Ever wondered if upgrading your Apache Kafka infrastructure could boost performance while keeping costs in check? You’re not alone. As organizations scale their data streaming platforms, choosing the right compute nodes is key to maintaining high throughput, low latency, and manageable costs.
AWS’s latest Graviton processors, Graviton3 (powering R7g instances) and Graviton4 (powering R8g instances), promise significant improvements over earlier models. But do these gains translate into real-world benefits for Apache Kafka workloads?
In this analysis, we benchmark AWS’s newest Graviton nodes for Apache Kafka. We’ll break down our testing process and share key metrics—CPU efficiency, P99 latency, and cost-performance ratios. See how upgrading to newer nodes can improve resource utilization and response times.
Whether you manage high-volume streaming, optimize for strict SLAs, or aim to get the most from your infrastructure, this deep dive provides the insights you need to refine your Kafka strategy. Let’s see how the latest Graviton generations perform and what they mean for your workloads.
By adding support for AWS’s latest generation compute nodes—the 7th generation (R7g, Graviton3) and 8th generation (R8g, Graviton4)—NetApp continues to further enhance the quality and performance of our Instaclustr for Apache Kafka offering. In our benchmarking tests, both R7g and R8g instances delivered significant improvements over R6g:
- CPU usage dropped by over 25% on R7g and by more than 45% on R8g
- P99 latency improved by nearly 15% on R7g and close to 20% on R8g
These measurable gains highlight how the architectural and networking advancements of these new nodes can directly translate into lower latency, higher efficiency, and better cost-performance for Kafka customers. In this blog, we outline our test setup and methodology along with detailed results.
Overview of AWS Graviton node upgrades
Before we go further, let’s review what we know about these newer node generations. According to AWS, the transition from R6g (Graviton2) to R7g (Graviton3) delivers up to 25% better compute performance, 50% more memory bandwidth (AWS Graviton3 blog). The latest R8g (Graviton4) generation builds on this by offering up to 30% higher performance than R7g, increased memory bandwidth, and more cores for larger-scale workloads (AWS Graviton4 blog). These claimed improvements target both general-purpose and specialized workloads, such as Kafka, that benefit from lower latency, higher throughput, and better scalability.
R6g vs. R7g vs. R8g benchmarking
Test setup
To evaluate the performance changes introduced in the newer generation nodes, we conducted tests across the R6g.large, R7g.large, and R8g.large generation instances. We chose large size as the baseline for this test to ensure consistency across node generations. It’s also one of the most commonly deployed instances size on the NetApp Instaclustr platform.
Following AWS’s published EBS baseline specifications for gp3 volumes (baseline throughput of 78.75 MB/s and 3,600 IOPS), we configured our test volumes to use the free throughput threshold of 125 MiB/s and 3,600 IOPS. The tests were executed at the same message rate across all node generations and ensured that the IO wait stayed within the same acceptable limit threshold for all tests.
Each test was run on a 3-node Kafka 3.9.1 cluster (the most commonly deployed versions on the Instaclustr Platform), deployed in the us-east-1 AWS region, using the KRaft mode with collocated brokers and controllers and client–broker encryption enabled. The cluster was configured with 5 topics with a total of 200 partitions, and a replication factor (RF) of 3.
The librdkafka stressor tool was used to generate messages into the cluster, and a total of 30 producers and 30 consumers were used. This configuration was chosen to reflect a typical customer deployment, to ensure that the results are representative of real-world workloads and that performance differences can be attributed primarily to the underlying node generation rather than storage or software version changes.
In this benchmarking exercise, we primarily focus on two key performance indicators: CPU usage and P99 produce latency. CPU usage reflects the efficiency of resources consumption across the instance types, while P99 produce latency highlights the worst-case message production delay at the 99th percentile, providing insight into system responsiveness under load.
To quantify performance improvements across generations, we calculated the performance reduction ratio using:
|
1 |
(old metric value—new metric value) / old metric value * 100% |
From R6g to R7g: Faster and more efficient
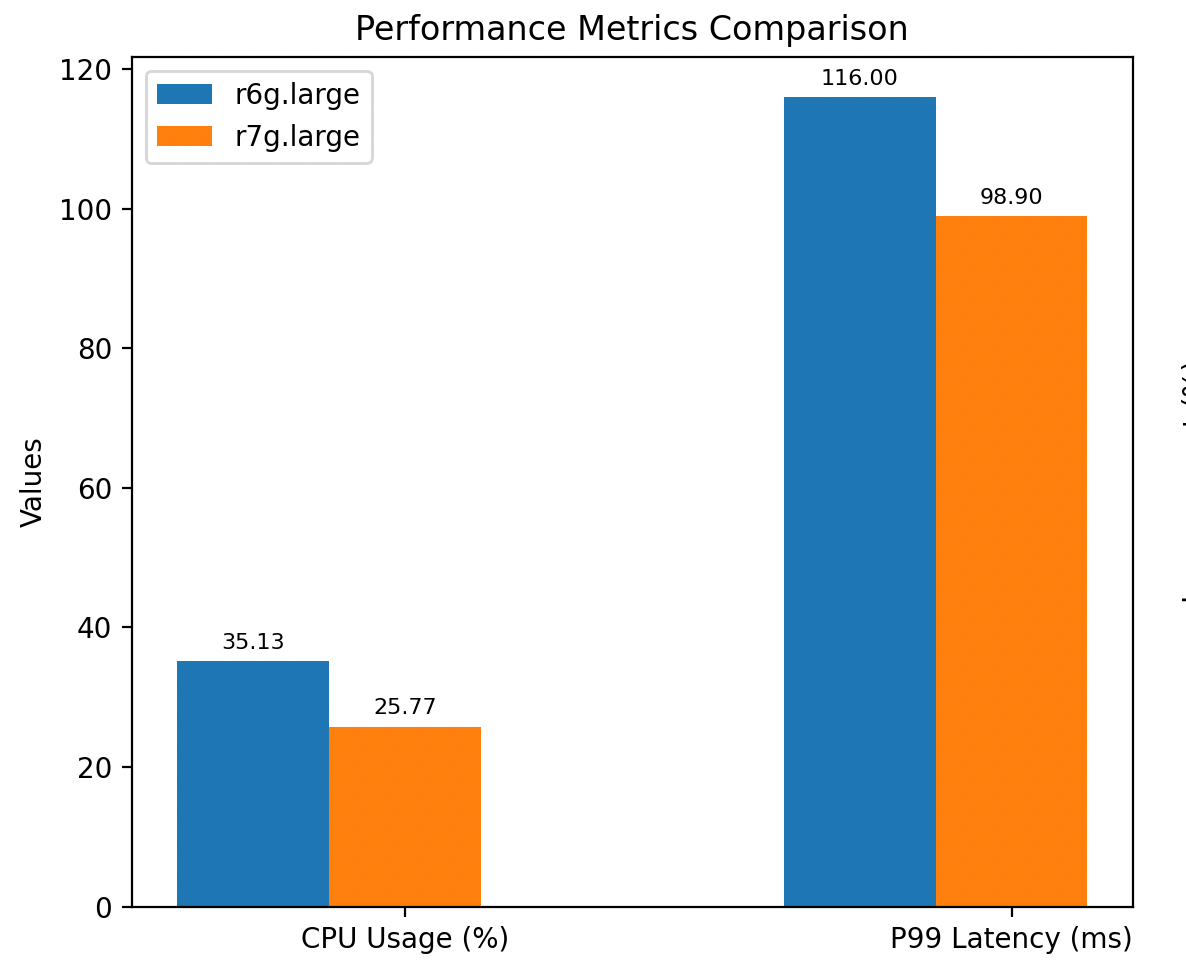
Note: Lower values indicate better performance (CPU usage and latency)
- CPU usage: Upgrading from R6g.large to R7g.large delivers immediate, tangible performance benefits. In our tests, CPU usage dropped by over 25%, freeing up valuable compute headroom for higher throughput, more partitions, or additional workloads without scaling out.
- P99 latency: At the same time, P99 produce latency improved by nearly 15%, enabling faster and more consistent message delivery for real-time applications.
These gains can directly translate into smoother operations and greater efficiency, especially for Kafka customers managing large or latency-sensitive workloads. The results align closely with AWS’s claims of higher compute performance and improved efficiency in the Graviton3 generation, confirming that the R7g is a strong upgrade path for most production environments.
From R6g to R8g—Maximum efficiency and lower latency for demanding workloads
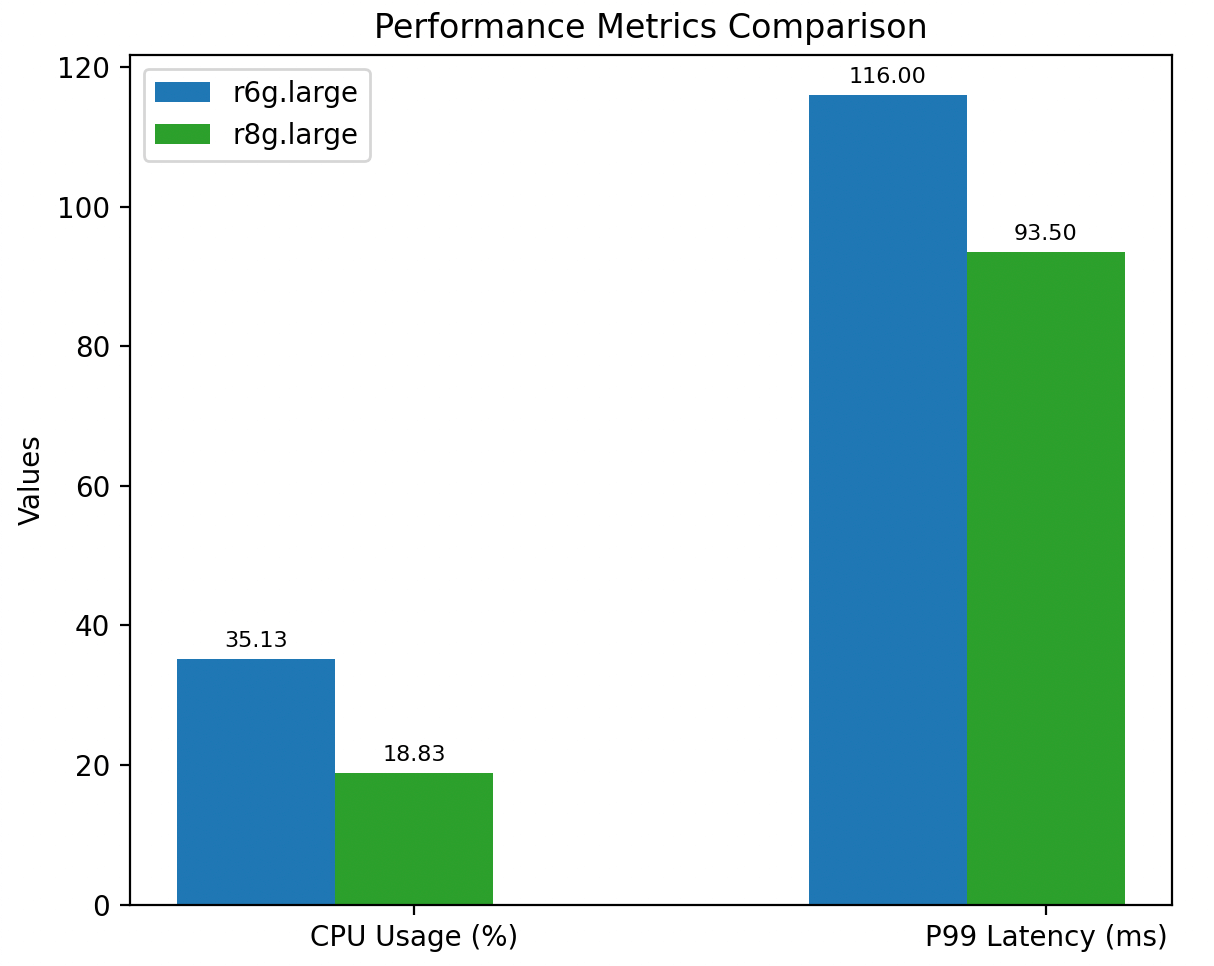
Note: Lower values indicate better performance (CPU usage and latency)
For customers looking for the best performance available, the jump from R6g.large to R8g.large offers a dramatic transformation.
- CPU usage: Our testing showed an over 45% reduction in CPU usage, effectively doubling the available processing capacity for the same workload. This level of efficiency allows you to handle traffic spikes, delay the need to scale your cluster, and consolidate workloads onto fewer nodes — all of which can reduce operational costs.
- P99 latency: In parallel, observed P99 produce latency improved by nearly 20%, cutting almost 23 milliseconds from the tail latency – which can help ensure faster data availability across your pipelines. The Graviton 4 generation delivers superior compute power and memory bandwidth, making R8g an ideal choice for high-volume, SLA-driven Kafka deployments.
Performance comparison conclusion
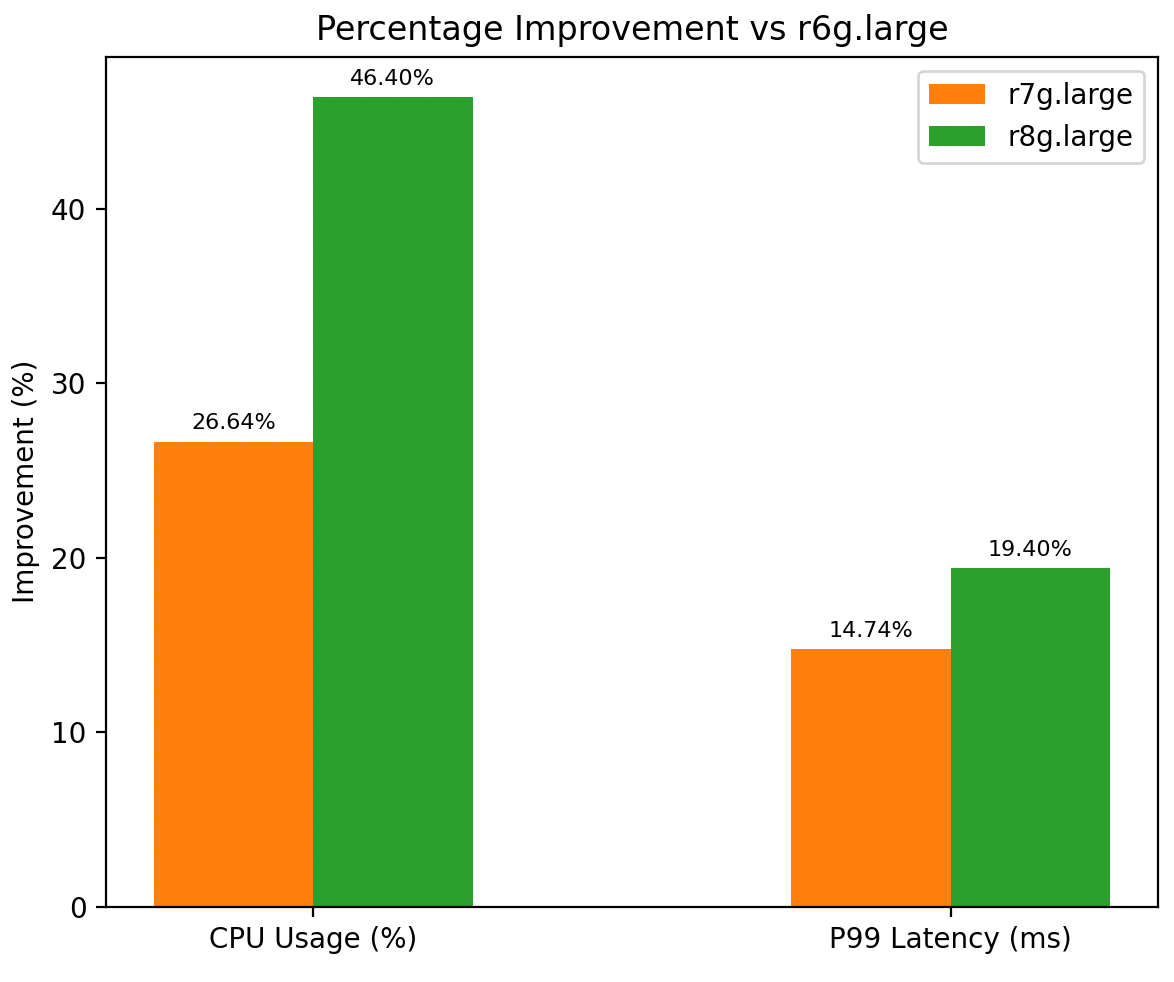
Whether you’re looking for an efficient, cost-conscious upgrade or aiming for the highest performance available, both R7g and R8g deliver measurable improvements that match AWS’s own performance promises.
These results align closely with AWS’s own claims for Graviton 3 and 4 generations, and our testing confirms the improvements translate directly into real-world Kafka workloads. With these upgrades, you can handle higher message volumes, reduce processing delays, and scale more confidently. In some scenarios, the improved efficiency also allows you to achieve the same performance with fewer nodes, helping to reduce overall infrastructure costs.
One consideration to keep in mind while choosing which generation of nodes to use is that the 8th generation support is still being rolled out in the various AWS regions worldwide. So, whereas the 7th gen is supported in 36 regions, the 8th is only supported in 17 regions.
Price-performance comparison
When we talk about upgrading instance types, it’s not just about “faster” but about getting more performance for every dollar you spend. That’s where the latest AWS Graviton generations really shine.
To ensure an apples-to-apples comparison, we decided to look at the on-demand pricing data for the US East (N. Virginia) region, which at the time of this write 11th August 2025 were:
| Instance type | On demand price (per hour) |
| R6g.large | $0.107 |
| R7g.large | $0.107 |
| R8g.large | $0.13 |
Now here’s where it gets interesting:
R6g → R7g: Free performance boost
In our performance tests, we observed that moving from R6g.large to R7g.large cut CPU usage by over 25% and improved P99 latency by nearly 15% without increasing the hourly cost. We believe that’s essentially a free upgrade: the same price, noticeably better performance. For most workloads, this is a no-brainer since you get more throughput, better stability, and lower latency for the same AWS bill.
R6g → R8g: Premium performance at modest cost
Switching from R6g.large to R8g.large did raise the on-demand cost by about 21.5% ($0.107 → $0.13/hour). But in return, we observed that it provided over 45% lower CPU usage and nearly 20% lower P99 latency. So, from a price-performance point of view, we observed R8g can deliver above 50% better CPU efficiency per dollar compared to R6g!
For high-throughput or latency-sensitive Kafka deployments, the extra performance of R8g can benefit customers in two keyways:
- With more powerful nodes, clusters can handle increased workloads while keeping the same number of nodes. This allows them to get more value from their existing infrastructure without increasing costs.
- Alternatively, clusters can be downsized vertically or horizontally to support the same workload, which brings down operational overhead and infrastructure costs in the long run.
In both cases, R8g’s efficiency helps clusters overcome CPU bottlenecks and supports scaling without sacrificing performance or reliability.
Ready to unlock Kafka’s full potential?
We believe the numbers speak for themselves: AWS’s Graviton7 and Graviton8 nodes deliver game-changing performance improvements for Apache Kafka deployments. With observed CPU usage reductions of up to 45%, P99 latency improvements approaching 20%, and superior price-performance ratios, these upgrades aren’t just incremental—we believe they’re transformational.
Whether you choose the cost-neutral performance boost of Graviton7 or the premium efficiency of Graviton8, you’re positioning your streaming infrastructure for success. Lower latency means faster data processing. Improved CPU efficiency translates to better resource utilization and potential cost savings. Together, these benefits create the foundation for more responsive, scalable, and economical Kafka operations.
The best part? You don’t have to navigate these upgrades alone. NetApp’s expertise and optimization work ensure your transition to newer Graviton nodes is seamless and reliable, so you can focus on what matters most—your data and applications.
Ready to experience these performance gains yourself? Start your free trial on the Instaclustr Console today and discover how optimized Kafka on AWS Graviton can accelerate your streaming workloads. Your infrastructure—and your users—will thank you.