What is Apache Spark?
Apache Spark is an open-source, unified analytics engine for large-scale data processing. It was developed at UC Berkeley’s AMPLab and quickly gained traction due to its capabilities in handling big data. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. It performs both batch processing (similar to MapReduce) and new workloads like streaming, interactive queries, and machine learning.
One of Spark’s major strengths is its ability to process data in memory, drastically reducing the time for data processing jobs. It supports multiple programming languages, including Java, Scala, Python, and R, making it versatile for developers with different skills. With built-in modules for streaming, SQL, machine learning, and graph processing, Apache Spark fits well into many data workflows.
Editor’s note: Updated to reflect Apache Spark version 4.
This is part of a series of articles about Apache Spark
How does Apache Spark work
Apache Spark operates using a master-slave architecture. The master node, known as the driver, manages the overall execution of the application. It distributes tasks to worker nodes, which execute the tasks and return results to the driver.
Here is a step-by-step breakdown of how Spark processes data:
- SparkContext initialization: When a Spark application starts, it initializes a
SparkContext, which acts as the gateway to all Spark functionalities. This context connects to the cluster manager, which can be Hadoop YARN, Apache Mesos, or the standalone Spark cluster manager. - RDD creation: Spark applications operate on resilient distributed datasets (RDDs). RDDs are immutable collections of objects that can be processed in parallel. They can be created from Hadoop InputFormats (such as HDFS files) or by transforming other RDDs.
- Transformations and actions: Operations on RDDs fall into two categories: transformations and actions. Transformations, like
mapandfilter, define a new RDD from an existing one and are lazily evaluated, meaning they do not execute until an action is called. Actions, likecountandcollect, trigger the execution of the transformations and return a result to the driver. - Directed acyclic graph (DAG): When an action is called, Spark constructs a directed acyclic graph (DAG) of stages to perform the requested computations. The DAG scheduler then splits the graph into stages of tasks based on data shuffling requirements and submits these stages to the task scheduler.
- Task execution: The task scheduler distributes tasks across the worker nodes. Each worker node processes its tasks and stores the intermediate data in memory or disk, depending on the operations being performed and the available memory. Spark’s in-memory processing capability significantly improves performance for iterative algorithms.
- Fault tolerance: Spark achieves fault tolerance through RDD lineage. Each RDD keeps track of the series of transformations used to build it. If a partition of an RDD is lost, Spark can recompute it from the original data using this lineage information.
- Resource management: The cluster manager allocates resources to the Spark application based on the defined configurations. Spark can dynamically adjust the resources needed for different stages of execution, optimizing resource utilization.
Learn more in our detailed guide to the architecture of Apache Spark
Spark core components and ecosystem
Apache Spark is more than a processing engine—it includes a rich ecosystem of libraries that extend its capabilities across multiple data workloads. These components integrate seamlessly and share the same underlying execution engine.
- Spark Core: This is the foundation of the Spark platform. It provides task scheduling, memory management, fault recovery, and interaction with storage systems. RDDs originate here, and all higher-level libraries are built on top of Spark Core.
- Spark SQL and DataFrames: Spark SQL enables structured data processing using SQL queries and the DataFrame/Dataset APIs. It allows integration with Hive, Parquet, JSON, JDBC sources, and more. The Catalyst optimizer improves performance by optimizing query plans automatically.
- Structured Streaming: Structured Streaming builds on Spark SQL to provide scalable and fault-tolerant stream processing. It treats streaming data as an unbounded table, allowing developers to reuse batch processing logic in streaming applications.
- MLlib: MLlib is Spark’s distributed machine learning library. It includes algorithms for classification, regression, clustering, recommendation systems, and feature engineering, all designed to scale across clusters.
- GraphX: GraphX provides APIs for graph processing and graph-parallel computation. It is useful for analyzing relationships in data such as social networks, fraud detection systems, and recommendation engines.
Apache Spark command cheat sheet
Let’s briefly review the most important Spark commands.
Spark Shell commands
| Command | Description |
spark-shell |
Starts the Spark Shell in Scala. This is an interactive environment for running Spark commands. |
pyspark |
Starts the Spark Shell in Python. Useful for writing Spark applications using Python. |
sc.version |
Displays the version of Spark running in the shell. |
sc.appName |
Returns the name of the current application. |
sc.master |
Shows the master URL to which the Spark application is connected. |
sc.stop() |
Stops the SparkContext, effectively ending the Spark application. You will get a deprecation warning. |
:quit |
Exits the Spark Shell. |
RDD transformations
| Transformation | Description |
map(func) |
Returns a new RDD by applying a function to each element of the source RDD. |
filter(func) |
Returns a new RDD containing only the elements that satisfy a given condition. |
flatMap(func) |
Similar to map, but each input item can be mapped to multiple output items (e.g., by splitting sentences into words). |
distinct() |
Returns a new RDD containing distinct elements of the source RDD. |
union(otherRDD) |
Merges the content of two RDDs and returns a new RDD. |
intersection(otherRDD) |
Returns an RDD that contains only the common elements between two RDDs. |
groupByKey() |
Groups the data by key and returns a new RDD of (key, iterable) pairs. |
join(otherRDD) |
Joins two RDDs by their keys and returns an RDD of (key, (value1, value2)) pairs. |
Actions
| Action | Description |
collect() |
Returns all the elements of the RDD as an array to the driver program. |
count() |
Counts the number of elements in the RDD and returns the result to the driver. |
take(n) |
Returns the first n elements of the RDD. |
reduce(func) |
Aggregates the elements of the RDD using a specified binary function. |
saveAsTextFile(path) |
Saves the contents of the RDD to a text file at the specified path. |
countByKey() |
Counts the number of elements for each key in a pair RDD and returns the count to the driver. |
foreach(func) |
Applies a function to each element of the RDD. This is often used for side effects such as updating an accumulator variable or interacting with external storage. |
Learn more in our detailed guide to Apache Spark streaming
Tips from the expert

Hichem Kenniche
Senior Product Architect
In my experience, here are tips that can help you better utilize Apache Spark for your big data processing needs:
- Use Kryo serialization for better performance: Default Java serialization is often slow and space-consuming. Kryo serialization is faster and more memory-efficient, especially for complex data structures. In your Spark configuration, set your
spark.serializertoorg.apache.spark.serializer.KryoSerializer. - Monitor and tune Spark’s memory management: Spark’s in-memory processing capabilities require careful memory management to balance between execution and storage memory. Regularly monitor JVM heap memory usage and adjust these settings based on your application’s need.
- Avoid using expensive operations on narrow dependencies: Minimize using operations like
groupByKey, which can be costly and result in large shuffles. Instead, opt forreduceByKeyoraggregateByKey, which combine values locally before sending them across the network, significantly improving performance. - Exploit data locality in Spark jobs: Data locality, or placing tasks close to the data they process, significantly reduces network I/O. Ensure your Spark jobs are scheduled with data locality in mind by configuring the cluster appropriately and monitoring data placement.
- Profile and debug with the Spark UI: The Spark UI is an invaluable tool for profiling and debugging your applications. Regularly check the stages, tasks, and executors tabs to identify bottlenecks, memory issues, or data skew in your jobs. Adjust configurations or code based on insights gathered here.
Tutorial: Running your first Python Apache Spark application
Download and Install Apache Spark
To get started with Apache Spark, you first need to download and install it. Follow these steps:
1. Download Spark: Visit the Apache Spark downloads page to download Spark. You can choose pre-packaged versions for popular Hadoop distributions or a Hadoop-free binary, allowing you to use any Hadoop version by modifying Spark’s classpath.
|
1 2 |
wget https://archive.apache.org/dist/spark/spark-4.1.1/spark-4.1.1-bin-hadoop3.tgz tar -xvf spark-4.1.1-bin-hadoop3.tgz |
2. System requirements: Spark runs on both Windows and UNIX-like systems (Linux, Mac OS) and requires a supported Java version (8, 11, or 17). Ensure Java is installed and accessible via PATH or set the JAVA_HOME environment variable to your Java installation.
|
1 |
java -version |
Note: If Java is not found, please install the compatible version.
3. Install PySpark: For Python users, PySpark can be installed directly from PyPI.
|
1 |
pip3 install pyspark |
4. Using Docker: Alternatively, you can use Docker to run Spark. Official Spark images are available on Dockerhub. This method is useful for avoiding dependency issues.
|
1 |
docker pull apache/spark:4.1.1 |
These steps will set up Apache Spark on your machine, allowing you to run Spark locally. Ensure all dependencies are correctly configured, especially the Java version and paths, to avoid runtime issues.
Interactive Analysis with the Spark Shell
Spark’s shell is a tool for interactive data analysis, providing a way to learn the API and analyze data. It is available in Scala and Python, allowing you to leverage existing Java libraries or work with Python’s dynamic capabilities.
To start the Spark shell, navigate to the Spark directory and run:
|
1 |
./bin/pyspark |
If PySpark is installed via pip, simply run:
|
1 |
pyspark |
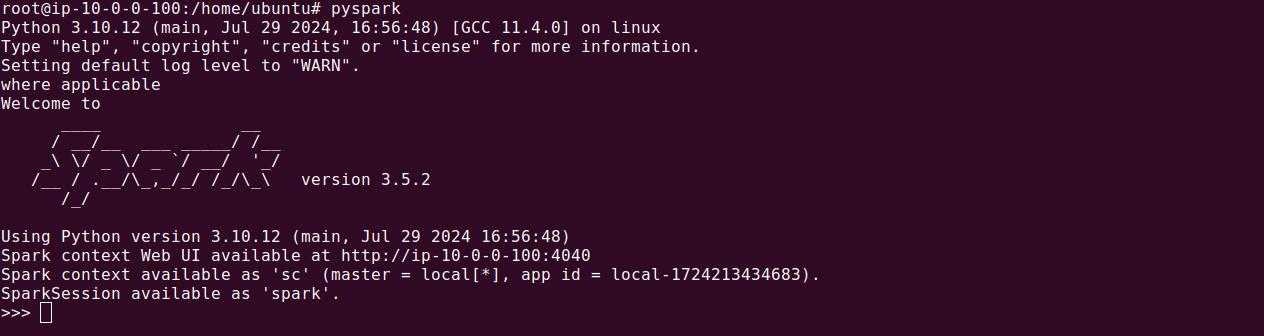
Spark’s primary abstraction is a distributed collection of items called a Dataset. In Python, all Datasets are referred to as DataFrames, similar to data frames in Pandas and R. To create a new DataFrame from the README file in the Spark source directory, use the following commands:
|
1 |
textFile = spark.read.text("README.md") |
Note: A sample README.md document can be downloaded from here.
You can perform various actions and transformations on DataFrames. For instance, to count the number of rows in the DataFrame:
|
1 |
textFile.count() |
To retrieve the first row:
|
1 |
textFile.first() |
To filter lines containing the word “Data” and count them:
|
1 2 |
linesWithSpark = textFile.filter(textFile.value.contains("LangChain")) linesWithSpark.count() |
Note: The filter is case sensitive.

For more complex computations, like finding the line with the most words, use the following:
|
1 2 |
from pyspark.sql import functions as sf textFile.select(sf.size(sf.split(textFile.value, "\s+")).name("numWords")).agg(sf.max(sf.col("numWords"))).collect() |

This maps each line to an integer value representing the word count and finds the line with the maximum number of words.
To implement a MapReduce flow and count word occurrences:
|
1 2 |
wordCounts = textFile.select(sf.explode(sf.split(textFile.value, "\s+")).alias("word")).groupBy("word").count() wordCounts.collect() |
You can cache datasets for repeated access, which is useful for querying small datasets or running iterative algorithms:
|
1 2 |
linesWithSpark.cache() linesWithSpark.count() |
Creating a Self-Contained Spark Application
Creating a self-contained Spark application involves writing code using the Spark API. Here’s an example of a simple Spark application in Python:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
from pyspark.sql import SparkSession import re # Initialize Spark session spark = SparkSession.builder.appName("ExtractLinksFromMarkdown").getOrCreate() # Path to the README.md file file_path = "README.md" # Read the file into an RDD markdown_rdd = spark.sparkContext.textFile(file_path) # Define a function to extract links and descriptions using regex def extract_links(line): # Regex pattern to find markdown links in the format [description](link) pattern = re.compile(r'\[(.*?)\]\((.*?)\)') matches = pattern.findall(line) return [(match[0], match[1]) for match in matches] if matches else [] # Apply the function to each line and filter out empty results links_rdd = markdown_rdd.flatMap(extract_links).filter(lambda x: x) # Convert the RDD to a DataFrame links_df = links_rdd.toDF(["description", "link"]) # Show the extracted links and descriptions links_df.show(truncate=False) # Optionally, save the DataFrame to a CSV or another format # links_df.write.csv("output/links.csv", header=True) # Stop the Spark session spark.stop() |
To run this application, replace YOUR_SPARK_HOME with your Spark installation directory and use the spark-submit script:
|
1 |
YOUR_SPARK_HOME/bin/spark-submit --master local[4] SimpleApp.py |
Alternatively, if PySpark is installed via pip, you can run the application using the Python interpreter:
|
1 |
python SimpleApp.py |
This program retrieves the document links and link text in a text file, demonstrating basic operations in a Spark application. For more complex applications, dependencies can be managed using tools like Conda or pip, and custom classes or third-party libraries can be added using –py-files argument in spark-submit.
Deploying Your Application on a Spark Cluster
Deploying your Apache Spark application on a cluster involves several steps, which can vary depending on the cluster manager you are using (e.g., Standalone, YARN, or Mesos).
In this tutorial, we’ll walk through the process of deploying a simple word count application on a Spark cluster using the spark-submit command. This example assumes you have a Spark cluster set up and ready to receive jobs.
Prepare the Application
We will use the above example in Python that retrieves the list of http links and description from README.md file. simple word count example similar to the one we explored earlier. The application is written in Scala and is contained in the SimpleLinkExtractor.scala file. Here’s the core part of the application:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import org.apache.spark.{SparkConf, SparkContext} import scala.util.matching.Regex object SimpleLinkExtractor { def main(args: Array[String]): Unit = { // Initialize Spark context val conf = new SparkConf().setAppName("ExtractLinksFromMarkdown") val sc = new SparkContext(conf) // Path to the README.md file val filePath = "README.md" // Read the file into an RDD val markdownRDD = sc.textFile(filePath) // Define a function to extract links and descriptions using regex def extractLinks(line: String): Seq[(String, String)] = { // Regex pattern to find markdown links in the format [description](link) val pattern: Regex = """\[(.*?)\]\((.*?)\)""".r pattern.findAllMatchIn(line).map { m => (m.group(1), m.group(2)) }.toSeq } // Apply the function to each line and filter out empty results val linksRDD = markdownRDD.flatMap(extractLinks).filter(_._1.nonEmpty) // Convert the RDD to a DataFrame-like structure (in Spark 1.x, you need to use RDD operations) linksRDD.foreach { case (description, link) => println(s"Description: $description, Link: $link") } // Stop the Spark context sc.stop() } } |
Compile the Application
Before submitting the application, it must be compiled into a JAR file. Use the following command to compile the Scala file:
|
1 2 |
CP="$(ls -1 $SPARK_HOME/jars/*.jar | paste -sd: -)" scalac -classpath "$CP" SimpleLinkExtractor.scala |
This command compiles SimpleLinkExtractor.scala into bytecode that can be run by the JVM.

Note: You will need to download the JAR file(s) in order to successfully compile the code.
Create a JAR File
Once the application is compiled, package the compiled class files into a JAR file. The following command creates a JAR file named wordcount.jar:
|
1 |
jar -cvf SimpleLinkExtractor.jar SimpleLinkExtractor*.class |
Submit the Application to the Cluster
With the JAR file ready, you can submit the application to the Spark cluster using the spark-submit command. The command below submits the word count application:
|
1 |
spark-submit --class SimpleLinkExtractor --master local SimpleLinkExtractor.jar |
Replace “local” with the appropriate cluster manager URL if you’re deploying to a real cluster.
After successful execution, the output should be similar to the below:
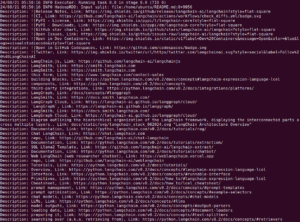
Learn more about open source databases.
Simplifying big data processing and machine learning: Support for Apache Spark
Simplify your big data processing and machine learning operations with Ocean for Apache Spark. Our powerful framework is designed to enhance your experience with Apache Spark, making it easier for your organization to leverage the full potential of this widely adopted open-source framework.
With Ocean, you get a high-level API that offers an intuitive and concise way to interact with Spark. This not only simplifies the development process but also increases productivity by allowing you to write Spark applications with less code. Whether you’re performing data aggregations, joining datasets, or applying machine learning algorithms, our solution makes the process straightforward and efficient.
We also provide a suite of tools that streamline the development, deployment, and management of Spark applications. These include a built-in data catalog for easy discovery and access to datasets, eliminating manual management. On top of that, our visual interface facilitates monitoring and managing your Spark applications, providing real-time insights into job performance, resource usage, and debugging information.
Ready to take your Apache Spark operations to the next level? Explore support Ocean for Apache Spark today and experience the simplicity and efficiency of our powerful framework.
For more information: