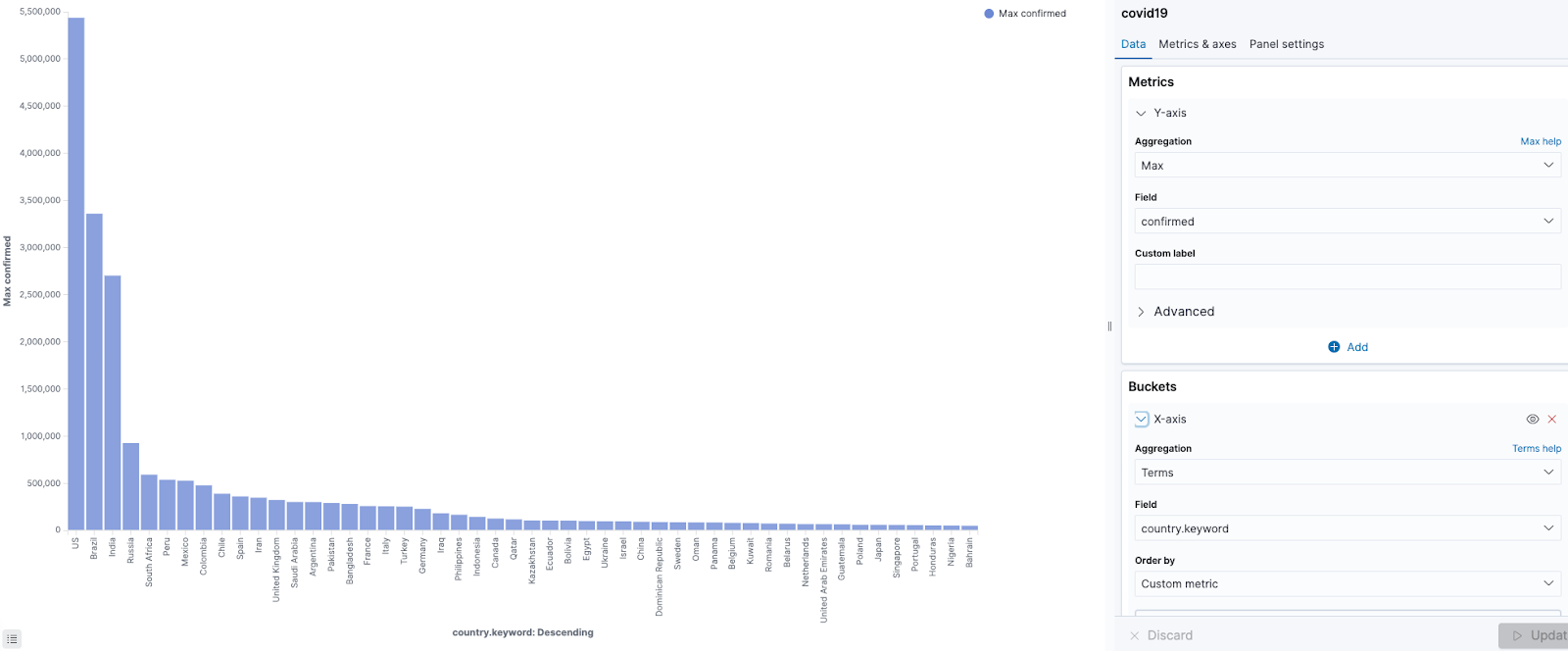
Finally you can navigate to Kibana to start visualizing and exploring the COVID-19. Here are some visualizations of the data below showing cases over time and by country.