At Current London recently, I was able to jump the queue (a thing you should never really do) with a new Kafka 4.0 feature that has been on my radar for a while, KIP-932: Queues for Kafka. It was highly appropriate to learn about Kafka Queues in London, as queuing is very British! So, if you would like to join (but not jump) the queue for Apache Kafka share groups, read on!
Here’s the very short version! KIP-932 introduces a new type of Kafka group, Share Groups. Compared to normal Kafka consumer groups, these are pretty weird—they allow more Consumers (in a group) than Partitions and consume records “cooperatively” based on record availability without the constraint of partition-consumer mappings. This is good for use cases more typical of traditional queue-based systems, including:
- Scaling consumers for peaks (consumers > partitions during peak conditions), and
- Scaling for slow consumers, enabling a pool of consumers to handle each message separately, thereby reducing the end-to-end processing latency.
Sounds simple! And it is, conceptually at least. But this introduction is an oversimplification, and KIP-932 is a work in progress—it’s early access and must be enabled in Kafka 4.0. Plus, there’s a bit more going on “behind the abstraction” in practice.
Kafka Queues—Behind the abstraction
Let’s go behind the Kafka Queue abstraction and understand more about how they work in practice. Here are a few more details about Kafka Share groups that I discovered from the Current London talk and from the KIP itself.
Previous Kafka consumer group protocols (classic and consumer, see my recent blog on KIP-848) provide a balance of ordering and scalability and limit the number of consumers in a group to strictly less than or equal to the number of partitions. To increase consumers to increase throughput, you must increase partitions (or use a multi-threaded consumer).
Currently, exactly one consumer is assigned to each topic partition—this ensures ordering per partition. This is good for scalable stream processing where topic-partition order matters.
But more traditional event style use cases are possible. For example:
- Where ordering doesn’t matter (as much), and
- Events can be processed independently and concurrently by a pool of consumers
- Based on demand/availability rather than the strict 1-1 mapping between consumers and partitions.
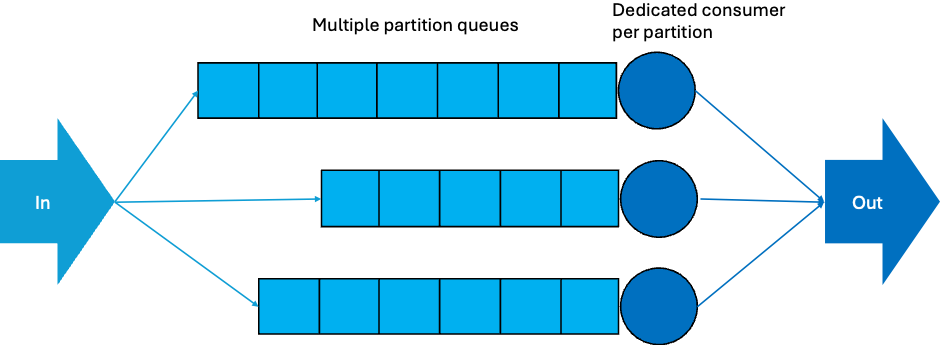
These two approaches can be illustrated by multiple-line and single-line queue systems.
For example, consider two types of “queuing” in a shop or event: single lines (with pooled workers) and multiple lines (with dedicated workers).
The current Kafka default partition-based consumer group is like having multiple queues, one queue for each partition, with a dedicated consumer processing the records from each partition. The order of processing is therefore guaranteed to be correct per partition. What are some problems? You can only have as many queues as partitions, and no more, so you can’t increase scalability/throughput without increasing partitions and reorganising the queues, which takes time/effort; and records may get stuck in a slow queue or behind slower records—there may be more records in your partition, or some records may take longer to process than others, so the progress (or length as shown here) of each queue may be variable.
Another model is a single line with pooled consumers. Once a record gets to the head of the queue, they are allocated to a consumer that has spare capacity available. This is technically the most efficient type of queuing system and is optimised for “fairness” (everyone is served strictly in order) with reduced latency and variability. However, the queue is more “complex” and longer—it feels slower for customers waiting in the serpentine queue (typically a long winding queue, at least in the real world—this article on queue design starts off with a nice example of a serpentine queue). And for physical systems at least, people may “balk” at joining the queue if it appears to be too long, and it can take up too much space and require management (e.g. to stop queue jumpers!).
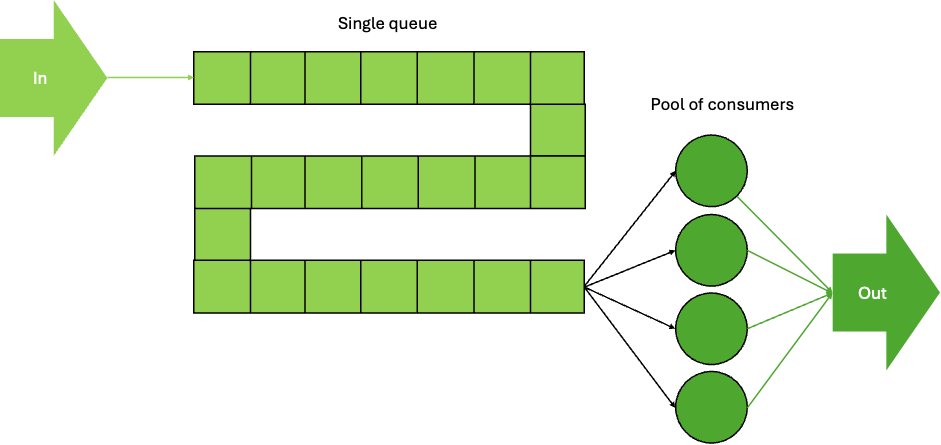
Note that this is still a simplification of Kafka queues—there are still partitions—but consumers get the next available record irrespective of partitions. And the improved diagram is also a simplification—consumers poll and receive batches of records, so there is also queuing inside consumers (see the next blog for a discussion of this aspect).
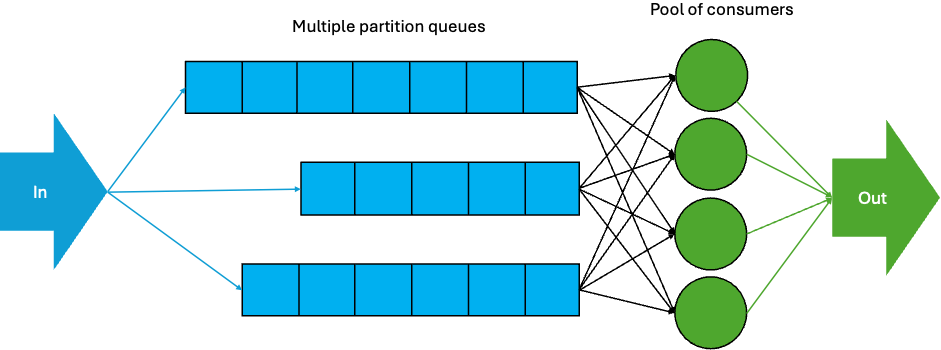
The last diagram illustrates the new share groups – the new “queuing” mechanism in Kafka 4.0. They allow consumers in a share group to work together to process records from topic-partitions as fast as possible. They are a good alternative to consumer groups when finer-grained sharing of records is required, with less strict ordering, or even no ordering.
Consumers in a share group consume records from topic-partitions that may be assigned to multiple consumers. This allows for the number of consumers to exceed the number of partitions. Records are conceptually processed (and acknowledged) individually but can be batched for efficiency. Record delivery guarantees are “at least once”.
In Kafka 4.0, there are now three consumer group types: classic, consumer, and share. Share groups work as usual with other group types (or other share groups) on the same topic-partitions.
Unlike typical queuing systems, there is no maximum queue depth; instead, there is a limit to the number of records in flight (group.share.partition.max.count).
Share groups are built on KIP-848: The New Generation of the Consumer Rebalance Protocol. The group coordinator manages the coordination of share groups (as well as consumer groups). Rebalances are less significant for share groups, mainly because partitions may be shared across multiple consumers in the same share group, making rebalancing trivial.
There is a new assignor, org.apache.kafka.coordinator.group.share.SimpleAssignor, which is responsible for balancing available consumers across all partitions – with the important difference that partitions can be shared across consumers (hence the name). Share groups share the same namespace as consumer groups in a Kafka cluster.
But share groups may not work well (yet) for “big” groups. Currently, the default maximum number of consumers in a share group is 200, with 1,000 maximum. Some other new configurations and defaults include:
- delivery count limit = 5,
- record lock duration = 30s,
- max in-flight records per share partition (actually called
group.share.partition.max.record.lock) = 200- (But 2,000 in the KIP and it will be 2,000 in 4.1).
More or less order?
Oddly enough, for a more explicitly queue system, there is less order compared with the previous classic/consumer approaches. This is because share groups are designed to allow consumers to be scaled independently of partitions. The records in a share-partition (a topic-partition in a share group) can be delivered out of order to a consumer—in particular, when there are timeouts/errors and redelivery occurs. What ordering is still guaranteed? The records returned in a batch for a share-partition are guaranteed to be in order—this is partial ordering only. But there are no guarantees about the ordering between different batches, or for errors and redelivery.
There are two different ways for consumers to manages offset commits for processed messages: Implicit vs. Explicit Acks. Implicit is the default and allow automatic acknowledgment on the next poll() call. Explicit acknowledgement enables more fine-grained control over which records are considered processed vs. failed. There’s very good documentation and code examples for both approaches in the Kafka documentation.
How to enable Kafka Queues in Kafka 4.0?
In Kafka 4.0, Queues must be enabled in the server configuration file as described in the KIP-932 early access release notes. You need to add these 2 lines to the config/server.properties file before starting Kafka:
|
1 2 |
unstable.api.versions.enable=true group.coordinator.rebalance.protocols=classic,consumer,share |
But watch out! There are also warnings that reinforce that it’s not for production and is not upgradeable! It’s just for testing in 4.0.
You can easily test it out using a local copy of Apache Kafka 4.0 and the Kafka CLI commands. There’s a new kafka-console-share-consumer.sh command, with all running instances part of the same share group. If (as described in more detail in the release notes) you create a test topic with 1 partition, and create 2 kafka-console-share-consumer instances, and send records to the test topic (“Q”), you will see that (a) more consumers than partitions are supported by share groups (2 consumers for 1 partition in this case), and (b) the records are randomly consumed by both consumers.
You can easily try a Java Kafka consumer as well. Here’s an example. Note that you don’t specify a different type of group.protocol, but you use a new constructor, KafkaShareConsumer().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import java.time.Duration; import java.util.List; import java.util.Properties; import org.apache.kafka.clients.consumer.KafkaShareConsumer; public class Q_Test { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "q-group"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // Create the Kafka share consumer KafkaShareConsumer<String, String> consumer = new KafkaShareConsumer<>(props); // Subscribe to topics consumer.subscribe(List.of("Q")); // Poll for records while (true) { var records = consumer.poll(Duration.ofMillis(100)); for (var record : records) { System.out.printf("Consumed record with key %s and value %s and partition %s%n", record.key(), record.value(), record.partition()); } } } } |
You also need this in your pom.xml file:
|
1 2 3 4 5 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>4.0.0</version> </dependency> |
Future Kafka Queues
What does the future of Kafka Queues hold? Potential enhancements may include key-based ordering (c.f. the parallel consumer), so that partial ordering over keys and fine-grained sharing can both be achieved, support for exactly-once semantics (EOS), dead letter queues, retry delays with backoffs, rack-aware assignments, and maybe even eventually the removal of partitions! Kafka 4.1 will be the preview version, and eventually 4.2 for GA (target November 2025).
In part 2 of this blog series, we’ll take a closer look at some Kafka Share Group Use Cases.
Interested in exploring Kafka Queues yourself? You can try them on the Instaclustr Managed Platform by spinning up a free, 30-day, no obligation Apache Kafka 4.0 trial cluster, and then creating a support ticket for TechOps to enable KIP-932, and test the feature in a controlled environment. But remember, it’s for testing only and not upgradeable to 4.1.