What is ClickHouse
ClickHouse is a column-oriented database management system for online analytical processing (OLAP) queries. Developed by Yandex, it delivers high performance and processes large blocks of data efficiently.
Unlike traditional row-oriented databases, ClickHouse stores data by columns, optimizing read times for complex queries. A common use case for ClickHouse is large-scale data analytics, due to its ability to handle massive data volumes rapidly.
ClickHouse’s open-source nature allows for flexibility in development environments. The tool supports SQL queries, enabling easy integration with existing systems. It is useful in situations requiring real-time analytics and reporting, often in industries such as finance and retail.
ClickHouse is licensed under the Apache 2.0 open-source license. It has received over 36,000 GitHub stars and has more than 1500 contributors. You can get ClickHouse at the official GitHub repo.
This is part of a series of articles about ClickHouse
Key features of ClickHouse
The following capabilities make ClickHouse useful for large-scale data analytics:
- Columnar storage: Stores data by columns rather than rows. This structure optimizes read operations for analytical queries, as only the required columns are read from disk, reducing I/O overhead and increasing query speed.
- Real-time data ingestion: Supports real-time data ingestion, allowing it to handle high-velocity data streams. This makes it suitable for environments requiring up-to-the-minute analytics, such as monitoring systems or financial markets.
- Distributed and scalable architecture: Scales horizontally across multiple nodes, distributing data and queries across a cluster. This distributed nature enables it to handle petabytes of data while maintaining high performance.
- Data compression: Uses compression algorithms, including LZ4 and ZSTD, to minimize storage space and reduce the amount of data that needs to be read from disk during queries. This saves disk space and improves query performance.
- Vectorized query execution: Processes data in batches rather than row by row. This method takes advantage of modern CPU architectures, leading to faster query execution, especially for complex aggregations and transformations.
- SQL support with extensions: Supports standard SQL, while also extending SQL with features like array joins, nested data structures, and window functions, providing more flexibility in query formulation.
- Ecosystem and integrations: Has a rich ecosystem of tools and integrations, including support for Kafka for real-time data ingestion, integration with Grafana for visualization, and connectors for various data formats like JSON, Parquet, and ORC.
Related content: Read our guide to ClickHouse cluster
Tutorial 1: ClickHouse quick start
This quick start guide will help you set up ClickHouse on your local machine and perform basic operations like creating a table, inserting data, and running queries. These instructions are adapted from the ClickHouse documentation.
Installing ClickHouse
ClickHouse can run on Linux, FreeBSD, macOS, and Windows via WSL.
- To download ClickHouse, use the following curl command, which will detect your OS and download the appropriate binary:
1curl https://clickhouse.com/ | sh
- Once the binary is downloaded, you can start the ClickHouse server by executing:
1./clickhouse server
- To interact with the ClickHouse server, you need to use the
clickhouse-client. Open a new terminal window, navigate to the directory containing the ClickHouse binary, and run:1./clickhouse client
- If the client successfully connects to the server, you’ll see a smiling face, confirming the connection.
1my-host :)
Setting up a table
In ClickHouse, querying a table is similar to other SQL databases, with one key addition: the ENGINE clause. This clause defines how the data will be stored and managed. Here’s an example of creating a simple table:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE room_service_orders ( id UInt32, room_number String, food_order String, amount Float32, timestamp DateTime ) ENGINE = MergeTree PRIMARY KEY (id, timestamp); |

In this example, the MergeTree engine is used, which is optimized for handling large volumes of data. The PRIMARY KEY specifies the columns used to sort the data within the table, optimizing query performance.
Inserting data into the table
Insert data into the ClickHouse table using the standard INSERT INTO command. Note that each insertion creates a new part in the storage, so it’s more efficient to insert data in bulk. Here’s an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
INSERT INTO room_service_orders (id, room_number, food_order, amount, timestamp) VALUES (1, '101', 'Burger and Fries', 15.50, '2024-09-11 08:30:00'); INSERT INTO room_service_orders (id, room_number, food_order, amount, timestamp) VALUES (2, '102', 'Pizza Margherita', 12.00, '2024-09-11 09:00:00'); INSERT INTO room_service_orders (id, room_number, food_order, amount, timestamp) VALUES (3, '103', 'Caesar Salad', 9.75, '2024-09-11 10:15:00'); INSERT INTO room_service_orders (id, room_number, food_order, amount, timestamp) VALUES (4, '104', 'Club Sandwich', 11.25, '2024-09-11 12:00:00'); INSERT INTO room_service_orders (id, room_number, food_order, amount, timestamp) VALUES (5, '105', 'Pasta Carbonara', 14.00, '2024-09-11 13:45:00'); |
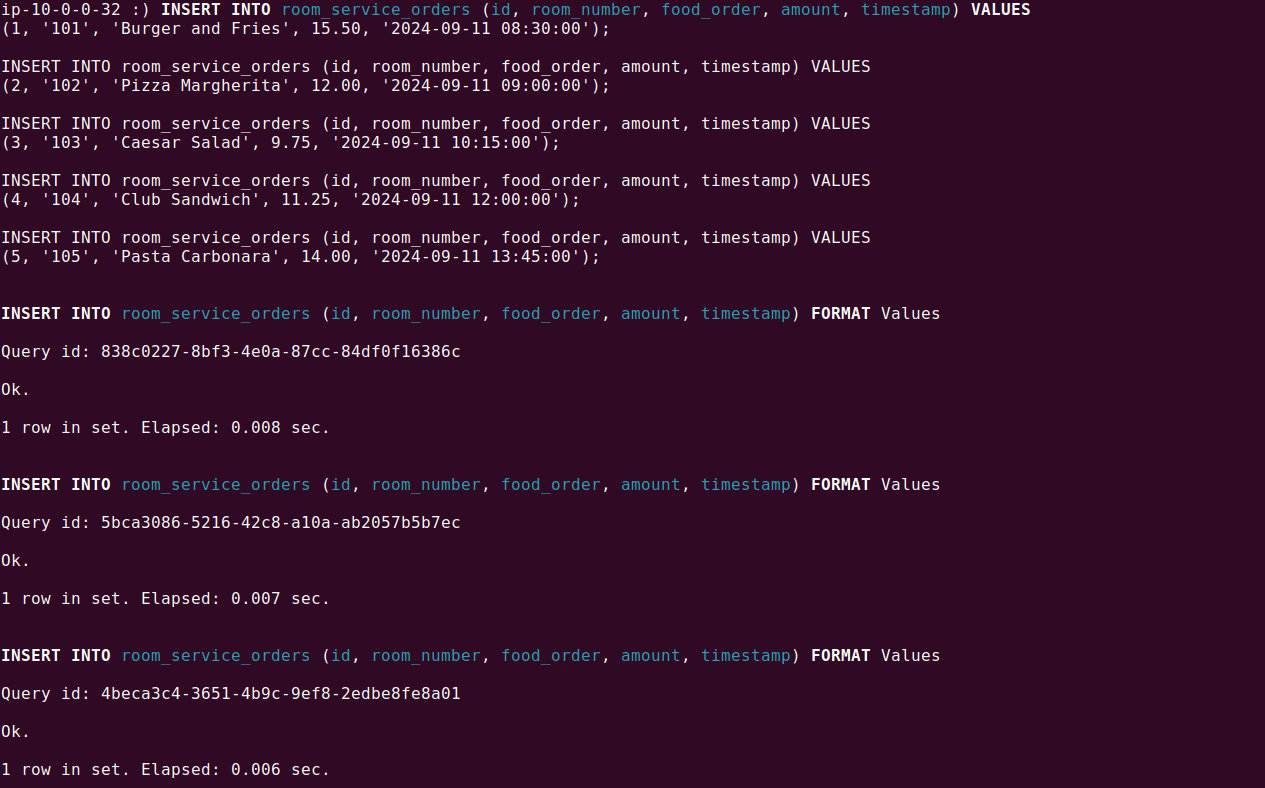
This command inserts multiple rows into the table. For optimal performance, especially with the MergeTree engine, it’s best to insert tens of thousands or even millions of rows at a time.
You can retrieve all records from the table and order them by the timestamp column:
|
1 2 3 |
SELECT * FROM room_service_orders ORDER BY timestamp; |
The results will be displayed in a table format:
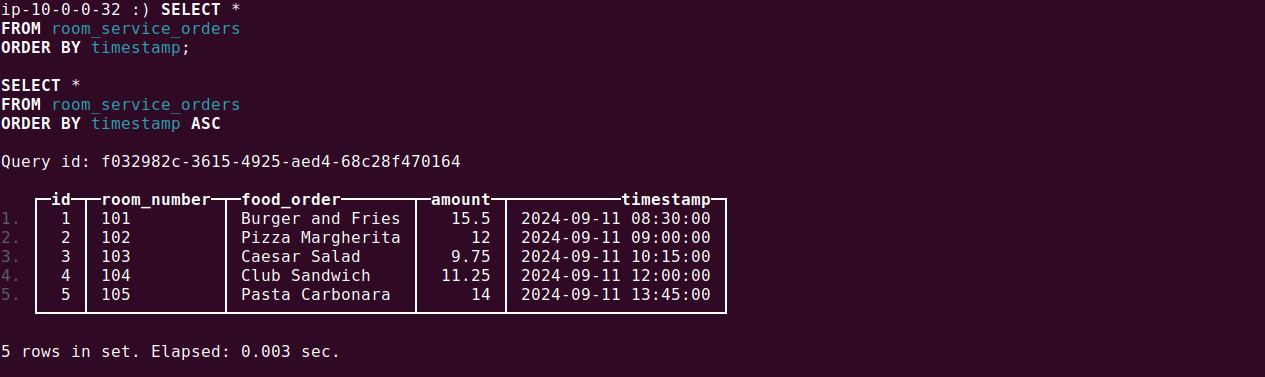
Once you’re familiar with the basics, you can begin inserting your own data. ClickHouse provides a variety of integrations and table functions for importing data from different sources, including S3, MySQL, and PostgreSQL.
For example, you can use the s3 table function to read data directly from an S3 bucket:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT toStartOfMonth(Date) AS month, toYear(Date) AS year, MIN(Open) AS min_open FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/aapl_stock.csv', 'CSVWithNames') GROUP BY month, year ORDER BY year, month LIMIT 30; |

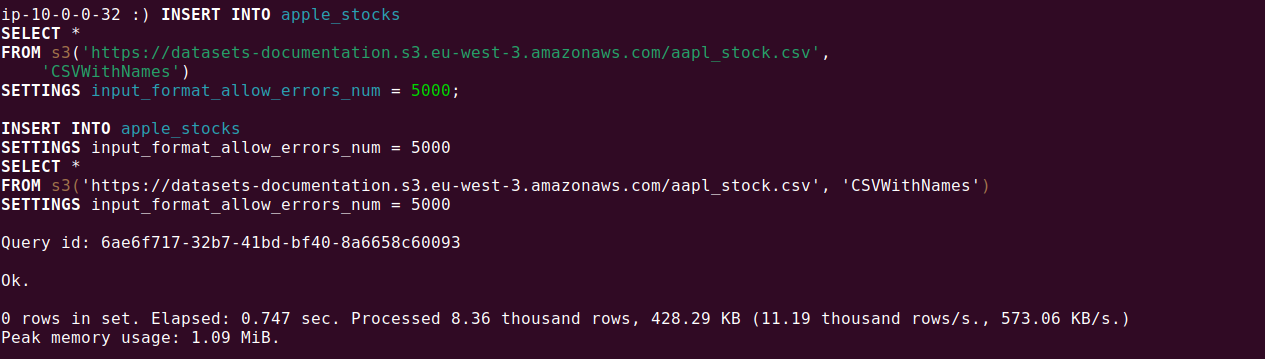
To move this data into a ClickHouse table, you can use the following command:
|
1 2 3 4 |
INSERT INTO apple_stocks SELECT * FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/aapl_stock.csv', 'CSVWithNames') SETTINGS input_format_allow_errors_num = 5000; |
Tips from the expert

Andrew Mills
Senior Solution Architect
Andrew Mills is an industry leader with extensive experience in open source data solutions and a proven track record in integrating and managing Apache Kafka and other event-driven architectures
In my experience, here are tips that can help you better utilize ClickHouse for large-scale data processing and analytics:
- Take advantage of ClickHouse’s asynchronous insert mode: If you’re dealing with high-velocity data ingestion, use the
async_insertandasync_insert_max_data_sizesettings to optimize throughput. These settings queue inserts asynchronously, reducing client-server latency. - Bulk inserts for better storage efficiency: Avoid frequent small inserts. Batch data into large blocks (100,000 rows or more) for insertion. This reduces the overhead of part merges and improves compression ratios, saving both storage space and write time.
- Optimize MergeTree settings for your workload: Fine-tune parameters such as
index_granularity,merge_with_ttl_timeout, andmax_part_size_for_mergein the MergeTree engine. These settings can significantly improve performance for both read-heavy and write-heavy workloads. - Use materialized views for real-time aggregation: Materialized views can automate data pre-aggregation, which boosts query performance for real-time dashboards. They allow you to aggregate metrics as data is ingested, reducing the need for heavy on-the-fly calculations.
- Leverage ClickHouse’s data skipping indices: Use primary and secondary indices (like
minmaxorbloom_filterindexes) to skip over large parts of the dataset during query execution. This can drastically reduce the amount of data that needs to be read and processed, especially in large tables.
Tutorial 2: Managing and analyzing a large dataset
In this section, we’ll explore how to manage and analyze large datasets using ClickHouse. We will use a real-world example by working with global airline flight data, which contains millions of records.
Creating and populating a table
- First, we’ll create a table to store flight data. This dataset includes details like flight number, airline, departure and arrival times, airports, and flight durations. Below is the SQL command to create the
amazon_reviewstable:123456789101112131415161718192021CREATE TABLE amazon_reviews(id UUID DEFAULT generateUUIDv4(),review_date UInt32,marketplace String,customer_id UInt64,review_id String,product_id String,product_parent UInt64,product_title String,product_category String,star_rating UInt8,helpful_votes UInt32,total_votes UInt32,vine Bool,verified_purchase Bool,review_headline String,review_body String)ENGINE = MergeTreePRIMARY KEY (id);
This table is designed to handle and store the data, leveraging the MergeTree engine, which is optimal for managing large datasets. - Next, we’ll insert a large dataset into this table. The dataset consists of approximately two million rows of flight data. Here’s how you can insert the data directly from files stored in an S3 bucket:
1234INSERT INTO amazon_reviewsSELECT *FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/amazon_reviews/amazon_reviews_1990s.snappy.parquet')SETTINGS input_format_allow_errors_num = 5000;

This command reads data from the specified S3 URLs and inserts it into the amazon_reviews table. ClickHouse handles the large data volumes, ensuring the entire dataset is ingested quickly.
Analyzing data with ClickHouse
Once the data is loaded, you can begin performing various analytical queries:
- Start by computing the average total fare for all flights:
1SELECT avg(star_rating) FROM amazon_reviews
- Next, let’s calculate the average number of helpful and total votes by category
12345678910SELECTproduct_category,AVG(helpful_votes) AS avg_helpful_votes,AVG(total_votes) AS avg_total_votesFROMamazon_reviewsGROUP BYproduct_categoryORDER BYavg_helpful_votes DESC;

- You can also perform more complex calculations, such as analyzing the helpful votes for verified and unverified purchases with star rating of 4 or better:
12345678910111213SELECTproduct_category,SUM(helpful_votes) AS total_helpful_votes,SUM(verified_purchase = 1 AND star_rating > 4) AS verified_helpful_votes,SUM(verified_purchase = 0 AND star_rating > 4) AS unverified_helpful_votesFROMamazon_reviewsWHEREstar_rating > 4GROUP BYproduct_categoryORDER BYtotal_helpful_votes DESC;

This query groups trips by their duration, providing averages for tips, fares, and passenger counts.
Leveraging dictionaries and performing joins
ClickHouse supports the use of dictionaries, which are mappings of key-value pairs stored in memory, enabling faster lookups during queries:
- Create a dictionary based on a CSV file containing VERIFIED / UN-VERFIED orders key values pairs:
123456789CREATE DICTIONARY verified_status_dict(status UInt8,label String)PRIMARY KEY statusSOURCE(FILE(path './user_files/enum.csv' format 'CSVWithNames'))LAYOUT(FLAT())LIFETIME(MIN 300 MAX 3600);
Note enum.csv file resides in the same folder and has the following structure:
123status,label1,VERIFIED0,UN-VERIFIED
This dictionary can then be used in queries to join with theamazon_reviewstable or retrieve specific values. - For example, to perform a join using the newly created dictionary:
123456789101112SELECTproduct_category,dictGetString('verified_status_dict', 'label', toUInt8(verified_purchase)) AS purchase_status,SUM(helpful_votes) AS total_helpful_votesFROM amazon_reviewsGROUP BYproduct_category,purchase_statusORDER BYproduct_category ASC,purchase_status ASCLIMIT 15
This query identifies the number of helpful votes by verification status by joining the table with a dictionary.
Related content: Read our guide to ClickHouse architecture
Efficiency and scalability amplified: The benefits of Instaclustr for ClickHouse
Instaclustr provides a range of benefits for ClickHouse, making it an excellent choice for organizations seeking efficient and scalable management of these deployments. With its managed services approach, Instaclustr simplifies the deployment, configuration, and maintenance of ClickHouse, enabling businesses to focus on their core applications and data-driven insights.
Some of these benefits are:
- Infrastructure provisioning, configuration, and security, ensuring that organizations can leverage the power of this columnar database management system without the complexities of managing it internally. By offloading these operational tasks to Instaclustr, organizations can save valuable time and resources, allowing them to focus on utilizing ClickHouse to its full potential.
- Seamless scalability to meet growing demands. With automated scaling capabilities, ClickHouse databases can expand or contract based on workload requirements, ensuring optimal resource utilization and cost efficiency. Instaclustr’s platform actively monitors the health of the ClickHouse cluster and automatically handles scaling processes, allowing organizations to accommodate spikes in traffic and scale their applications effectively.
- High availability and fault tolerance for ClickHouse databases. By employing replication and data distribution techniques, Instaclustr ensures that data is stored redundantly across multiple nodes in the cluster, providing resilience against hardware failures and enabling continuous availability of data. Instaclustr’s platform actively monitors the health of the ClickHouse cluster and automatically handles failover and recovery processes, minimizing downtime and maximizing data availability for ClickHouse deployments.
Furthermore, Instaclustr’s expertise and support are invaluable for ClickHouse databases. Our team of experts has deep knowledge and experience in managing and optimizing ClickHouse deployments. We stay up-to-date with the latest advancements in ClickHouse technologies, ensuring that the platform is compatible with the latest versions and providing customers with access to the latest features and improvements. Instaclustr’s 24/7 support ensures that organizations have the assistance they need to address any ClickHouse-related challenges promptly.
For more information: