






















Overview
An end-to-end demonstration of Instaclustr’s Provisioning API for any use case involving automated programmatic cluster provisioning, configuration, discovery, and de-provisioning (or a subset of these operations).
1. Provisioning
Provisioning: Supply with food, drink, or equipment, especially for a journey.
Provisioning is all about ensuring you have sufficient quantity of provisions (food, drink, etc.) sufficiently far ahead of when you need them. For example, Napoleon’s staff sent dispatches to cities along the proposed routes to secure provisions and supply the army along the way. After the French Revolution, unemployed chefs from aristocratic households started private restaurants, introducing upper-class dining habits and gourmet food to the masses. After the defeat of Napoléon, wealthy Europeans flocked Paris to partake in the many gourmet dining options, and waiters became an essential part of the dining experience.

Un garçon de café (Source: Shutterstock)
However, fine dining, or even something as simple as ordering a side order of toast in a cafe, can be an intimidating experience:
What do you mean you don’t make side orders of toast? You make sandwiches, don’t you?
…
I’d like a chicken salad sandwich on wheat toast, no mayonnaise, no butter, no lettuce…and hold the chicken.”
Five Easy Pieces (1970)
A royal banquet is even worse, as it involves even more complex protocols and everything runs on the Queen’s eating schedule:
Don’t sit before the Queen, you can only eat when the Queen eats (this means you have to eat as quickly as the Queen as the courses are replaced as fast as the Queen finishes hers), and if you manage to keep ahead of the Queen and you want to put your cutlery down for a rest while eating—without your plate being instantly removed—you have to use the correct cutlery resting position!

Formal table setting (Source: Shutterstock)
So, if you are intimidated by waiters, formal table settings, complex restaurant etiquette, or royal protocol, but still want to eat, an Automat could be the answer (not to be confused with Laundromats). An Automat was a restaurant where food and drinks were served by vending machines. The world’s first Automat opened in Berlin, in 1895, and quickly became popular in the USA.
 Automat in Manhattan, 1936 (Source: Berenice Abbott – Wikipedia)
Automat in Manhattan, 1936 (Source: Berenice Abbott – Wikipedia)
All of the Automats in New York have long gone, but you can still experience the benefits automated (cluster) provisioning with Instaclustr’s Provisioning API.
2. Instaclustr APIs and Use Cases
Instaclustr offers a comprehensive DevOps solution for managed Apache Cassandra/Spark and Kafka clusters, via our APIs which include: Provisioning API, Monitoring API, and Kafka User Management API (This uses the Provisioning API, and manages user Authentication. You can manage Kafka ACLs programmatically from the AdminClient). For Cassandra, you use CQL to manage users. This blog focuses on the REST Provisioning API.
When would you use the Provisioning API in preference to the Instaclustr Console? Typically for any use case involving automated programmatic cluster provisioning, configuration, discovery, and deprovisioning (or a subset of these operations).
For example, DevOps use cases involving automated testing, including functional, performance and scalability testing. Benchmarking is another typical use case, I used the Provisioning API in the Anomalia Machina blog series to automate the benchmarking to ensure that the results were accurate, affordable, resizeable, and repeatable.
The Provisioning API is also applicable for use cases where multiple production clusters are required (i.e. provisioning but not deprovisioning). For example, some Instaclustr customers may have a requirement to run a separate cluster for each of their end-user clients, and the Provisioning API would enable automation of the process of cluster creation, configuration, testing, and initial of loading of generic and client-specific data.
Finally, the Provisioning API can also enable Cassandra Cluster Auto-scaling and Elasticity! We will look at this use case in more detail in the next blog.
3. Provisioning API Operations
Instaclustr’s Provisioning API has groups of operations for Clusters, Firewall Rules, VPC Peering, Backup and Restore (Cassandra only), and Dynamic Resizing (Cassandra only) as follows.
3.1 Cluster Operations
 Hubble (HST) image of star cluster Messier 15 (Source: Wikipedia)
Hubble (HST) image of star cluster Messier 15 (Source: Wikipedia)
Create Cluster
Create Cluster initiates cluster provisioning for Cassandra or Kafka clusters, with optional add-ons for each cluster type (Spark, Zeppelin, Lucene Index plugin, and Continuous backup, for Cassandra; Rest Proxy, Schema Registry for Kafka; Private Network Cluster for both). You have to supply configuration request details including the cloud provider, region, node type, number of nodes, initial firewall rules, authentication, and encryption options, and addon optional bundles and configurations. If the request is valid the operation starts the provisioning process (which may take some time) and returns a Cluster ID which can be used in other operations.
Cluster Status
Given a Cluster ID, this operation returns detailed information about the cluster and nodes, including the configuration and IP addresses of each node, and provisioning status of the cluster and each node. This allows the progress of the cluster provisioning to be tracked.
Delete Cluster
Given a Cluster ID, this operation deletes the cluster resources and therefore the Cluster ID.
Note that you can protect a cluster from accidental deletion with “two-factor delete confirmation”. If this protection has been enabled for a particular cluster, then the Delete Cluster operation doesn’t immediately delete the cluster but instead sends a request for deletion which requires an email confirmation before being eventually acted on. From the Provisioning API perspective, the cluster state is unchanged while waiting for confirmation (but in the Instaclustr console you can see that a delete has been requested for the cluster).
List All Clusters
What if you forget or don’t know the Cluster ID? This operation returns high-level information for all the active clusters in your account, including Cluster IDs and name, and what’s running in each (e.g. Cassandra, Kafka, etc.). It doesn’t provide the cluster status, however, so you need to then call Cluster Status with one of the discovered ClusterIDs.
Once the cluster is running, the rest of the operations allow changes to be made to the cluster. More information on cluster provisioning is available here.
3.2 Firewall Operations
You can connect to an Instaclustr cluster if the firewall rules have been configured to enable access.
Create Firewall Rule
This operation provisions a new firewall rule for a Cluster ID. It allows client access from an IPv4 CIDR network for the specified cluster or addon type. For Custom VPCs (see below), you must add an AWS Security Group to allow clients to connect to the cluster (we take the approach that the cluster is siloed from everything in the Custom VPC until it’s opened up explicitly).
List Firewall Rules
How do you know if the firewall rule provisioning has completed or what network addresses currently have access to your cluster? You need to use this operation which returns the list of firewall rules for a Cluster ID and their status (“RUNNING” means they are ready).
Delete Firewall Rule
Given a Cluster ID this operation allows you to delete an existing firewall rule. Note that deletion may also take time, so you need to check if the rule has been deleted with the List firewall rules operation (above) before provisioning a firewall rule with the same IP address.
More information on firewall rules is available here.
3.3 VPC Peering Connection Operations
 Peer – a person of equal standing in a group (e.g. members of the British Peerage) Source: Wikipedia Commons
Peer – a person of equal standing in a group (e.g. members of the British Peerage) Source: Wikipedia Commons
In AWS, a VPC Peering is a network connection between two Virtual Private Clouds (VPCs), enabling instances in either VPC to communicate with each other as if they are within the same network.
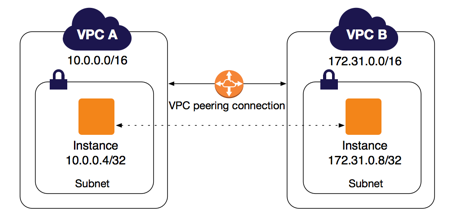
Instaclustr supports VPC peering to enable the connection of client applications in one VPC to Instaclustr provisioned clusters running in another VPC. The VPC Peering operations are isomorphic to the firewall rule operations, with the addition of an extra operation for listing a single VPC connection (the same level of detail is returned):
- Create VPC Peering Request
- List VPC Peering Connections
- List VPC Peering Connection
- Delete VPC Peering Request/Connection
More information on Instaclustr VPC Peering is available here. Custom VPC is also possible, which runs clusters in a VPC that you already have. More information is available here, but note that you must also add a firewall rule (above) with an AWS Security Group to allow clients from the Custom VPC to connect to the cluster. This Security Group can be either the default VPC Security Group (to enable access for all the instances in the VPC), or a more restrictive Security Group (which enables access for only a subset of the instances in the VPC).
3.4 Backup/Restore Operations (Cassandra only)
Instaclustr does automated data backups for all Cassandra clusters every 24 hours by default, and if you have added the Continuous Backup add-on to the cluster, it backups every 5 mins. In addition to these, you can create data backups anytime using our APIs.
Operations for Cassandra cluster data backups are: List Backups, Trigger Backup, and List Backups (again) to check the backup progress. And unlike the other operation types, backups cannot be deleted.
List Backups gives the state (ACTIVE or COMPLETED), start time and progress (0 to 1) of each backup.
More information on cluster backups is available here.
When would you want to trigger a backup? Basically always trigger a backup prior to any major changes to the cluster, including:
- Is your cluster running out of space? Backup and then truncate.
- Are you making table schema alterations? Or creating tables with new schemas and migrating data from old tables to them (e.g. to optimise partition sizes)?
- Any application changes, in case the changes introduce bad data.
The Trigger Restore operation creates a new cluster with the identical topology from either the last backup or a specified backup, for the whole cluster or a subset of tables. You can check the status of the restore by calling the Cluster Status operation. Once the cluster reaches RUNNING the nodes are running and the data has been restored. More information on restoring from backups is available here.
A typical use case for Trigger Restore is for testing an application with existing data. You can create a new cluster with existing data loaded, run some tests, and then delete the new cluster. Note that this only works for Cassandra clusters, for Kafka clusters, Zookeeper (only) is automatically backed up every 24 hours.
3.5 Dynamic Resizing Operation (Cassandra only)
If the cluster is created with resizable instances it can be resized to/from other sizes in the same family (vertical scaling up/down). For more information see here. We currently support AWS r5 instances for dynamic resizing. Resizing is included in the demonstration workflow below (but, for simplicity, not shown in the state diagram), and it only works for Cassandra clusters. We’ll explore dynamic resizing more in another blog.
4. Provisioning API State Machine
In a restaurant, does the order matter for your order? Probably. You could really confuse your waiter but ordering things out of order! The following state machine shows the typical order of courses, and explains why you can’t just order “afters”, and why waiting for the bill is the final state (not the first):
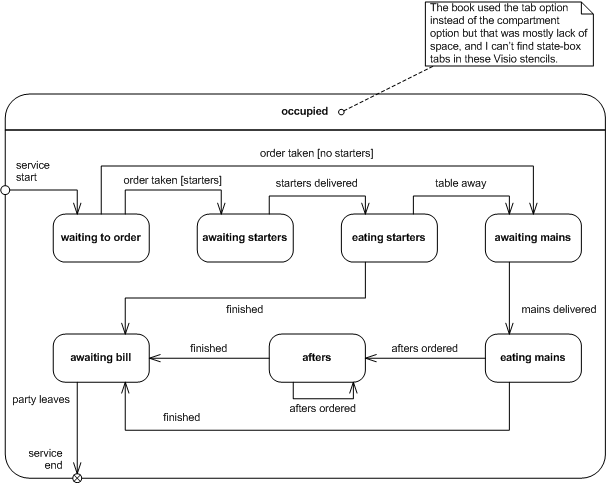
Restaurant orders state machine
Now that we know what the possible Provisioning API operations are, let’s see how they actually work together with a state machine. The following state machine helps to visualise the provisioning API workflow. The circles represent the state of clusters (Black/green), backups (purple), and firewalls (Blue/grey).
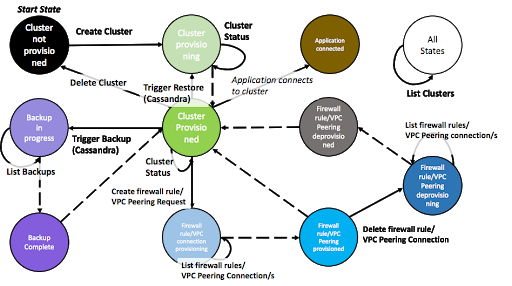
Provisioning API State Machine
If you don’t have a ClusterID (resulting from a Create Cluster operation), then it’s possible to “List Clusters” (the white circle) at any time/state and get the list of all available clusters. The list is empty if no clusters are provisioning or provisioned, and will include clusters that are provisioning or provisioned. Likewise, “Cluster Status” can be run anytime you have a valid ClusterID (even if it’s provisioning, so can be used to check when the cluster is provisioned). This also provides a list of IP addresses for the application to connect to (so would also be called prior to application connection (the brown “Application Connected” circle).
The Black to Green states represent the sequence of operations: Create Cluster, and polling Cluster Status until the cluster is provisioned and Running.
Once the cluster is running, Cluster Status can be used to find the IP addresses of the nodes, and the application can connect to the cluster using this information (brown circle).
The purple states represent backups and the sequence of operations: Trigger Backup, with polling using List Backups until the backup is completed. Once a backup has been completed, the Trigger Restore operation is also possible on a cluster, and results in a new cluster being provisioned with the identical topology and the data restored from a specified backup. Note that Trigger Backup and Trigger Restore are for Cassandra clusters only.
The blue states represent firewall rules or VPC Peering connection provisioning and de-provisioning. The sequence of operations is: Create Firewall Rule/VPC Peering, and poll List firewall rules/VPC Peering Connection/s until the firewall rule/VPC Peering is provisioned. A firewall rule/VPC Peering can be de-provisioned with: Delete Firewall Rule/VPC Peering, and polling with List Firewall Rules/VPC Peering Connection/s until it’s de-provisioned. If you want to provision with the same firewall rule (IP address)/VPC Peering you must ensure the rule is de-provisioned before provisioning again.
Finally, Delete Cluster de-provisions the cluster (this is immediate so there’s no need to check or wait (except in the case where two factor delete protection has been enabled for the cluster, when deletion is delayed until confirmation).
5. Provisioning API Demo
We recently developed an end-to-end demonstration of the Provisioning API. The goal of the demonstration was to show a complete end-to-end example of involving provisioning a cluster, connecting to the cluster, resizing the cluster, deleting the cluster, and using a Java client, exclusively via the Instaclustr Provisioning API.
The main benefit of using the Provisioning API demonstration code is that you don’t need to prepare any JSON payloads or parse any JSON results manually. It’s guaranteed to be “correct” and automatically turns Java objects to/from JSON. How does it do this? I generated Java helper classes either from the documentation or example (e.g. returned) JSON using an online tool for JSON to Java conversion, and a Java library to parse JSON into Java objects for the return values. The Java wrapper methods for the operations take compulsory arguments, generate correct JSON, make the call, get the return value, and parse it into a Java object. There are some Java helper methods that poll some operations, get the results, and then do things like check the progress of an operation or return true/false when an operation is complete.
Note that the demonstration example isn’t exhaustive so some of the Provisioning API methods and JSON payloads are not present, however, it should be straightforward to expand the code coverage by using the two tools suggested and copying the existing examples.
The Demonstration steps consist of provisioning a Cassandra cluster, dynamic resizing workflow, and deprovisioning on AWS as follows.
- STEP 1: Create cluster, wait for cluster to be running
- STEP 2: Create firewall rule, wait for the rule to be running
- STEP 3 (Info): Get IP addresses of cluster
- STEP 4 (Info): Check connecting to cluster (get metadata and connect and read data)
- STEP 5: Resize cluster, wait until cluster resized
- STEP 6: Delete cluster
The “wait” sub steps poll the operation to get the cluster status and analyse the results depending on the context (the previous step) until everything is complete and only then return. If at any point a node has DEFERRED status we give up and exit (as human intervention is required behind the scenes to progress the provisioning). This may happen if (for example) there are insufficient types of the requested instances available in a particular AWS region.
Here’s the demo run for a 6 node cluster with 3 racks, resizing one node at a time (by node), starting with r5.large instances (2 cores), and resizing to r5.xlarge (4 cores):
Welcome to the automated Instaclustr Provisioning API Demonstration
We’re going to Create a cluster, check it, add a firewall rule, resize the cluster, then delete it
STEP 1: Create cluster ID = 5501ed73-603d-432e-ad71-96f767fab05d
Wait until cluster is running…
progress = 0.0%………………….
progress = 16.666666666666664%……
progress = 33.33333333333333%…..
progress = 50.0%….
progress = 66.66666666666666%……..
progress = 83.33333333333334%…….
progress = 100.0%
Finished cluster creation in time = 708s
STEP 2: Create firewall rule
create Firewall Rule 5501ed73-603d-432e-ad71-96f767fab05d
Finished firewall rule create in time = 1s
STEP 3 (Info): get IP addresses of cluster: 3.217.63.37 3.224.221.152 35.153.249.73 34.226.175.212 35.172.132.18 3.220.244.132
STEP 4 (Info): Check connecting to cluster…
TESTING Cluster via public IP: Got metadata, cluster name = DemoCluster1
TESTING Cluster via public IP: Connected, got release version = 3.11.4
Cluster check via public IPs = true
STEP 5: Resize cluster…
Resize concurrency = 1
progress = 0.0%………………………………………………………
progress = 16.666666666666664%………………………..
progress = 33.33333333333333%……………………….
progress = 50.0%……………………….
progress = 66.66666666666666%………………………………………..
progress = 83.33333333333334%………………………….
progress = 100.0%
Resized data centre Id = 50e9a356-c3fd-4b8f-89d6-98bd8fb8955c to resizeable-small(r5-xl)
Total resizing time = 2771s
STEP 6: Delete cluster…
Deleting cluster 5501ed73-603d-432e-ad71-96f767fab05d
Delete Cluster result = {“message”:”Cluster has been marked for deletion.”}
*** Instaclustr Provisioning API DEMO completed in 3497s, Goodbye!
That’s all for this blog. In another blog, we’ll look at dynamic resizing in more detail, including faster resizing by rack, to better understand the tradeoffs between resizing by node vs. by rack, and develop some rules for when to trigger resizing based on current and future cluster CPU utilisation.