






















Automatic provisioning of Apache Kafka and Apache Cassandra clusters using Instaclustr’s Provisioning API
1 Introduction
The Anomalia Machina has kicked off, and as you might be aware, it is going to do some large things on Instaclustr’s Open Source based platform. This application will primarily use Apache Kafka and Apache Cassandra hosted on Instaclustr’s managed services. The building of Anomalia Machina is going to be iterative and experimental. We want to be ready in order to support this approach, so we want to develop some tools to help us setup the infrastructure for such a colossal task.
The first thing that comes to mind while working with platforms of clusters is to have a tool which will easily create the required infrastructure automatically: Clusters, Network connectivity, firewall rules etc. Thanks to Instaclustr’s provisioning API, we can accomplish this task with ease. The second thing to accomplish is to load the clusters with Data.
Let us look into how provisioning (this blog) and load generation for Cassandra/Kafka clusters (next blog) can be done.
2 Cluster Provisioning
The provisioning program can be completely build with any programming language/script of your liking, it’s that simple! So I chose to start with bash. I started by reading the Instaclustr Provisioning API support article. The provisioning API can be used to provision both Cassandra and Kafka clusters with appropriate configuration parameters.
I planned to create a JSON template (or skeleton) which will be filled out by a simple bash script, and can then hit the provisioning API to fire up a Cassandra/Kafka cluster. But, I first need to create an account on the Instaclustr console to have the authority to do this. So after creating an account, I am now equipped with a username-password to get started.
The first piece of puzzle is to have a main script which will drive the whole thing and invoke some functions to get the provisioning done. I also need a configuration file which will act as my primary input and have all the information about a cluster that I want to create. Finally, there should be a JSON template which will be used to create provisioning requests similar to those given in support article.
The scripts could be executed from any machine, server, cloud instance etc. I set it up on my laptop and is quite portable in case there is a need to move it. I created a base directory called ‘provisioner’ and a configuration file ‘configuration.sh’. The configuration file holds all the required parameters. Then, I started with the master script ‘provisioner.sh’, the script takes a few command line arguments to keep things flexible.
Now, after working out all the arguments, creating necessary directories and reading configuration; the master script is ready to play some function which will take care of further tasks. I created a new script with a function to read the json template and replace it with parameters from the configuration file. The ‘JSON request’ needs to be posted to the Instaclustr API URL, and if everything including my credentials is good, it should start provisioning a brand new cluster for me.
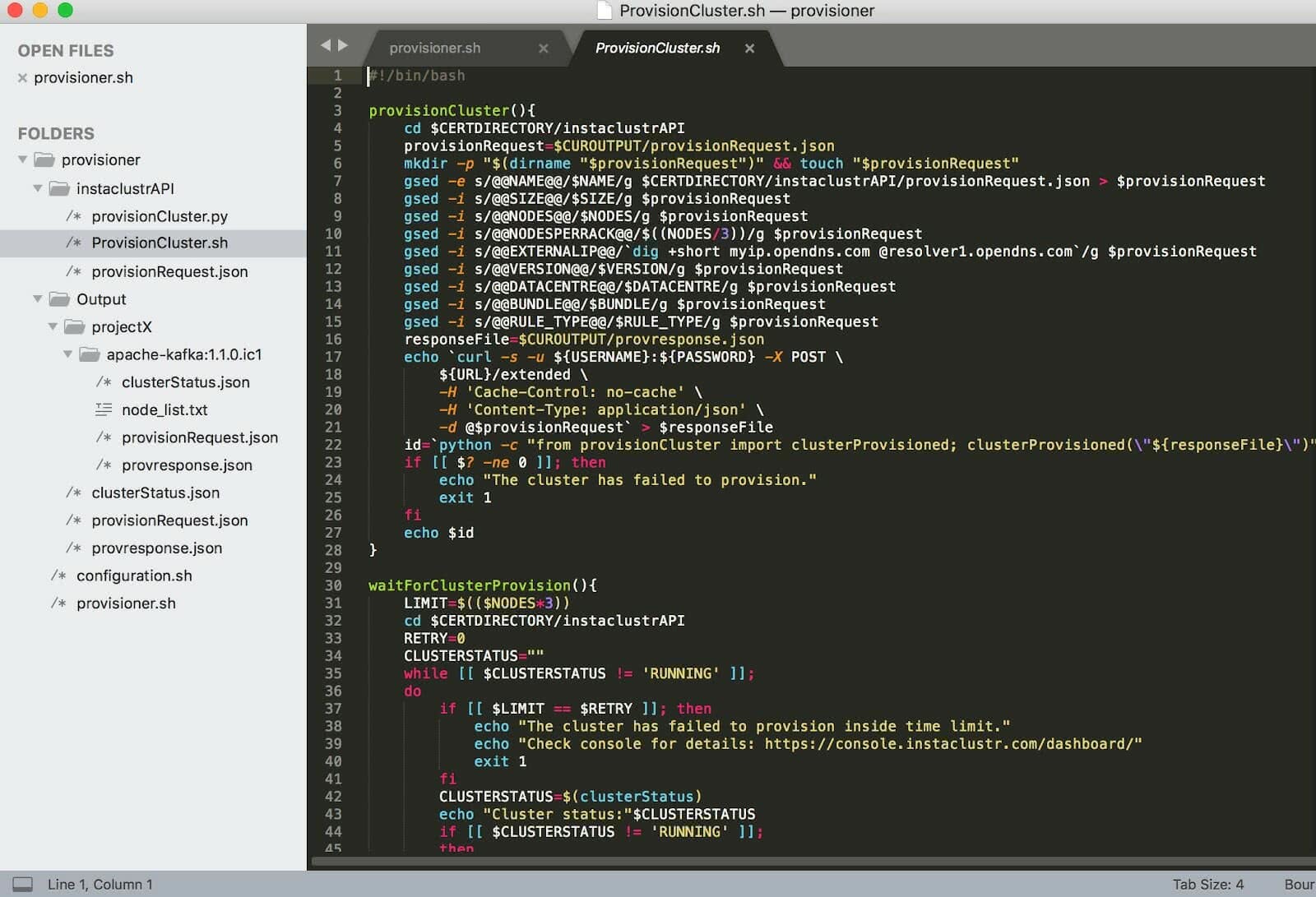
Wait! Even though my program looks way simpler for a seasoned programmer, and it just does some basic stuff, it still gave me a hard time to get it right for the first few times. I stumbled upon some hurdles like ignorance of syntax, (over)confidence about bash skills and lack of correct parameters on Instaclustr. In addition, bash error reporting is not really great. For example, if you miss initializing a variable, it is used but with a blank value.
Finally, I managed to get a cluster provisioning. But the program ends abruptly and we have no way of knowing whether it was successful or not. The support article actually mentions a remedy: “If the JSON is valid (see allowed values below), the API will respond with 202 Accepted and a JSON containing the cluster ”. That means I need to handle the response and look for the success.
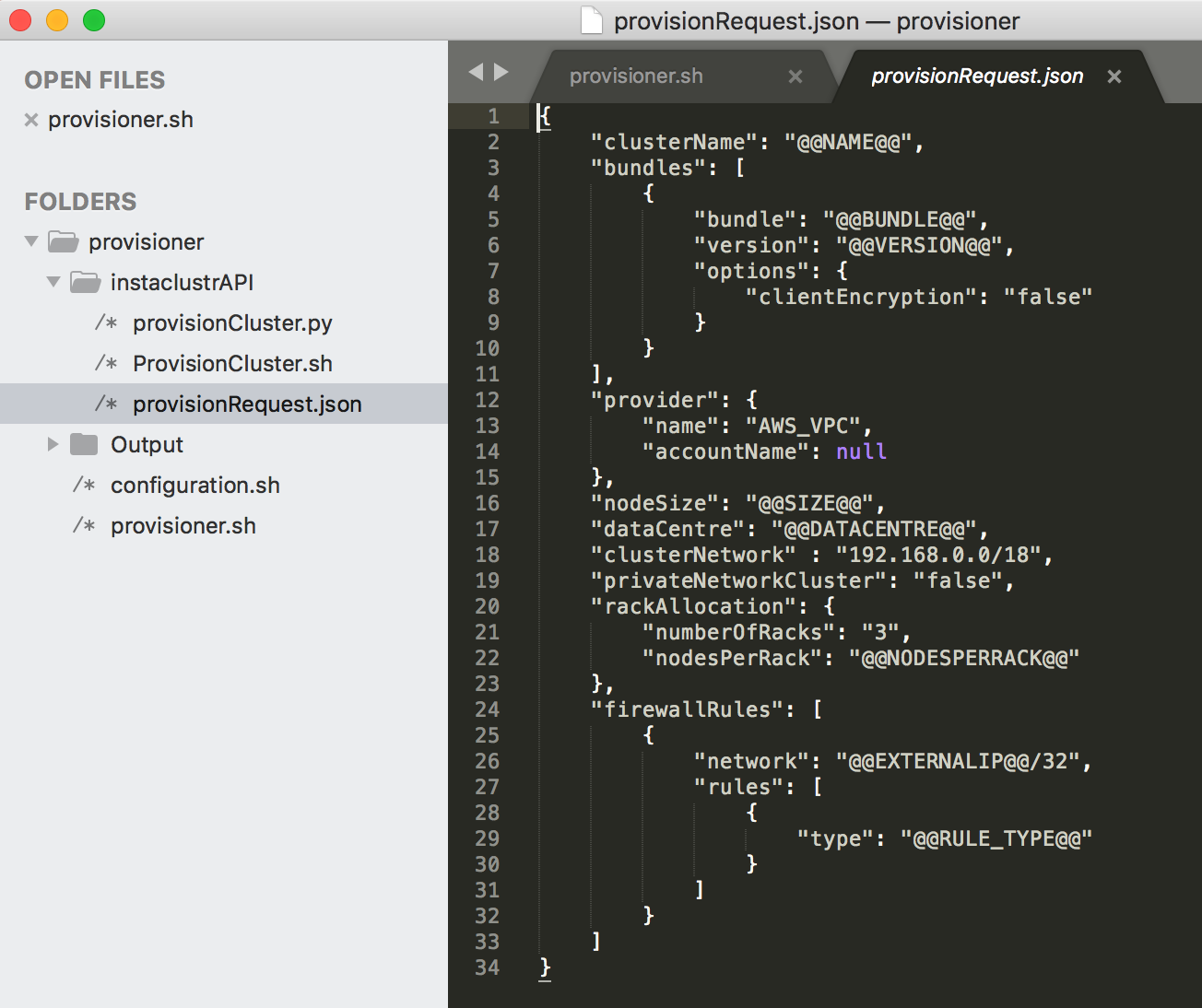
Handling a JSON response using a bash function sounds a bit difficult to me. Although I can grep the required message out from the response, I had already thought about a simple python function to parse the response with ‘JSON’ module and return ‘Cluster Id’. Creating a small python script was too easy and my bash function can now know the Cluster Id on success.
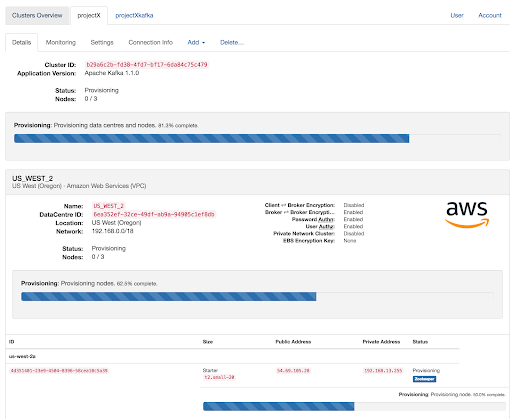
I could have stopped at this point but, the success of creating a cluster with an ad hoc request encouraged me to do something more. I looked at the support article further down and realized that I can actually poll the cluster status, and make the provisioner wait until the cluster is fully functional.
The reason behind this is that cluster provisioning takes some time and it depends upon the size of the cluster. This just required me to write one more python function which will look for “clusterStatus” in the status JSON. The bash has one more function to call ‘cluster status’.
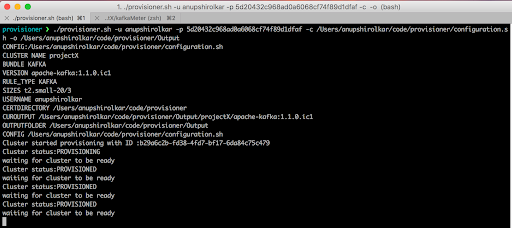
Here it is, a provisioner which uses a small configuration file and creates Cassandra/ Kafka clusters on the fly. I had to give some afterthought to the setup of provisioner and I collected the scripts dealing with Instaclustr platform in a new directory ‘InstaclustrAPI’. This package can be used in any other program to perform provisioning, status check etc.
Hope my small contribution helps Paul in building ‘Anomalia Machina’ and if it becomes a milestone in the history of Instaclustr/Open Source Software/Human History, I have a small credit 😛
Please find the code for provisioner here: https://github.com/instaclustr/provisioner
We would like to hear from you about your experience, comments, and suggestions.