






















“Search out thy wit for secret policies, and we will make thee famous through the world.”
[Henry VI Part I, III, 3]
Earlier in 2020 I decided to learn about a new addition to Instaclustr’s managed open source platform, the scalable full text search technology Elasticsearch—using OpenDistro for Elasticsearch, an Apache 2.0-licensed distribution of Elasticsearch enhanced with enterprise security, alerting, SQL, and more.
Being in the Australian COVID-19 lockdown at the time, I found an online course that seemed to have a good mix of theory and practice: Elasticsearch 7 and the Elastic Stack – In Depth and Hands On! This article reveals some of the most interesting things that I learned on my first (and definitely not last) “test drive” of Elasticsearch!

1. Don’t Panic!
Mr Prosser: But, Mr Dent, the plans have been available in the local planning office for the last nine months.
Arthur: Oh yes, well as soon as I heard I went straight round to see them, yesterday afternoon. You hadn’t exactly gone out of your way to call attention to them had you? I mean like actually telling anybody or anything.
Mr Prosser: But the plans were on display…
Arthur: On display? I eventually had to go down to the cellar to find them.
Mr Prosser: That’s the display department.
Arthur: With a torch.
Mr Prosser: The lights had probably gone out.
Arthur: So had the stairs.
Mr Prosser: But look, you found the notice, didn’t you?
Arthur: Yes yes I did. It was on display at the bottom of a locked filing cabinet stuck in a disused lavatory with a sign on the door saying beware of the leopard.
[Arthur’s conversation with Mr Prosser, the local council worker trying to demolish Arthur’s house, in “The Hitchhiker’s Guide to the Galaxy”, by Douglas Adams]

(Source: https://hitchhikers.fandom.com/wiki/Arthur_Dent%27s_house)
His house being demolished turned out to be the least of Arthur’s problems when a Vogon Constructor Fleet arrived to demolish the Earth to make way for a hyperspace express route, much to the surprise of everyone on Earth. After complaining, the Vogons informed the Earthlings that “all the planning charts and demolition orders have been on display at your local planning department in Alpha Centauri for 50 of your Earth years … if you can’t be bothered to take an interest in local affairs, that’s your own lookout. Energize the demolition beams.”
So, being able to find a relevant document in a timely way can be extremely important— particularly if you don’t want your house or planet demolished without warning!
2. What Do You Already Know About Text Search? (Probably More Than Me)
About to launch myself into a crash course in Elasticsearch during the COVID-19 lockdown, I wondered what, if anything, I knew about text search in general, so I did a “self” search!
I don’t recall covering it in my computer science degree (“A long time ago in a galaxy far, far away….”). I suspect this is because text search has its origins in Information Retrieval, which was taught in “Information Systems” courses and ran by the accounting and management school. Apparently, from the 1940s there was considerable progress on the computerized automation of information retrieval, building on manual card catalogs in libraries—also called index cards—typically you could only search by author, title, or subject.

But then I explored things related to just text that I’ve previously come across, with more success.
My first encounter with “text” was in the context of Natural Language Understanding and parsing, when I wrote a Prolog DCGs (define clause grammars) parser for a large subset of the English language. This was actually my second attempt to implement the grammar, my first attempt used LISP and was a lot more complicated. One of the influential thinkers in Natural Language Processing at the time was Terry Winograd. I’ve still got the first (and only) volume of a planned series—Language As A Cognitive Process, Syntax, Volume 1, 1983 (here’s a PDF version).

Interestingly, Winograd was Larry Page’s (co-founder of Google) PhD supervisor! So what made Larry’s search engine better than others? Well, the idea was surprisingly simple, but harder to implement at scale: that the World Wide Web was just a citation system for pages, the more links there are to a page, the more important that page it is likely to be. The algorithm was called PageRank, and this is the original paper: “The Anatomy of a Large-Scale Hypertextual Web Search Engine”.
Significantly, the size of web-scale search required a new approach to high performance computing and resulted in MapReduce (easy to program scalable parallel computing on commodity clusters), which in turn evolved into Apache Hadoop and Apache Spark, and other web-scale technologies such as Apache Cassandra and Apache Kafka.
Another parallel development was in structured document processing using XML (Extensible Markup Language). XML and Web Services were an important part of the research and industry landscapes in the 2000’s, and I made extensive use of the rich set of standards and tools for XML transformation and search such as XSLT, XPATH, and XQuery (these are still W3C standards). Typical of most technologies, Web Services were built on previous ideas, and in turn evolved further into more “modern” REST and JSON web APIs.
Finally, while at NICTA (National ICT Australia) I did some performance modeling for IP Australia —they are the Australian government department who are responsible for patents and trademarks. They were re-architecting their patent and trademark search systems and wanted to predict how well they would perform and how many users they could support for a realistic mix of search types. The majority of searches were “simple”, so they were fast and didn’t consume many resources, however, there were some more complex searches that were slower and more resource hungry.
After 9 hours and 96 Chapters of online videos, plus several days of hands-on exercises, I had 30 plus pages of handwritten notes, lots of things that I learned about Elasticsearch that I didn’t know to start with, and still more questions. In the rest of this article, I’ll focus on some of the basic things that I learned (section 3), and also some more interesting computational linguistic things (section 4).
3.What Did I Learn About Elasticsearch? The Basics
In this section, we cover the basics of Elasticsearch, including The Elasticsearch API, other ways of using Elasticsearch, Kibana, Documents, Indexing, Mappings, Reindexing, and Conflicts.
3.1 What Sort of API Does Elasticsearch Have?
A REST API (HTTP + JSON).
3.2 Are There Other Ways of Using Elasticsearch?
Yes! There’s a simple URI request query without a JSON body. However, you do have to worry about encoding special characters correctly.
There are also programming language clients—here’s an example using Java, and here’s how to use the high-level Java REST client.
About half of the course used Kibana; this is a cool GUI that enables you to create searches visually, and JSON is generated as well so you can inspect the JSON and edit it, etc. It’s also used to graph search results. You can use Kibana with the Instaclustr managed Elasticsearch.
Another way of interacting with Elasticsearch is the Elasticsearch SQL, although this has some limitations (e.g. for queries and aggregations only).
3.3 What Is a Document?
“A document in madness! Thoughts and remembrance fitted.”
[Hamlet, IV, 5]
Elasticsearch searches documents. But what is a document? Basically, an Elasticsearch document is a JSON object which is stored and indexed in Elasticsearch. Each document is stored in at least one index and can be searched in many different ways.
How big can/should a document be? The default maximum size is 100MB, and the absolute maximum is 2GB (the Lucene limit). The real problem with large documents is that when you do a search, the result is just a list of documents. It’s probably not very useful knowing that the word “duck” appears somewhere (but where?) in a single large document. For example, in “The Complete Works of William Shakespeare”, the word “Duck”, or a variant, appears 16 times. So how small should a document be? As small as a single word? Possible – in theory.
For Shakespeare, a sensible granularity may be one document per line (or speech perhaps?). Then you want to ensure that each line of the play has meta-data including which play it’s in, who’s speaking, the line number, etc., so that when the results are returned you have sufficient context for the document.

(Source: Wikipedia)
Another challenge to searching the original Shakespeare text is the Elizabethan spelling (not to mention spelling variations, archaic words, or words that have changed their meaning etc.) This is the actual wording on the “To the Reader” page above:
This Figure, that thou here feest put,
It was for gentle Shakespeare cut:
Wherein the Grauer had a strife
with Naure, to out-doo the life:
O, could he but haue dravvne his vvit
As vvell in frasse, as he hath hit
Hisface; the Print vvould then surpasse
All, that vvas euer in frasse.
But, since he cannot, Reader, looke
Not on his picture, but his Booke.
Some of the language analysis and search techniques supported by Elasticsearch help solve this type of problem (but unfortunately probably won’t help to decipher my handwritten notes from the course), keep on reading to find out more.
3.4 How Are Documents Indexed?
“The presentation of but what I was; The flattering index of a direful pageant”
[Richard III, IV, 4]
Before you can search documents in Elasticsearch, they have to be indexed. In theory, you could search documents by scanning all of the documents, but this would be way too slow.
You can index documents either manually or dynamically (which I only discovered after the course). To manually index, you have to define mappings, then create an index, and finally add documents to the index. Using the dynamic way, you can just index a document and everything else is done for you by Elasticsearch. Elasticsearch just tries to guess the data types found in a document. Here’s some good documentation I found on dynamic mapping.
3.5 What Are Mappings?
“I am near to the place where they should meet, if Pisanio have mapped it truly.”
[Cymbeline, IV, 1]
Mappings are basically the index schema, and they map the fields in documents to Elasticsearch data types. Depending on the data type, the search semantics may differ. There are simple data types, complex data types (that support hierarchical JSON objects), geodata types, and more specialized data types.
String data can be mapped to either text or keyword types. What’s the difference?
Text is full-text searchable (and analyzed to create searchable index terms). Text isn’t used for sorting or aggregation.
Keywords are for strings that can only be searched by their exact value, but can be sorted, filtered, and aggregated (e.g. a postcode).
But what if you need both? You can have multi-fields using the fields parameter. For example, you may want the Shakespearean characters to be mapped as both text and keyword, to allow you to filter by a specific name (e.g. Lord Caputius), or search for all characters who have a particular title or rank (e.g. Lord or Captain etc.)
I found this the most surprising thing about Elasticsearch and still haven’t fully understood the subtleties, but this is a better explanation of the difference between Term-level vs full-text queries.
3.6 What Are the Steps for Indexing and Searching Documents?
“Tell her, we measure them by weary steps.”
[Love’s Labour’s Lost, V, 2]
The basic lifecycle of an Elasticsearch workflow consists of the following steps:
- Define mappings
- Create index
- Add documents to index
- Search the index to find documents
- (Try to) change mappings/number of primary shards, etc.
- Delete the index to start over!
Elasticsearch has a number of things that are immutable, and which can’t be easily changed after creating them:
1. Mappings
If you want to change the mappings for an index you can’t—you have to create a new index with the new mappings. In the course, this meant starting from scratch each time, which assumed you had all the documents still to add to the new index each time. After the course I found out you can reindex, i.e. you can move documents from one index to another index! You can also add mappings after index creation.
2. Primary Shards
You also can’t change the number of primary shards (used for writes), but you can add replica shards (used for reads).
3. Documents
Documents are also immutable. What happens if you want to update them? Simple! You get a new version.
3.7 How Does Elasticsearch Handle Concurrent Updates (Conflicts)?
“Who’s this? O God! it is my father’s face, Whom in this conflict I unwares have kill’d.”
[Henry VI, Part III, II, 5]
The next thing I learned about Elasticsearch is interesting, as it shows that Elasticsearch is more than “just” Lucene, and actually distributed—and it’s also something I knew about already.
What happens if you try to change (create, update, or delete) a document at the same time from multiple clients? This can cause a potential problem as Elasticsearch is intrinsically distributed, asynchronous, and concurrent! It also doesn’t support ACID transactions, and documents are immutable, so any changes result in a new version. So how can it prevent an older version of a document from overwriting a newer version?
Elasticsearch uses a well known mechanism from distributed databases called “optimistic concurrency control”. I first came across optimistic concurrency when trying to answer the question “How scalable is J2EE technology?”, and discovered it can also enable efficient cache utilization. Optimistic concurrency allows for higher concurrency, compared with “pessimistic” concurrency (which prevents conflicts by using locks), and “optimistically” assumes it has the most up to date version, but which may result in an exception if an inconsistency is eventually detected.
Elasticsearch uses sequence_number (which is different to version) and primary_term to identify changes. Here’s a Java example. You can set the retry_on_conflict to a non-zero value (the default is no retries) to get automatic retries up to a maximum value.
_____________________________________________________________________________
So now you’ve got an index, and some documents in the index. What can you do? Search! Search options are complex and include filters, queries, sorting, etc. However, many of these assume an exact match between the searched and indexed terms, so what happens if they don’t match exactly (inexact search)?
4. What Did I Learn About Elasticsearch? Inexact Searching
Several tricks from the multidisciplinary field of Computational Linguistics and the speciality of Computational Morphology (computational approaches to analyze the structure of words and parts of words) come to the rescue! They enable Elasticsearch to search for things that don’t exactly match (inexact matching), and include these techniques (with some cool names): Stemming, Lemmatization, Levenshtein Fuzzy Queries, N-grams, Slop and Partial Matching.
4.1 Stemming
“And stemming it with hearts of controversy;
But ere we could arrive the point proposed,
Caesar cried ‘Help me, Cassius, or I sink!’”
[Julius Caesar, I, 2]
This is where we could easily fall down the computational linguistics rabbit hole. Stemming is the process of reducing a word to its root or stem (which may not even be a word), e.g. “vac” (empty) is the root of both “evacuation” and “vacation”. Here’s an online dictionary of roots to give you an idea of how complex this is (given that English is derived from multiple other languages including Latin and Greek). Stemming sounds potentially painful! For example, here’s a flower stemming machine (it removes leaves, prickles, etc., leaving just the bare stem):

Why is stemming useful in text searching? Well, typically you want to find documents that contain different parts of speech of a root, or you may not even be using the root, and some roots aren’t words—e.g. “argu” is the root of “argue”, “argument”, etc.
Searching for “duck” in Shakespeare, you may want to return speeches which include all of these duck-like words, not only exact matches, i.e. all of the following words with duck appear: “a-ducking”, “wild-duck”, “silly-ducking”, “duck”, “ducks”, “Duck”, “Ducks”. Stemming uses simple purely syntactic methods to find a root (typically removing prefixes and suffixes) so would work correctly for this example.
Elasticsearch supports stemming, and other similar approaches to tokenizing words (e.g. lowercasing) using analyzers. You specify analyzers when you define mappings for an index, and you can have different analyzers for each field, or a default for the whole index. This online book has more on stemming.
4.2 Lemmatization
“Here, master doctor, in perplexity and doubtful dilemma.”
[Merry Wives of Windsor, IV, 5]
Given that finding the “Stem” of a word is called “Stemming”, then is finding the “Lemma” of a word called “Lemming”? No! It’s called Lemmatization (although a simple stemming approach would assume that both Stemming and Lemmatization have “Lemm” as the root!)

(Source: Wikipedia)
Lemmatization has the same goal as Stemming, but uses more sophisticated linguistic analysis, and finds a root that is a real word, so is better than Stemming. But this requires both a dictionary and potentially grammatical analysis to be 100% accurate. For example, stemming will not find the root of “better” and “best”, which is “good” (not “be” as a Stemmer may guess).
Any of the Elasticsearch stemming algorithms that use dictionaries are actually Lemmatization based approaches. There are some open source lemmatization plugins for Elasticsearch, e.g. LemmaGen, and a list of other open source lemmatizers.
4.3 Levenshtein Fuzzy Queries!
“The Prince is here at hand. Pleaseth your lordship
To meet his Grace just distance ‘tween our armies?”
[Henry IV, Part II, IV, 1]
From information theory, the Levenshtein (or, edit) distance is a metric for measuring the difference between two sequences—the minimum number of edits to change one sequence into the other. It’s similar to the better known Hamming distance, but is more general as it allows for deletions and insertions (as well as substitutions) so the sequences can be different lengths.
In Elasticsearch you use a fuzzy query, and you may need to set the “fuzziness” value. Options are either auto, which automatically determines the difference based on the word length, or manually set.
For example, the Muppet character, Fozzie Bear (who was definitely Fuzzy), has a fuzziness of 3 between the strings “Fuzzy” and “Fozzie”, i.e. (1) replace “u” with “o” giving “Fozzy”, (2) replace “y” with “i” giving “Fozzi”, (3) insert “e” giving “Fozzie”!
4.4 N-grams
“Be not thyself; for how art thou a king
But by fair sequence and succession?”
[Richard II, II, 1]
In computer science an n-gram is just a contiguous subset of a longer sequence. They are therefore applied to domains such as genetics as well as languages.
In Natural Language Processing n-grams are typically applied at the word level and are useful to predict what the next word is likely to be given an existing sequence and a Markov model or Bayesian probability. A well known example of n-grams at the word level is the Google Books Ngram Viewer. Here’s an example graphing the occurrence of n-grams “text search”, “natural language processing”, “index card”, “catalog card” in books from 1800 to the present day.
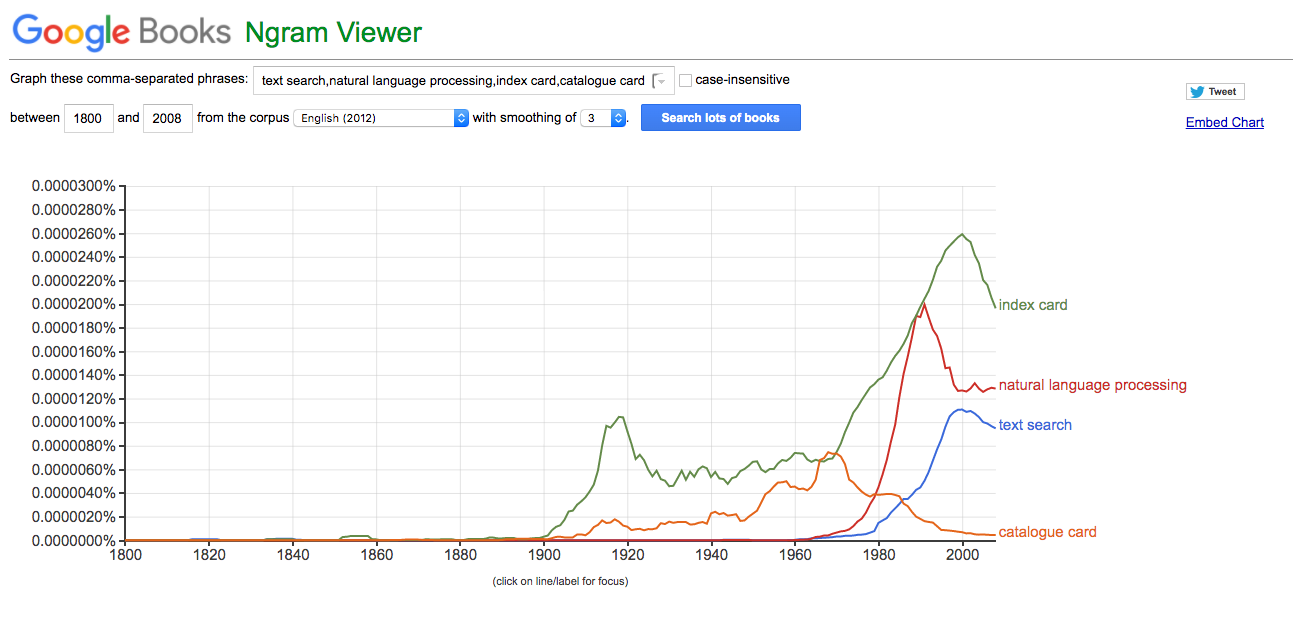
In Elasticsearch n-grams are used for efficient approximate matching, as they are computed at index time so are fast at search time, and match on partial words—use the ngram tokenizer. N-grams are also for autocompletion suggestions, using the edge_ngram tokenizer. The defaults are to compute a unigram and a bigram, but the min_gram and max_gram lengths can be customized.
How does this help match incorrectly spelled words? Because a longer list of n-gram terms is generated at index time, and the same ngram analyzer is applied to the search term, then a match occurs for any of the n-grams. For example, if we are looking for documents containing “duck” and have indexed them with bigrams, giving terms [du, uc, ck], then searching for “duk” will result in bigrams [du, uk], of which “du” matches indexed bigrams. The best explanation I’ve found is in “Elasticsearch in Action”. Here’s another good example of Elasticsearch n-grams.
Apparently “duk” is a correct spelling of “duck” if you are the “local” Canberra band “Peking Duk”!
4.5 Slop (dogs, and ducks)
“Signior Romeo, bon jour! There’s a French salutation to your French slop.”
[Romeo and Juliet, II, 4]
“Trust none;
For oaths are straws, men’s faiths are wafer-cakes,
And hold-fast is the only dog, my duck”
[Henry V, II, 3]

What if you want to search for documents with multiple terms occurring in order and “close” to each other? By default, the match phrase query only returns exact matches. You can specify a “slop” parameter to change the maximum distance the words can be apart (0 is no gap, 1 is 1 word in between, etc.).
The phrase “And hold-fast is the only dog my duck” in Shakespeare (above) would be found with a phrase query of “dog duck” with a slop of >= 1 but not 0. There are some good query examples in this article, including using slop.
4.6 Partial Matching With Prefix, Wildcards, and Regular Expression Queries
“O, they have lived long on the alms-basket of words.
I marvel thy master hath not eaten thee for a word;
for thou art not so long by the head as
honorificabilitudinitatibus: thou art easier
swallowed than a flap-dragon.”
[Love’s Labour’s Lost, V, 1]
If an analysis of the text doesn’t result in indexed tokens that are sensible to search for exactly, or if you don’t expect users to be able to remember long words, another option is to use partial matching, either by prefix, wildcards, or regular expressions.
For example, if you want to find the word “Honorificabilitudinitatibus” (the longest word in Shakespeare, meaning “the state of being able to achieve honors”), then a prefix query of “Honor” will find it (and fast).
Wildcard queries allow pattern matching (on simple patterns) using “?” for any single character and “*” for 0 or more characters. So a wildcard query of “Honour*” will also find our longest word. In theory, you could also find “Honorificabilitudinitatibus” using a Wildcard query of “*bus”, but this may be slow!
More general pattern matching is supported with the regular expression query (regexp), but also may be slow depending on the exact pattern. Here’s the regular expression syntax.
So it turns out I did know something about Elasticsearch after all. I’ve previously used the Lucene prefix search in my “Geospatial Anomaly Detection: Part 4 – Cassandra Lucene” blog, and it turned out to be one of the fastest Lucene queries for geospatial searching (using a geohash) that I experimented with.
5. Postscript: Morphology
“I leave myself, my friends and all, for love.
Thou, Julia, thou hast metamorphosed me”
[Two Gentlemen of Verona, I, 1]
(Source: ESA/Hubble)
It turns out I did know something about Morphology (“the study of the shape of things”) after all! In Linguistics, morphology includes stemming, lemmatization, etc. hidden in Appendix B in the final pages in Terry Winograd’s “Syntax” book was a discussion on morphology and why it was hard to do with a rules based approach.
Obviously I didn’t get to the end of the book! If I had, I would have learned that the stem of the longest word in the English language, “antidisestablishmentarianism”, is “establish” (which can be found by the simpler stemming algorithms), and may have been less surprised by some of the powerful Elasticsearch inexact matching features.
_____________________________________________________________________________
So that’s it from my Elasticsearch Test Drive. I only covered what I found particularly interesting from the course, so it’s not an exhaustive introduction to Elasticsearch, and it omits much of the course material that dealt with the relatively complicated aspects of Elasticsearch clustering and operations.
If you use Instaclustr’s Managed Elasticsearch you don’t need to worry about much of this at all, although there are a few things you still need to consider including what size nodes to use, how many nodes of each type are needed in your cluster, and how many primary and replica shards, etc.
In fact, I still had lots of unanswered questions after completing the course, so I decided to send my questions to one of Instaclustr’s Elasticsearch gurus to see what he would make of them. Here are the answers (Elasticsearch Q&A Part 1, Elasticsearch Q&A Part 2).
After learning Elasticsearch earlier in the year, I finally got around to using it in practice to build a real-time Apache Kafka, Kafka Connect, Elasticsearch, and Kibana pipeline to process public domain (machine, rather than natural language) tidal data, and graph and map it in Kibana. Along the way I learned more about Elasticsearch mappings and scalability, and Kibana graphing and using custom maps. See the five part blog series: “Building a Real-Time Tide Data Processing Pipeline—using Apache Kafka, Kafka Connect, Elasticsearch, and Kibana”.
So, for now I’ll leave the last word to Shakespeare:
“The search, sir, was profitable”
[All’s Well that Ends Well, IV, 3]
6. Further Resources
Elasticsearch is a mature technology so there’s lots of documentation around, although I found that much of it is out of date, or for proprietary versions. Some of the Lucene documentation is also relevant. Here’s a list of resources that I found useful, and some other articles that I’ve written on similar topics:
- Open Distro for Elasticsearch Here’s the best place to go for Open Distro for Elasticsearch Documentation, which has some good introductory Elasticsearch documentation.
- Lucene documentation is at Apache Lucene 7.4.0 Documentation.
- Relevant Search This is a good book from Manning, and a free chapter from the book.
- 23 Useful Elasticsearch Example Queries, the title says it all!
- Terry Winograd, Language as a cognitive process: Volume 1: Syntax, 1983, http://repository.ubvu.vu.nl/e-syllabi/Language_as_a_cognitive_process.pdf
- Encyclopedia of Language and Linguistics, this chapter covers the history of document search.
- Open Source Shakespeare https://www.opensourceshakespeare.org/, where I searched for, and found, quotes.
- Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. 2008. https://nlp.stanford.edu/IR-book/
- Steven Bird, Ewan Klein, and Edward Loper, Natural Language Processing with Python – Analyzing Text with the Natural Language Toolkit, 1st Ed. 2009, https://www.nltk.org/book/
- Paul Brebner, “Geospatial Anomaly Detection (Terra-Locus Anomalia Machina) Part 4: Cassandra, meet Lucene—The Cassandra Lucene Index Plugin”, 2019.
- Paul Brebner, “Building a real-time Tide Data Processing Pipeline – using Apache Kafka, Kafka Connect, Elasticsearch and Kibana”, 5 part blog series, 2020.
- Paul Brebner and Mussa Shirazi, “Taking Elasticsearch to the Mechanics: Under the Hood Q&A”, 2020.
- Paul Brebner and Mussa Shirazi, “Taking Elasticsearch for a Spin around the race track Q&A”, 2020.
- Instaclustr, Understanding Elasticsearch Whitepaper.
- Instaclustr, online/virtual Elasticsearch webinars (under on-demand).
You can also try out Instaclustr’s Managed Elasticsearch