In this 2-part blog series, we are exploring the use case of “freezing” streaming Apache Kafka data into (Apache) Iceberg! In part 1, we looked at Apache Iceberg, and a common solution to this problem using an Apache Kafka Connect Iceberg Sink Connector. Now we’ll turn to another approach that may be feasible in the future— Kafka Tiered Storage and so-called “Iceberg Topics”; although the “Iceberg Topics” part of this stack isn’t yet production-ready or available on our platform.
Kafka Tiered Storage
For a blog series that started out being about Kafka and Iceberg, why are we suddenly interested in Kafka Tiered Storage? Well, icebergs are just “tiered” floating ice. The visible tip (typically only 10%) is called the Hummock, and the submerged majority is called the Bummock! So, let’s recap Kafka Tiered Storage first.
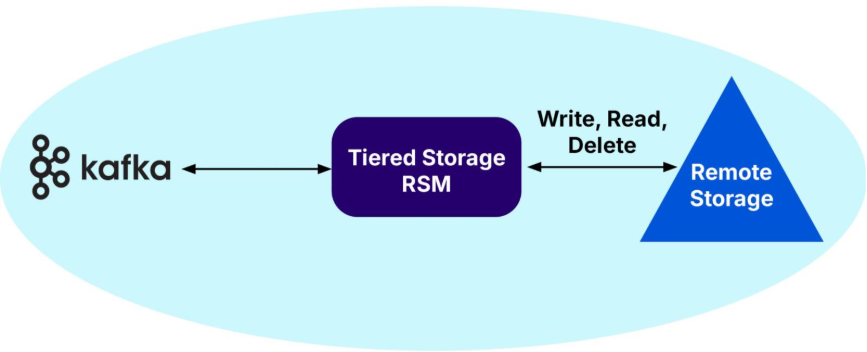
Kafka Tiered Storage is a mechanism to enable older and potentially more records to be stored on cheaper remote cloud native storage, such as AWS S3. I’ve written extensively about how this works (Part 1, Part 2, Part 3) and the use cases that would benefit.
To briefly summarize, it asynchronously copies all non-active segment records to remote storage. For up to local.retention.ms time, both local and remote copies will exist; afterwards, only remote copies remain. After retention.ms, remote copies are also deleted. Until then, Kafka clients can transparently consume records from the last offset, with older data (beyond local.retention.ms but within retention.ms) served from remote storage.
So, what features does this approach have?
Similar to Kafka Connect Sink Connectors, records are copied to the sink system (remote storage in this case). However, records in the active segment are not copied, only those in closed segments, unlike Kafka Connect, which copies from active segments in real-time.
But who’s in control of the remote data? Unlike Kafka Connect Sink Connectors, which are “copy and forget”, Kafka Tiered Storage is completely in control of the remote data lifecycles, including expiry from remote storage. And, unlike Kafka Connect, Kafka can still read the data back from tiered storage (as long as it hasn’t expired). So, Kafka Tiered Storage supports writes, reads, and deletes from remote storage. But there is a delay in copying records to remote storage, due to waiting for segments to close and asynchronous copying.
But the main limitation with Kafka Tiered Storage is that it’s “single-use”—only the Kafka cluster that wrote and manages the data on remote storage can read it—you can’t use it for another purpose with different applications. Contributing to this limitation is that Kafka Tiered Storage doesn’t place any extra restrictions on Kafka, i.e. the Kafka Schema Registry (e.g. Karapace) isn’t compulsory, and records may not be in JSON or have explicit inline schemas. That is, the data stored on remote storage will not be understandable and therefore de-serializable by anything other than the Kafka consumers of the cluster that wrote them.
Or maybe you can! What’s that fast-approaching iceberg in the distance? Watch out for Iceberg Topics!
Iceberg Topics
Would you like your topics “frozen”? You can with Iceberg Topics.
What are “Iceberg Topics”?
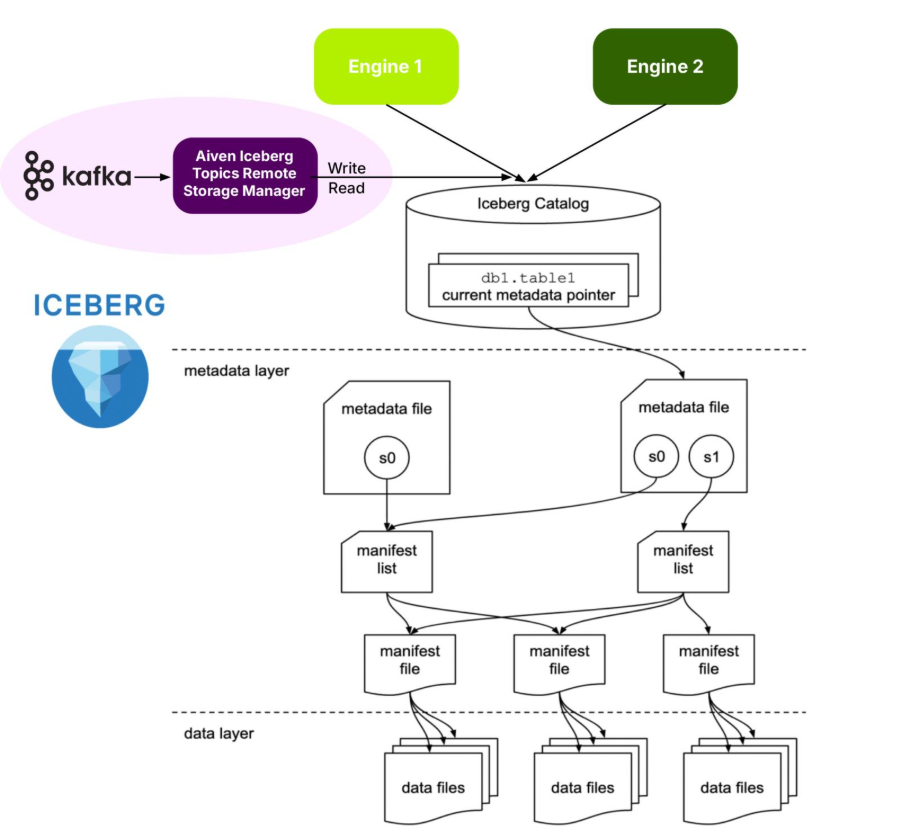
“Iceberg Topics” are a change to the Kafka Tiered Storage Remote Storage Manager (RSM) to stream records directly to Iceberg Tables. This works similarly to Tiered Storage—records from closed segments are eligible for copying to remote storage, but in this case, it uses Iceberg tables as the remote cloud storage.
Here’s the technical white paper, and the code is here. Note that this is currently not a Kafka KIP and is only available as a plugin for Aiven’s tiered storage code.
How do Iceberg Topics work?
The changes to the Tiered Storage RSM mean that Kafka records are transformed and written to Iceberg tables (in Parquet format). Sounds easy, but there are a few extra requirements for this to work. Because Kafka is by default schema-free, this currently only works correctly if you have a Kafka Schema Registry (e.g. Karapace) AND with AVRO values – i.e. this is the only way it currently interprets the Kafka value data structures and transform them to Parquet correctly (see my “Exploring Karapace” blog series, which introduced Karapace and AVRO).
It automatically creates Iceberg Tables if they don’t already exist. The table structure is documented here. What’s interesting? Rows contain all the Kafka meta-data and data you’d expect (e.g. partition, offset, timestamp, headers and value). However, unexpectedly, the key is only stored as key_raw (binary). There are two possibilities for the record value:
- value (struct)—the record value, according to the schema.
- value_raw (binary) – the record value as binary, only filled when the value can’t be parsed.
The table is partitioned by the day of timestamp.
If the value can’t be parsed or is malformed, the binary value is stored instead, meaning no data loss. However, you won’t be able to read it back with an Iceberg engine, but Kafka consumers will still work.
So, this implies that Iceberg topics can be read by Kafka consumers. This follows from the Tiered Storage semantics, which guarantees that records are retained in remote storage until retention.ms, for subsequent re-processing by Kafka consumers.
To summarize, the plugin is responsible to:
- Parse segments as Avro records and validate values against the schema registry.
- Create the target Iceberg table if absent.
- Transform Avro values to Iceberg rows and write Parquet, manifest and metadata files.
- On fetch, read the referenced Parquet files, transform back to Avro, and pack records into Kafka batches.
The plugin is not responsible for other operations on Iceberg schemas (e.g. compaction and snapshot expirations).
What’s required for it to work? Here’s the complete list of dependencies that Iceberg topics need to work:
- A Kafka Schema Registry (e.g. Karapace)
- An Iceberg Catalog.
- Object storage (e.g. AWS S3 Tables).
But do we also need an Iceberg engine? No, like Kafka Connect Iceberg Sink Connectors, the engine is “built-in” the tiered storage plugin.
How did we test them?
We ran some tests with Tiered Storage Iceberg topics using Karapace, the Nessie Catalog (GitHub), and AWS S3 Tables as the object storage, and Athena to run test queries on the table data.
What did we find?
We tested the above configuration, created an Iceberg topic (tiered storage is enabled per topic with the configuration remote.storage.enable=true), and produced records to it. The Iceberg table was successfully created with data that could be read from Athena! It worked!
Kafka Consumer Bug
However, reading back from Kafka consumers was not as successful (see this bug report). We saw things like less, more or even infinite consumption (!) of the produced records. This is unfortunate behaviour, making it less useful than the default Kafka Tiered Storage, given that it’s basically only write-only at present. We believe this bug has now been fixed, but we haven’t redone the testing. We also discovered that Kafka consumers can only consume from Iceberg topic tables, not existing tables, or tables created by other applications.
Performance and delays
There will also likely be performance implications (increased latency and broker resource overhead for Iceberg writes and reads, given the need to transform between native Kafka and Parquet data formats, in each direction. And compared with Kafka Connect, it has the limitation of Kafka Tiered storage, which is that only records from closed segments are eligible for copying to Iceberg tables—so it’s not “real-time” as no records from active segments will be copied. This delay may be acceptable for some use cases, however, and may be comparable to the delay with Kafka Connect, even given the default of 5-minute commit interval noted above.
However, the proposed diskless “KIP-1176: Tiered Storage for Active Log Segment” could speed things up as it enables records from the active segment to be copied to remote storage—assuming this also works for Iceberg tables. But this may result in more smaller files, which isn’t ideal for Iceberg, although the batch size would likely be tuneable (enabling trade-offs between lag and file size).
But note that you still have the benefits of tiered storage, so real-time and slow/delayed consumers will all likely consume directly from local storage, not remote/Iceberg tables—it will only be historic data that is replayed/reprocessed at slower speeds in practice.
Only one type of tiered storage is supported per cluster
We also noted that you can’t currently have a mix of Iceberg and normal tiered storage topics. Why not? This is because Kafka only has one topic setting for tiered storage (remote.storage.enabled=true/false) and the type of tiered storage (e.g. normal or Iceberg topics) isn’t an option.
Given that default Tiered Storage works fine without a Schema Registry, but Iceberg Topics basically can’t work without a Schema Registry, this is a fundamental limitation for supporting both types of tiered storage on a cluster (which may also be required for backwards compatibility).
Transformations may fail
As already noted, there may be challenges with the transformation from Kafka to the Iceberg table format. Apart from needing a mandatory Schema Registry, only AVRO is currently supported, and if the transformation during the write failed (e.g. from a corrupt or incompatible record)—the fallback is binary, which can’t be read from Iceberg engines.
No support for Kafka key transformations
And Kafka keys are never transformed—they are just stored as binary data (to keep partitioning semantics). This is a bit strange, as Kafka Keys are also data (like values) and should be treated as first-order citizens. Unfortunately, this means that queries from Iceberg engines that require knowledge of the structure and data types of the keys will be impossible. An obvious improvement would be to parse the keys and store them as structured data, as well as keeping binary keys for ordering. A workaround is to ensure that the keys are duplicated in the value part of the records. I’ve encountered this sort of problem before streaming records to external systems, see “Missing Keys” in this blog.
No support for Iceberg management
We also noted that the plugin doesn’t manage Iceberg management operations, including compaction and snapshot expiration. But a complication arises as it’s acting as the Tiered Storage manager—this normally means that it’s responsible for deleting records from remote storage after the retention.ms expiry time. So, in fact, it doesn’t perform any remote deletions. All that happens is that after retention.ms, the remote records become unavailable for Kafka consumers. The data is still available in Iceberg and can be read from Iceberg engines. Also note that if a topic is deleted on Kafka, the corresponding Iceberg table is not deleted.
This is a bit of a confusing situation, but it fits with the way Iceberg works (it’s “frozen” data after all), and like the semantics of Kafka Connect Iceberg sink connectors, which are “write-only” as well (no deletes or reads). But this does correspond to the observation we made in part 1 of the blog, that data lakes are best treated as immutable storage, allowing for data analytics operations over large amounts (and times) of data.
Reading back records in “Kafka” order is possible
And what about order? Kafka only guarantees record order within topic partitions, not across partitions. This is also true with records written to Iceberg tables, as segments for different partitions are appended to Iceberg concurrently. If you want to read back records using an Iceberg engine in the same order as Kafka, you can use a query like this:
|
1 2 3 4 5 |
SELECT * FROM iceberg.table ORDER BY partition ASC, offset ASC; |
Things to note about this approach:
- The RSM supports writes to and reads (for Kafka consumers) from Iceberg
- The RSM manages record retention lifecycle from the Kafka side, but doesn’t delete records from Iceberg
- Comparing it with Kafka tiered storage:
- It’s similar to Kafka tiered storage in that:
- It supports writes to and reads from remote storage (i.e. remote storage is the source of truth)
- It manages record retention from the perspective of Kafka.
- It’s different to Kafka tiered storage in that:
- It doesn’t delete expired records from remote storage.
- Extra management of the Iceberg tables is likely to be required.
- Other Iceberg table engines can also read from the Iceberg tables.
Comparison table
Finally, here’s a comparison of the main features of these approaches to freezing your streaming data into Iceberg Tables, without sinking your streaming ship (Column 2 is included for completeness, given that Iceberg Topics are built on Kafka Tiered Storage):
| Feature | Kafka Connect Iceberg Sink Connector | Kafka Tiered Storage*
(using cloud storage) |
Iceberg Topics (tiered storage using Iceberg tables) |
| Zero-copy | FALSE | TRUE | TRUE |
| Schema | JSON or inline schema or Karapace | N/A | Mandatory |
| AVRO supported | TRUE | N/A | TRUE |
| JSON supported | TRUE | N/A | FALSE |
| Protobuf supported | TRUE | N/A | FALSE |
| Schema restrictions | TRUE | N/A | TRUE |
| Schema evolution supported | TRUE | N/A | FALSE |
| Kafka consumers supported | FALSE | TRUE | TRUE (but untested) |
| Records in active segment available to remote storage | Yes, but delayed up to 5 minutes | FALSE | FALSE |
| Kafka responsible for remote storage management | FALSE | TRUE | FALSE |
What can we conclude about Iceberg Topics so far?
It’s not production-ready and is not currently available in our managed platform. It also doesn’t currently support schema evolution, duplicates are possible, and Kafka transactions are not yet supported (Kafka transactions support atomicity and exactly once delivery semantics; read more about Kafka transactions here and this blog where I used them in conjunction with Kafka Streams). And you can’t read keys from Iceberg engines.
There are also two main conceptual differences to Tiered Storage—Schemas are mandatory, and the RSM is no longer responsible for remote storage management—i.e. you will likely need extra tools for Iceberg management.
Finally, it really needs a full-scale benchmark and resource usage analysis conducted before production use to check that it doesn’t introduce too much latency or cluster overhead.
But it does look like an interesting idea with some useful characteristics (e.g. “zero-copy”, with support for both Kafka and Iceberg engine reads from the same data), particularly if you are already using Kafka Tiered Storage already in your clusters.
In conclusion, the following status table shows that currently, the only production-ready solution to streaming Apache Kafka data into Apache Iceberg is the Kafka Connect Iceberg Sink Connector.
