What are hosted Apache Kafka services?
A hosted Apache Kafka service, often referred to as managed Apache Kafka or Kafka as a Service (KaaS), is a cloud-based solution where a third-party provider manages the infrastructure and operational aspects of an Apache Kafka cluster. This service allows organizations to leverage Kafka’s capabilities for real-time data streaming without the complexities of self-managing a distributed system.
Hosted Apache Kafka services typically offer an interface for cluster setup, scaling options, automated failover, and integrated monitoring tools. Users interact with Kafka clusters via standard APIs, but the underlying operational details, like uptime guarantees, patch management, and incident handling, are managed by the service provider.
Key features and benefits of a hosted Apache Kafka service include:
- Simplified management: The service provider handles tasks such as installation, configuration, patching, upgrades, and ongoing maintenance, reducing the operational burden on the user.
- Scalability and high availability: Managed services typically offer automated scaling capabilities to accommodate fluctuating data volumes and ensure high availability through features like automatic broker replacement and data replication.
- Reduced operational cost and expertise: By outsourcing the management to a specialized provider, organizations can minimize the need for in-house Kafka expertise and reduce the total cost of ownership.
- Focus on application development: Users can concentrate on building and deploying applications that utilize Kafka, rather than expending resources on infrastructure management.
- Security and compliance: Reputable providers offer robust security measures and often adhere to industry compliance standards, ensuring data protection and regulatory adherence.
- Monitoring and support: Hosted services usually include comprehensive monitoring tools and dedicated support from experts to assist with performance tuning, troubleshooting, and other operational concerns.
Editor’s note: Updated the article to cover generative AI use cases of managed Kafka, updated information about features and capabilities of Kafka services in 2026, and added one new service.
Key features and benefits of a hosted Apache Kafka service
Simplified management
One of the main advantages of hosted Apache Kafka services is the reduction in administrative overhead. Deploying and operating Kafka involves configuring Zookeeper (or its alternatives), managing partitions, balancing loads, and ensuring system health. With a managed service, these tasks are largely automated or made accessible through dashboards and APIs. This means that teams do not need to maintain deep expertise in Kafka internals.
Service providers usually offer features such as one-click cluster creation, configuration tuning, and automated backups, making it easy for organizations to get started and maintain reliable operations over time. Regular tasks such as patching, upgrading, and failover management are handled in the background.
Scalability and high availability
Hosted Kafka services scale to accommodate fluctuating workloads, which is essential for data pipelines that handle variable traffic patterns. Providers generally offer options to adjust the number of brokers, memory, and storage dynamically without service downtime.
High availability is another cornerstone, with managed Kafka solutions implementing automated failover, replication, and distributed storage. Providers often offer service-level agreements (SLAs) guaranteeing uptime and data durability.
Reduced operational cost and expertise
Operating Kafka clusters in-house demands significant investments in engineering time, both to set up the environment and to keep it running optimally. Hosted services help reduce these operational costs by centralizing expertise and automating much of the routine work. Teams can avoid expenses related to recruiting and retaining specialized Kafka administrators, as well as costs related to hardware, networking, and maintenance.
Additionally, managed services often use economies of scale to deliver reliable infrastructure at a lower cost than individual organizations could achieve on their own. The pay-as-you-go or subscription pricing models typically mean customers only pay for the resources they use.
Focus on application development
Hosted Kafka services allow engineering teams to prioritize building features and addressing business problems, rather than managing infrastructure. Developers spend less time troubleshooting Kafka clusters or worrying about version compatibility and cluster upgrades. This shift in focus accelerates innovation by allowing teams to iterate on products faster and experiment with new event-driven patterns.
By abstracting away much of the underlying complexity, managed services also lower the barrier to entry for organizations adopting real-time streaming architectures. Teams with limited Kafka experience can reliably build and deploy scalable data pipelines, event-driven microservices, or data integration workflows.
Security and compliance
Security is a top concern for any data platform, and enterprise-grade hosted Kafka services typically offer security features. These include encryption at rest and in transit, access controls, support for authentication protocols such as SSL/TLS and SASL, and integrations with identity providers for single sign-on. Managed services often stay ahead on security patching, proactively updating clusters to address new vulnerabilities.
For organizations with regulatory requirements, many Kafka providers offer compliance certifications (SOC 2, HIPAA, GDPR, etc.) and tools for managing audit logs, data retention policies, and secure networking.
Monitoring and support
Monitoring is critical for maintaining system health and resolving issues before they escalate. Hosted Kafka services provide integrated dashboards to track metrics such as throughput, latency, consumer lag, and broker health. Alerting systems can notify teams of anomalies, often before they affect application performance. These observability tools are designed to be user-friendly and accessible to both Kafka novices and experts.
In addition to monitoring, managed Kafka providers offer expert support, often with 24/7 availability and guaranteed response times. This support is vital for production systems, enabling organizations to quickly resolve incidents, request help with architectural questions, or access best-practice guidance.
How are hosted Apache Kafka services used for generative AI?
Hosted Apache Kafka services play a critical role in enabling Generative AI (GenAI) applications by providing a scalable, real-time data streaming backbone that connects data sources, AI models, and downstream systems. Instead of building complex streaming infrastructure from scratch, organizations can use managed Kafka to power AI-driven workflows with continuous, reliable data flows.
One of the key requirements of Generative AI systems is access to fresh, high-quality data in real time. Kafka fulfills this need by acting as a central data pipeline that ingests, processes, and distributes streaming data across the AI ecosystem. This allows large language models (LLMs) and other generative systems to operate on up-to-date information, improving relevance and accuracy.
Hosted Kafka services simplify this architecture by removing the operational burden while still supporting advanced AI use cases. For example, Kafka can stream user inputs, logs, or external data into AI models for tasks such as real-time content generation, sentiment analysis, or conversational AI.
Hosted Kafka services provide the following technical capabilities to support generative AI:
- Real-time data ingestion and processing: Kafka continuously captures streams of data (text, events, user activity) and delivers them to AI models with low latency, enabling real-time inference and responses.
- Data enrichment and transformation: Streaming pipelines can clean, filter, and enrich incoming data before it reaches GenAI models, improving output quality.
- Event-driven AI architectures: Kafka enables loosely coupled systems where AI components react to events (e.g., user queries, transactions), supporting scalable and modular GenAI applications.
- Continuous learning and model updates: Real-time streams can feed models for ongoing training or adaptation, helping AI systems stay current with changing data patterns.
- Integration across systems: Kafka connects databases, APIs, vector stores, and AI services, acting as a “data fabric” for modern AI pipelines.
Notable hosted Apache Kafka services
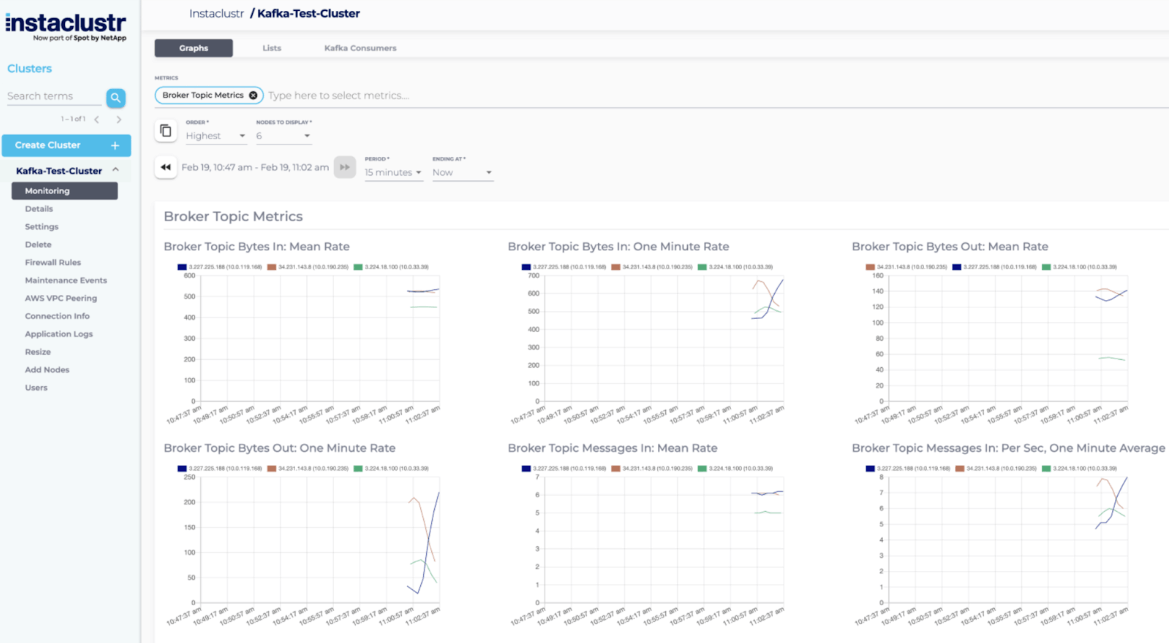
1. NetApp Instaclustr
![]()
Instaclustr for Kafka is a fully managed Apache Kafka streams data in real time without the headaches of operating complex infrastructure. Built for reliability, it delivers high availability, automated failover, and proactive monitoring so data pipelines stay up and running. It scales seamlessly as throughput and topics grow, providing consistent performance from pilot to production. And with expert support, streamlined provisioning, and built-in best practices, Instaclustr makes Kafka easier to adopt and operate—so organizations can focus on building real-time applications, not managing clusters.
- High availability and automated failover: Keeps streams running during outages so you avoid downtime and lost messages.
- Seamless horizontal scalability: Adds brokers and storage on demand to handle traffic spikes without re-architecting.
- End-to-end security: Encrypts data in transit and at rest, with role-based access control and private networking to protect sensitive workloads.
- Proactive monitoring and alerting: Tracks broker health, lag, and throughput with actionable alerts so issues can be fixed before they impact users.
- Managed upgrades and patching: Applies tested Kafka and OS updates, reducing risk and freeing teams up from maintenance windows.
- Performance tuning out of the box: Uses proven configurations for partitions, replication, and retention to deliver consistent low latency.
- Self-service provisioning: Launches clusters in minutes with guided defaults, cutting setup time and complexity.
- Expert 24/7 support: Access to Kafka specialists for architecture reviews and incident response to keep data pipelines healthy.
- Multi-cloud deployment: Deploy where needed to meet latency, data residency, and cost goals.
- Compliance-ready operations: Built-in controls and auditability to help meet industry standards and internal policies.
2. Confluent Cloud
![]()
Confluent Cloud is a managed Apache Kafka service built on a cloud-native architecture that abstracts infrastructure management while supporting data streaming at scale. It provides a unified platform for ingesting, processing, and connecting data streams across environments, with built-in capabilities for governance, integration, and analytics.
Key features include:
- Cloud-native Kafka engine: Uses a managed Kafka engine designed for elastic scaling and efficient resource utilization.
- Autoscaling clusters: Adjusts compute and storage dynamically based on workload demand to optimize performance and cost.
- Multi-cloud and multi-region support: Enables data replication and synchronization across clouds and regions using cluster linking.
- Managed connectors ecosystem: Provides pre-built and managed connectors for integrating with databases, data lakes, and analytics systems.
- Built-in data governance: Supports data processing, validation, and governance closer to the data source.
- Stream-to-table integration: Converts streaming data into table formats such as Apache Iceberg or Delta Lake for analytics workloads.
Source: Confluent
{kind=link}
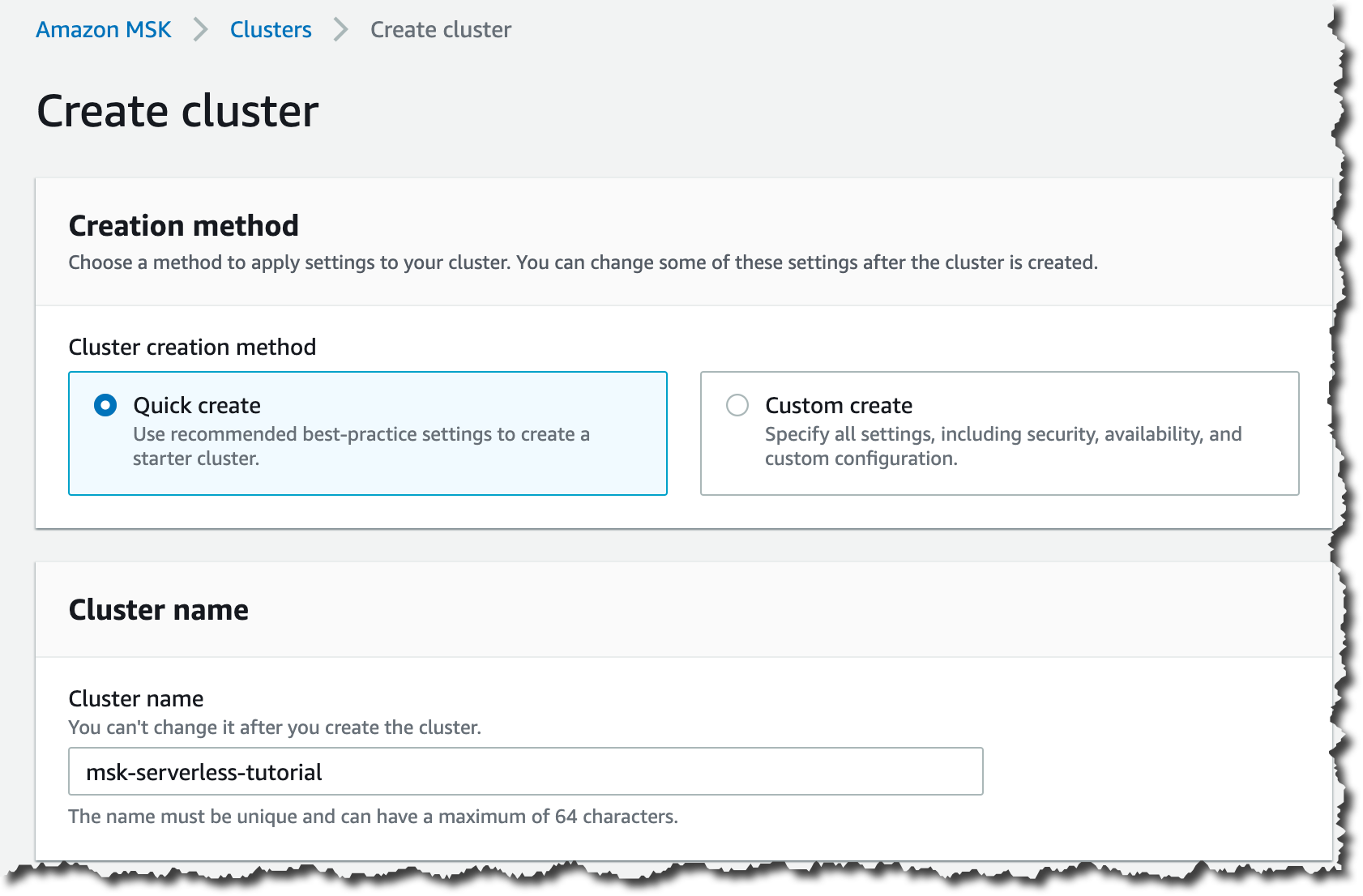
3. Amazon MSK
![]()
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that simplifies running Kafka on AWS by handling cluster provisioning, maintenance, and scaling. It allows developers to build streaming applications without managing Kafka infrastructure while benefiting from integration with other AWS services and built-in security features.
Key features include:
- Fully managed Kafka infrastructure: Handles provisioning, maintenance, and scaling of Kafka clusters.
- High availability and resiliency: Provides fault-tolerant deployments designed for continuous data streaming.
- Integrated AWS ecosystem: Connects with AWS services to support data ingestion, processing, and storage workflows.
- Enterprise-grade security: Includes built-in security features for protecting streaming data.
- Kafka Connect support: Enables running Kafka Connect connectors without managing additional infrastructure.
- Operational simplicity: Reduces the need for Kafka expertise by automating cluster management tasks.
Source: Amazon
{kind=link}
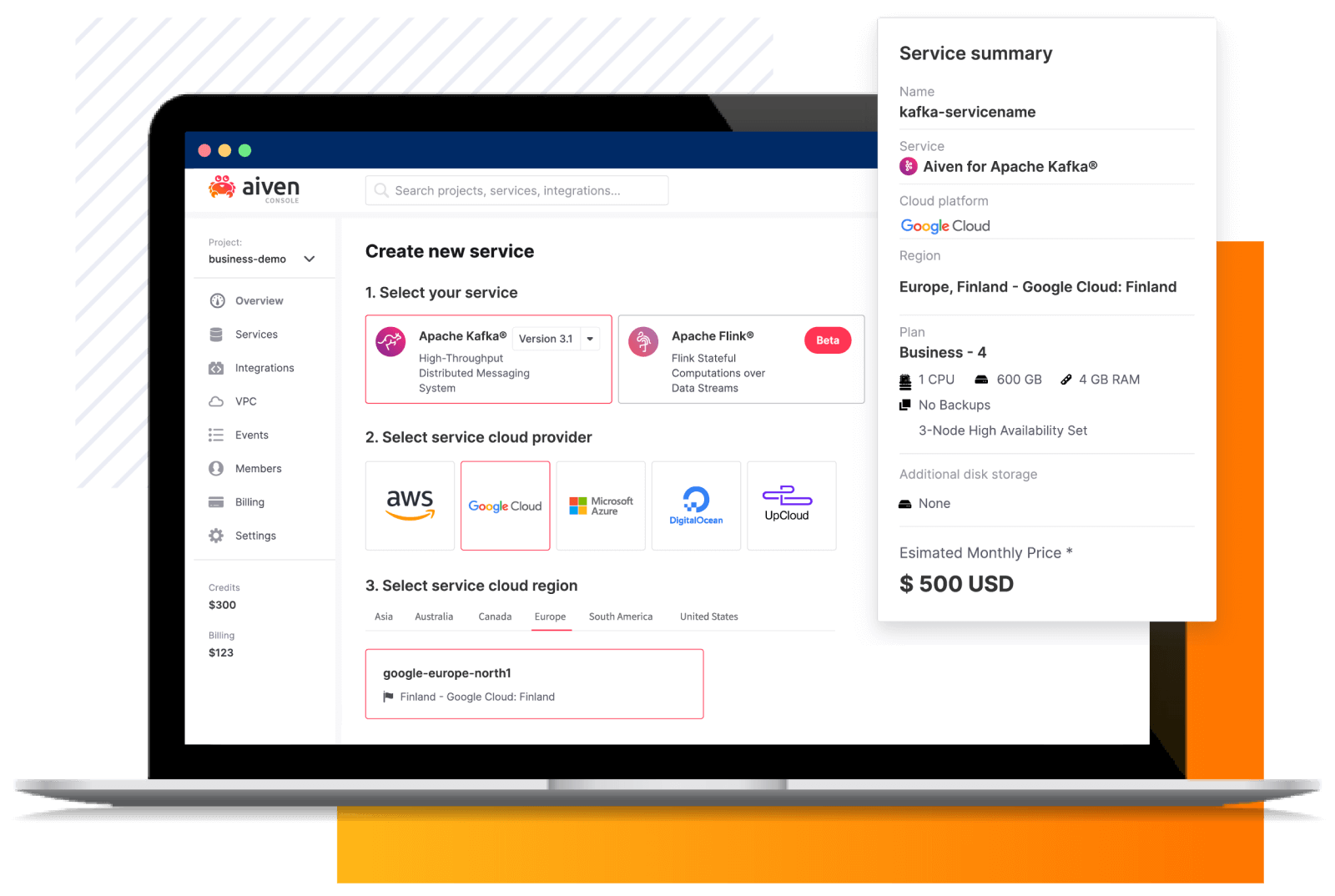
4. Aiven for Apache Kafka
![]()
Aiven for Apache Kafka is a managed Kafka service that provides a cloud-native streaming platform with built-in components for data integration, governance, and scalability. It supports deployment across multiple cloud providers and includes integrated tools for schema management, monitoring, and data flow visualization.
Key features include:
- Multi-cloud deployment: Runs on major cloud providers, allowing flexible placement and migration of Kafka clusters.
- Integrated schema registry: Enforces data consistency and compatibility using a managed schema registry.
- Tiered storage support: Separates compute and storage to enable scalable retention and cost optimization.
- Automatic failover and recovery: Uses multi-node clusters with self-healing capabilities to maintain availability.
- Managed connectors and replication: Includes tools such as MirrorMaker 2 for data movement across clusters.
- Monitoring and lag detection: Provides insights into consumer lag and system performance.
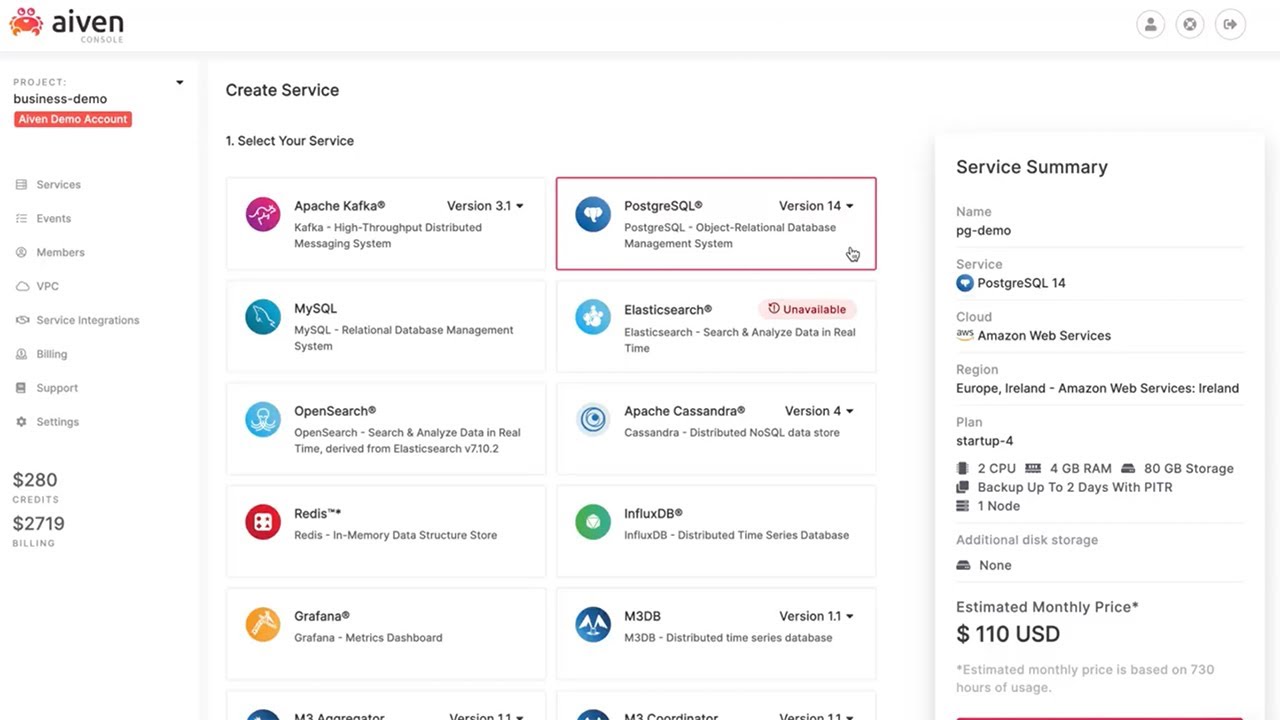
Source: Aiven
{kind=link}
5. Redpanda Cloud
![]()
Redpanda Cloud is a managed streaming platform compatible with the Kafka API, helping provide high performance and simplified operations without requiring external dependencies. It supports multiple deployment models, including bring-your-own-cloud (BYOC), dedicated clusters, and serverless options, allowing flexibility in how infrastructure is managed and where data is stored.
Key features include:
- Kafka API compatibility: Works with existing Kafka clients, tools, and ecosystems without modification.
- Multiple deployment models: Supports BYOC, dedicated, and serverless clusters for different operational needs.
- Automated cluster operations: Handles provisioning, upgrades, patching, and partition balancing.
- Tiered storage: Reduces storage costs by offloading older data while maintaining access.
- Built-in connectors: Integrates with common data systems such as databases and cloud storage services.
- Data sovereignty controls: Enables deployment within a user’s own cloud environment for greater control over data.
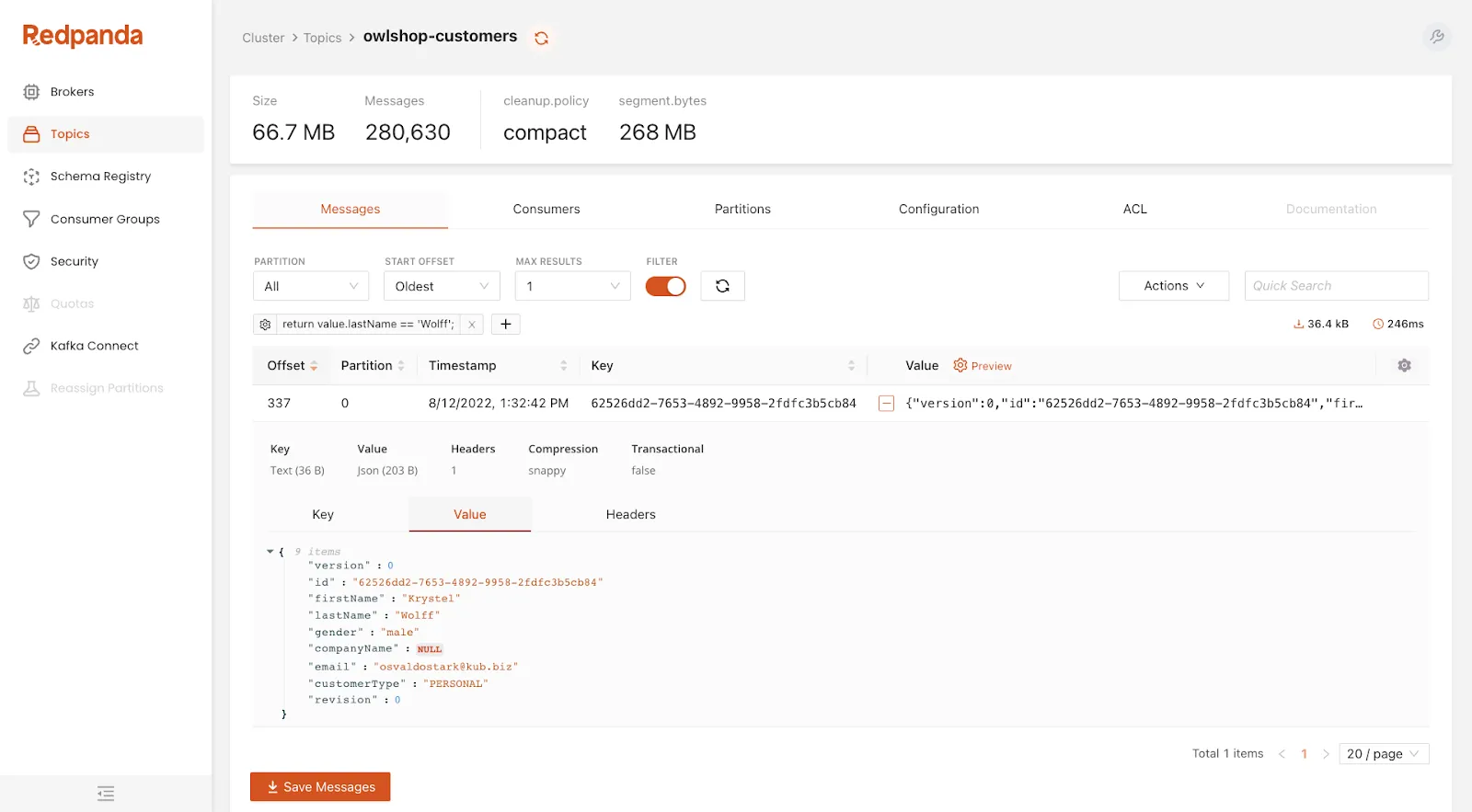
Source: Redpanda
{kind=link}
6. Azure Event Hubs for Apache Kafka
![]()
Azure Event Hubs for Apache Kafka is a managed event streaming service that provides a Kafka-compatible endpoint, allowing existing Kafka applications to run without managing Kafka clusters. Instead of deploying brokers and handling infrastructure, users connect to Event Hubs using the Kafka protocol and stream data through a fully managed, cloud-native platform.
Key features include:
- Kafka protocol compatibility: Supports Kafka APIs, enabling applications to connect with minimal or no code changes by updating configuration.
- Fully managed service: Eliminates the need to manage brokers, storage, or networking infrastructure.
- Elastic scaling model: Scales throughput using throughput units or processing units, with optional auto-scaling capabilities.
- Partitioned streaming architecture: Uses partitioned logs similar to Kafka topics, allowing parallel data processing and consumer group coordination.
- Security and authentication: Supports TLS encryption and SASL mechanisms, including OAuth 2.0 and shared access signatures for access control.
- Multi-protocol support: Allows data ingestion and consumption via Kafka, AMQP, or HTTP, enabling flexible integration patterns.
- Integration with Azure services: Works with tools such as Azure Stream Analytics, Synapse Analytics, and Databricks for stream processing.
Source: Microsoft
{kind=link}
Conclusion
Hosted Apache Kafka services provide a streamlined way to adopt real-time streaming without the complexity of deploying and maintaining distributed infrastructure. By combining automated operations, elastic scalability, built-in security, and expert support, these platforms enable organizations to focus on building data-driven applications and architectures. The result is faster project delivery, reduced operational risk, and the flexibility to scale seamlessly as data volumes and business requirements evolve.