Data lakes had a reputation problem. The promise was compelling: dump all your data into cheap object storage—S3, GCS, Azure Blob—and query it whenever you need. The reality was a mess of stale partitions, schema drift, and silent data corruption caused by unsafe concurrent writes. Engineers knew the risks and worked around them rather than fixing them.
Apache Iceberg was built to fix that. And it’s catching on fast—even in the Kafka® world Iceberg is a hot topic. If you’re running ClickHouse® or building a pipeline that feeds into it, Iceberg is quickly becoming hard to ignore if you care about accuracy at scale. It’s becoming the connective tissue of the modern data stack.
The library card catalog analogy
Imagine a massive library—millions of books spread across dozens of warehouses. The only way to find a book was to walk into each warehouse and look around. If someone moved books, you wouldn’t know. Two people re-shelving at the same time? Chaos. And there was no concept of “what did this library look like last Tuesday?”
Now imagine a central card catalog. Every book has a precise location record. The catalog tracks every change as a versioned log. Want the library as it existed last Thursday? Check out that version. Two people making changes simultaneously? The catalog handles the conflict.
Apache Iceberg builds that card catalog into its architecture—and unlike a real library’s fixed desk, it’s pluggable. You can swap in whichever catalog backend fits your infrastructure.
What Apache Iceberg is (and isn’t)
Iceberg is not a storage engine. It doesn’t store your data. It’s a table format specification—an open standard defining how metadata about your data files is structured, stored, and updated.
Your actual data lives in Parquet, ORC, or Avro files in object storage. Iceberg sits on top and provides a structured, versioned, queryable description of what’s there. Any engine that speaks the Iceberg spec—Spark, Flink, Trino, ClickHouse, Dremio—can read and write the same tables without external coordination. Iceberg is engine-agnostic by design.
The metadata architecture: 3 layers deep
Iceberg’s metadata isn’t a flat index—it’s a three-tier hierarchy, and each layer does specific work.
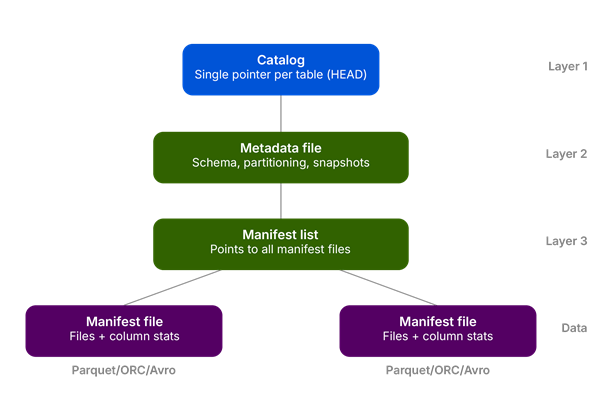
The catalog holds a single pointer per table—think of it as the HEAD commit in Git. When a transaction commits, the catalog atomically updates this pointer. This is how Iceberg achieves snapshot isolation: readers grab the current pointer at query start and work from that, even if writers are actively modifying the table.
The metadata file describes the table’s schema, partitioning, and snapshots state at a point in time—the sequence of these files across versions is what forms the changelog.
The manifest files are where query optimization actually happens. Each lists data files and includes per-file stats: min/max values, null counts, row counts. When ClickHouse runs a query with a WHERE clause, it reads the manifests, compares the predicate against those stats, and skips entire files that can’t possibly contain matching rows. That can reportedly deliver up to a 10x performance improvement on queries against clustered data, according to Apache Iceberg’s own performance docs—without reading a byte of the underlying data.
ACID transactions on object storage
Object storage is not a database. S3 doesn’t have row locking or transaction logs. Yet Iceberg gives you ACID semantics on top of it through optimistic concurrency control.
Before Iceberg, most data lakes relied on Hive-style table management—a convention where partitions are just directory paths in object storage, with no atomicity, no versioning, and no coordination between readers and writers.
When a writer commits a change, it reads the current metadata pointer, writes new data files, writes a new metadata file, then attempts to atomically swap the catalog pointer from old to new. If two writers commit simultaneously, only one wins. The other detects the conflict, re-reads the new state, and retries. No locks, no downtime, no “wait until the batch job finishes.”
This is how you avoid double-counting revenue because someone rewrote a partition mid-query. And it’s fundamentally different from Hive-style table management, where you’d overwrite directories and hope nobody was reading at the same time.
Time travel and schema evolution
Because every snapshot is preserved in the metadata chain, Iceberg gives you genuine time travel. Many engines support queries like:
|
1 |
SELECT * FROM orders FOR SYSTEM_TIME AS OF '2025-04-27 09:00:00'; |
This means you can point at a specific snapshot when debugging a data quality issue—no restores, no separate staging copies. The history is just there. Snapshots are retained until you explicitly run expire_snapshots; until then, every version is intact.
Schema evolution is equally safe. Iceberg tracks columns by stable integer IDs, not names. When you rename user_id to customer_id, existing data files remain valid – the engine maps old IDs to the new schema on read. Partition evolution works the same way: new data uses the new partition spec, old data keeps the old one, both in the same table simultaneously.
Hidden partitioning
Traditional Hive-style partitioning requires query writers to explicitly filter on partition columns—or pay for a full table scan. The failure mode is silent and expensive:
|
1 2 |
-- Without Iceberg: forget this filter and you scan everything WHERE event_date = '2026-04-01' |
|
1 2 |
-- With Iceberg hidden partitioning: this still prunes correctly WHERE event_timestamp >= '2026-04-01' |
You define a transform in the table spec bucket(user_id, 16), day(event_timestamp) and Iceberg applies it at write time and uses it for pruning at read time. The querying engine doesn’t need to know the partition scheme exists.
Where ClickHouse fits in
ClickHouse is a columnar OLAP engine built for speed, but data has to get there from somewhere. The pattern emerging in production stacks:

Iceberg isn’t replacing ClickHouse—it’s removing everything brittle that comes before it. ClickHouse answers questions fast. Iceberg helps make sure those answers are correct.
ClickHouse reads Iceberg tables directly via its IcebergS3 table engine, taking advantage of manifest statistics for efficient file pruning. You get streaming freshness from Kafka, schema governance and time travel from Iceberg, and ClickHouse’s query speed at the end. Without Iceberg in that stack, you’re writing raw Parquet with no metadata governance, or managing partition directories by hand—neither scales well operationally.
The practical upshot
Iceberg isn’t a query engine—it actually helps make queries faster by making them scan less. The bigger win is that it makes your data trustworthy enough to query at all. Data lakes had a reputation problem and Iceberg is what fixes it. Not by replacing the lake, but by making it behave like a system rather than a set of files: a shared table layer that provides consistency, isolation, and a durable history across the entire stack.
For teams building on open source data infrastructure—streaming with Kafka, storing in S3, and querying with ClickHouse—Iceberg is the piece that makes it all coherent.
NetApp Instaclustr provides both the managed Kafka and ClickHouse that anchor that pipeline— we provide 100% open source technologies, designed for no vendor lock-in, and 24×7 expert support. Your data stays in your object storage, your stack stays portable, and your team stays focused on building instead of managing infrastructure. Get started on Instaclustr today with our free trial.