






















![]()
![]()
Spark Jobserver
Spark Jobserver provides the ability to upload and initiate Spark jobs on your cluster via http and https, eliminating the need to install Spark on your workstation and simplifying network configuration. See the step-by-step tutorial here.
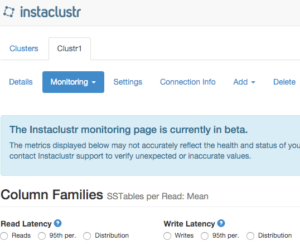
Column family level monitoring in our console and API
The monitoring view directly in our console now provides access to the key column-family level statistics you need to monitor the performance of your application. This includes information on read and write volumes, latency, tombstones and sstables per read. This same information is also available through the monitoring REST API. This is still just that start for our monitoring capability so keep an eye out for future enhancements.

Automatically configuring firewalls rules when configuring VPC peering
We’ve made a few changes recently to make configuring AWS VPC peering simpler and more reliable. This change means that, by default, the network range of the peer VPC will be allowed to access the services running on the cluster. If this doesn’t suite your use case, it’s simply a matter of unchecking the option and then manual adding the specific rules you need.
![]()
![]()
Automated repair enhancements
We’ve made a number of improvements to our tooling that automatically runs repairs across each cluster every week. One of these was to enable incremental repairs for 2.1-based cluster. We’ve also implemented the ability to exclude individual keyspaces from a repair. This is useful if you have a keyspace with short-lived data or low priority on consistency and want to avoid the expense of running repairs. For example, we have disabled repairs for the raw event data in our monitoring database but have them enabled for summary roll-ups. If you would like repairs disabled for one of your keyspaces the contact [email protected].