On September 26, 2024, the PostgreSQL Global Development Group dropped PostgreSQL 17—the latest milestone in the journey of the world’s most advanced open source database. Whether you’re a developer crafting cutting-edge applications or a DBA optimizing mission-critical systems, this release was packed with features that made your life easier, your queries faster, and your data management more powerful than ever. Curious about what’s in there? Buckle up as we dive into the highlights of PostgreSQL 17 that redefined how you work with data.
While PostgreSQL 18 released on September 25, 2025, we’re going to reflect on a year of PostgreSQL 17 and what it has meant.
Imagine slashing backup times for massive databases, transforming JSON data into relational tables with a single command, or seamlessly managing high-availability setups without breaking a sweat. PostgreSQL 17 delivers all this and more, with performance boosts, developer-friendly tools, and enterprise-grade enhancements that cement its reputation as the go-to database for modern workloads. In this blog, we’ll explore the standout features—like incremental backups, enhanced SQL/JSON support, and logical replication improvements—that make this release a must-know for anyone serious about data. Ready to discover how PostgreSQL 17 can supercharge your projects? Let’s get started!
How PostgreSQL 17 changed the production experience
When discussing the impact of PostgreSQL 17, our team’s conversation shifted quickly from “what’s new?” to “what immediately felt different?” For us, several improvements stood out:
- Advancements in logical replication control on failover. We could leverage schema-level logical replication to streamline processes that previously required heavy scripting and extensions. This advancement made our upgrade plans cleaner with reduced risk.
- Noticeable performance wins. The natural benefits from planner and executor optimizations became obvious.
- Sharper incremental sorts. Support to incremental sorts with
GiSTandSP-GiSTis incredible. Analytical queries previously overwhelming memory resources suddenly stabilize, with dashboards and reporting tools responding faster and more predictably. - Enhancement to Query Debugging. The widely-utilized
EXPLAINcommand, a favorite among developers and administrators, now comes with new options—MEMORYandSERIALIZE—designed to elevate the experience of debugging query performance. - Flexibility with
pg_dumpandpg_restore. A new option called--filter, which allowspg_dump,pg_dumpall, andpg_restoreto specify include/exclude objects in a file. This helps to quickly filter out which is required, and which is not.
New features and improvements
We’ll discuss the key things that played a significant role in improving the developer and administrator experience in production.
Support for incremental backups
Enterprises with critical PostgreSQL databases must either create software to automate scheduled backups, manage backup metadata, enforce retention policies, and streamline restore operations, or utilize a backup tool that provides these functionalities.
Consider: A team running a 5TB+ size production database schedules a full backup during a low-traffic window (e.g., 2 a.m.) using pg_basebackup with compression enabled. The database runs on a dedicated server with comparatively higher compute and high-speed SSDs, but the application still serves thousands of users globally. The full backup completes, but the process takes 20 hours, causes noticeable application slowdowns, and requires significant post-backup verification effort.
Taking this full backup doesn’t continuously store the incremental data in it. Hence there should be a comprehensive inbuilt solution that can resolve this, and PostgreSQL 17 came up with support for incremental backups here.
One of the widely discussed topics with PostgreSQL 17 is the initial support for incremental backup that we never had in the past. Most of the production systems nowadays make use of external tools such as PgBackrest, Barman etc., But the introduction of the incremental backup support has drawn plenty of attention from the administrator’s aspect.
How the backup restore works with the new feature
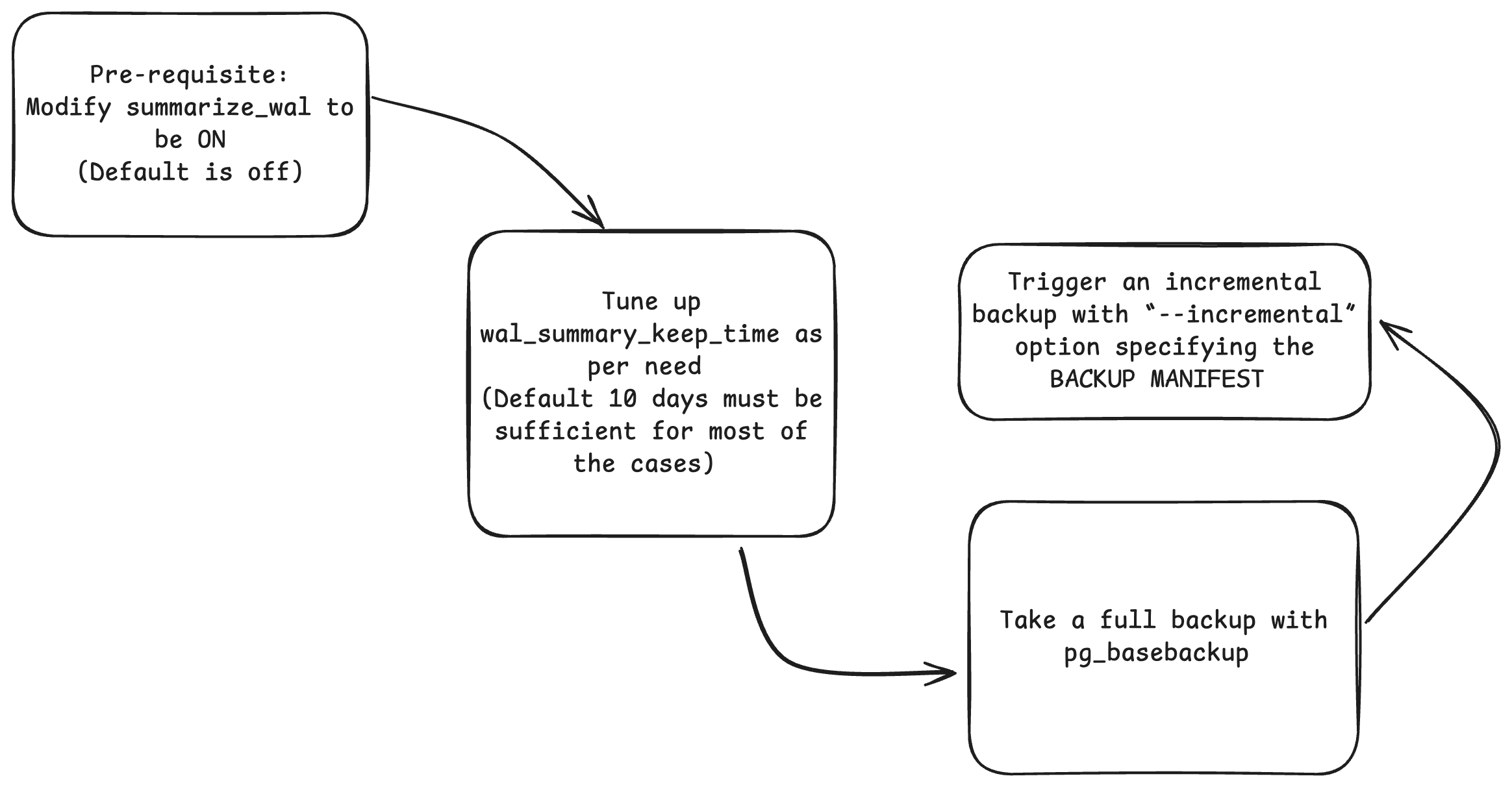
Backup with pg_basebackup
It’s common to use pg_basebackup, but with the need for incremental backups, it’s essential to turn on summarize_wal GUC and tune wal_summary_keep_time per the needs of the environment. With the tuned setup, we can now trigger the basebackup and then backup sequentially with the –incremental flag.
Restoring the full and incremental backups
Now we are all set! We have the full backups and the incremental backups. Now we can utilize the newly introduced pg_combinebackup to combine these full and incremental backups in sequence to form a single valid entity and recover/restore it into a full working database.
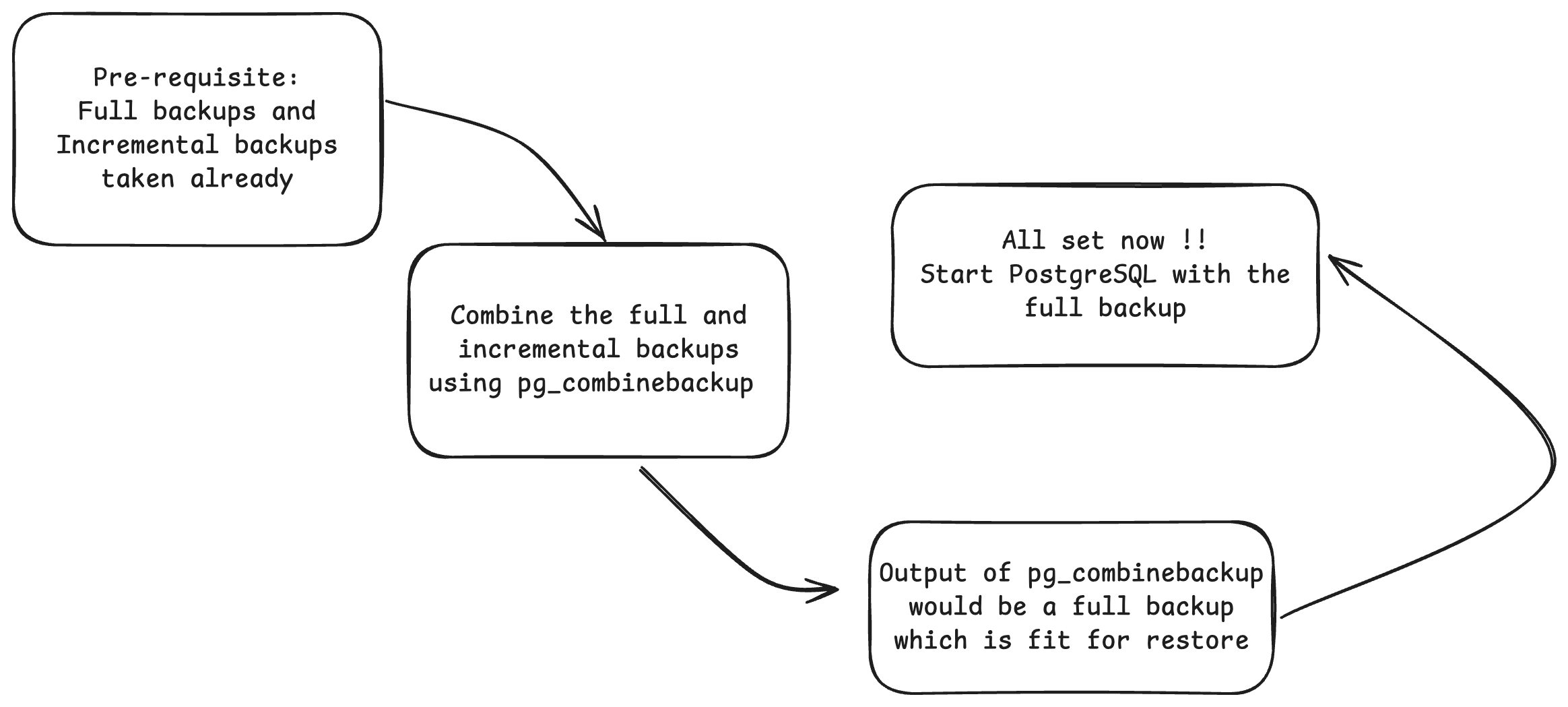
There are certain caveats with this feature for now—pg_combinebackup works only with the backups stored locally, performance improvements etc., hence it requires significant improvements to make it suitable for the production systems.
Tired of backup hassles with PostgreSQL? At NetApp Instaclustr, we’ve made it simple with meticulous handling, regular checks, and zero worries. We’re always leveling up with cutting-edge NetApp storage features for peak performance with continuous improvements.
Check our blog: Managed PostgreSQL on Azure NetApp Files. It’s a game-changer for cloud databases!
Failover control for the logical replication
Logical replication has evolved over the time from PostgreSQL v9.4 through PostgreSQL v17 and even into the latest v18.
Version 17 included improvements in failover slot synchronization, which is essentially a high availability feature that allows logical replication to continue working in the event of a primary failover (within a DC or between the DCs) which is one of the common scenarios. The feature keeps the replication slot on the primary node synchronized with the slots in the standby server.
How it works
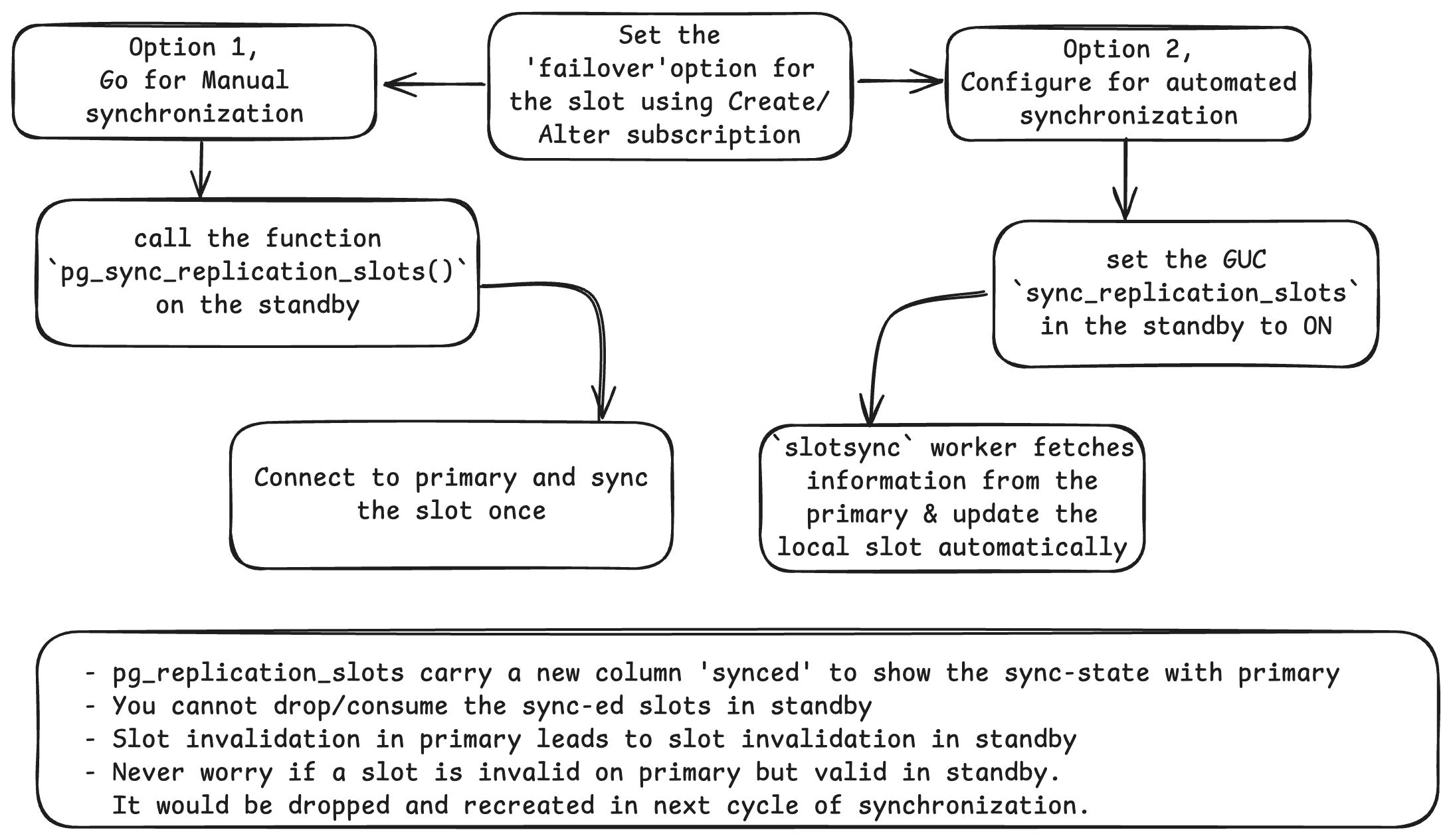
Worried about self-hosted PostgreSQL at your end? Feel free to migrate it to our Instaclustr Managed Platform, where we spin up your cluster in matter of minutes with High Availability and Replication, Backups, patching and more, all taken care of for you.
Other important things which were included with PostgreSQL 17
- Event triggers for authenticated logins for better control over the login event
- Support
+/- infinityin the interval data type:- This enhancement provides more flexibility when dealing with time calculations where an unbounded duration might be necessary.
- A set of SQL standard functions, query functions and constructors added for JSON type:
JSON(),JSON_SCALAR(),JSON_SERIALIZE(),JSON_EXISTS(),JSON_QUERY(),JSON_VALUE(), andJSON_TABLE()
- Additional improvements to logical replication: an option “failover” was introduced to the
CREATE/ ALTER SUBSCRIPTIONcommand. COPYcommand now has additional options likeON_ERROR error_actionandLOG_VERBOSITY verbosityfor better error handling.- The
MAINTAINprivilege was added toGRANT, and a new predefined rolepg_maintainwas added to ease off maintenance activities. - Significant improvements in index builds and performance:
BRIN– parallelCREATE INDEXnow supportedGiSTandSP-GiSTnow support Incremental sorts
- Changes to system catalogues such as
pg_stat_bgwriter,pg_replication_slots,pg_stat_progress_copy,pg_stat_progress_vacuum,pg_subscription,pg_stat_subscriptionfor better monitoring. - New core utilities such as
pg_combinebackup,pg_walsummaryto support the incremental backup feature. - With
psql,\drgcommand added to display role grants which was missing in the previous editions
You can find the detailed release notes here in official PostgreSQL website.
Conclusion
Though PostgreSQL 18 has just released, we wanted to spend some time to celebrate the remarkable achievements of PostgreSQL 17. The past year has showcased the power of open source collaboration, delivering tools that empower businesses, developers, and administrators worldwide. The future of this robust database looks brighter than ever. Here’s to another year of innovation, performance, and community-driven excellence in the PostgreSQL ecosystem!
Customers who would like to experience a PostgreSQL cluster on the Instaclustr Managed Platform can sign up for a free trial and create a cluster with PostgreSQL 17.
PostgreSQL 18 has been released with exciting features that is expected to improve the SQL performance and henceforth play a critical role in supercharging the workflows. The star of the show? Asynchronous IO support, turbocharging disk reads like never before with earlier releases of PostgreSQL! Stay tuned for our next blog, where we’ll dive deep into all the critical new features of PostgreSQL 18.