What is a vector database?
A vector database is a data storage system used to manage, index, and query high-dimensional vector data. Vectors, in this context, represent data points in multi-dimensional space, often used in machine learning, data mining, and other advanced analytical applications.
Vector databases are useful in tasks involving the computation of distances or similarities between vectors, such as recommendation systems, image and video recognition, and natural language processing.
Unlike traditional databases that manage structured rows and columns, vector databases handle more complex, high-dimensional data representations, which are essential for applications requiring efficient similarity searches and pattern recognition. Some general purpose databases, such as PostgreSQL and Cassandra, now support both traditional data formats and vector data.
Further in this article, we’ll provide more details on 5 dedicated open source vector databases and 5 popular general purpose databases that provide vector database functionality.
This is part of a series of articles about vector databases
Editor’s note: Updated the article to cover recent market trends, updated product information to reflect features and capabilities in 2026.
See how easy it is to set up your first PostgreSQL or Cassandra clusters
Understanding the Vector Databases Market Trends
Vector Database Market Growth
The vector database market is growing quickly as organizations adopt artificial intelligence and machine learning systems that rely on high-dimensional vector data. The global market size is estimated at USD 2.58 billion and is projected to reach USD 17.91 billion by 2034, with a compound annual growth rate (CAGR) of 24%.
This growth is driven by the increasing use of AI applications such as semantic search, recommendation engines, fraud detection, personalization systems, and generative AI tools. Vector databases are becoming a core part of AI infrastructure because they are optimized for storing embeddings and performing similarity searches on large volumes of unstructured data.
North America currently leads the market with 41% share, followed by Europe at 27% and Asia-Pacific at 23%. The United States is the largest and most mature market due to strong AI adoption, cloud infrastructure, and investment in generative AI technologies.
Key Trends in the Vector Database Market
- The vector database market is moving from early experimentation into production-grade AI infrastructure:
- The biggest trend remains the use of vector databases in retrieval-augmented generation (RAG), enterprise search, AI copilots, and agentic AI workflows.
Hybrid search is now a core requirement rather than a niche feature. Enterprises are combining vector similarity search with keyword search, metadata filtering, SQL-style queries, graph relationships, and reranking models. - Modern AI applications convert text, images, audio, video, and behavioral signals into embeddings so that systems can identify similarity, context, intent, and relationships. This has increased demand for vector databases in sectors such as financial services, healthcare, retail, media, cybersecurity, manufacturing, and enterprise software.
- Companies are using vector databases to connect LLMs with internal documents, product data, customer records, policies, knowledge bases, and support tickets. This enables AI assistants and copilots to answer questions using current organizational knowledge rather than relying only on pre-trained model memory.
Major Use Cases for Vector Databases
The largest use cases include:
- Natural language processing: Organizations use vector databases for semantic search, enterprise knowledge retrieval, AI chatbots, document classification, summarization, sentiment analysis, compliance search, and customer support automation. In these applications, language embeddings help systems understand meaning and context rather than relying only on keyword matching.
- RAG and AI copilots: Vector databases help retrieve relevant internal content for LLMs, allowing AI tools to generate more accurate, contextual, and traceable responses. These systems are being used in legal research, customer service, software engineering, sales enablement, HR support, analytics, and internal knowledge management.
- Computer vision: Vector databases support image and video similarity search, visual product discovery, facial recognition, medical imaging analysis, content moderation, surveillance analytics, and brand/logo detection. As multimodal AI models improve, visual and cross-modal search are becoming more valuable for retailers, healthcare providers, media companies, and security teams.
- Recommendation systems: e-Commerce platforms, streaming services, marketplaces, and media companies use user, product, content, and behavior embeddings to generate personalized recommendations in real time. Vector search helps match users with similar products, videos, articles, songs, or services based on intent and behavioral patterns.
Key features of open source vector databases
Open-source vector databases typically include the following features:
- Efficient indexing: Indexing mechanisms such as Approximate Nearest Neighbor (ANN) searches reduce the time required to find similar vector representations, useful for applications involving real-time data analysis.
- Similarity search: This feature finds vectors that are close to a given query vector in high-dimensional space, based on measures like Euclidean distance and cosine similarity. It is essential for applications like recommendation engines, where the system needs to identify items similar to the user’s preferences. Open-source vector databases often used algorithms to perform these searches accurately.
- Scalability: As organizations collect more high-dimensional data, the database must efficiently manage this increase without compromising performance. Open-source solutions often offer distributed architectures that help in scaling out, ensuring consistent response times even as data volumes expand.
- Integration with machine learning libraries: Open-source vector databases often work with popular machine learning frameworks, allowing for simple deployment of machine learning models directly on the database. This enables the direct application of learned models to the stored data for real-time analysis and predictions.
- Community and support: An open-source community can provide assistance through forums, documentation, or contributions to the codebase. These databases often benefit from active communities that help in troubleshooting, feature enhancements, and providing comprehensive usage guides.
Related content: Read our guide to vector database use cases
Tips from the expert

Ritam Das
Solution Architect
Ritam Das is a trusted advisor with a proven track record in translating complex business problems into practical technology solutions, specializing in cloud computing and big data analytics.
In my experience, here are tips that can help you better utilize open-source vector databases:
- Monitor memory usage: Ensure your vector indexes fit within available memory. If you use PostgreSQL with the pgvector extension you can ensure this by setting the appropriate maintenance_work_mem. Vector data can grow large, and exceeding available memory during indexing can drastically increase build times.
- Understand your indexing algorithms: Use specialized vector indexes like HNSW (Hierarchical Navigable Small Worlds) or IVFFlat (Inverted File with Flat Compression) for fast approximate nearest neighbor (ANN) search. HNSW is ideal for most use cases. It features high query performance and its indexing structure adapts to dataset evolution because it is based on graphs, while IVFFlat is better for memory efficiency and lower build times.
- Incorporate vector quantization: Utilize scalar quantization to reduce 4-byte floats to 2-byte floats, and binary quantization to reduce the dimensions to a single bit. This dramatically cuts storage costs, especially for large datasets with high-dimensional vectors.
- Monitor vector database performance: Implement monitoring and logging tools to track the performance of your vector database, particularly during high-load periods. This can help in identifying bottlenecks and optimizing query strategies in real-time.
Open source vector databases
Here are some of the most popular open source vector databases.
1. OpenSearch
![]()
OpenSearch is an Apache 2.0-licensed search and analytics suite built on Apache Lucene. Its Vector Engine stores, indexes, and searches embeddings for similarity search, semantic search, hybrid search, multimodal search, sparse vector search, RAG, recommendations, and anomaly detection.
Repo: https://github.com/opensearch-project/OpenSearch
License: Apache-2.0 license
GitHub stars: ~13K
Contributors: 450+
Key features of OpenSearch:
- Vector embedding storage: Stores and searches high-dimensional embeddings for text, images, audio, and other unstructured data.
- K-nearest neighbor search: Supports similarity search using k-NN techniques.
- Hybrid search support: Combines vector, semantic, sparse, multimodal, and conversational search methods.
- Real-time ingestion and indexing: Uses ingestion pipelines to collect, filter, transform, enrich, and index data.
- GPU-accelerated search: Supports GPU-powered indexing for large-scale vector workloads.
- Query DSL: Provides a JSON-based query language for search operations.
Create your first OpenSearch cluster and get pro tips for success
2. Facebook AI Similarity Search (Faiss)
![]()
Faiss is an open source library developed by Meta for similarity search and clustering of dense vectors. It is written primarily in C++ with Python and NumPy wrappers, and includes algorithms for exact and approximate nearest neighbor search across datasets ranging from small collections to billion-scale vector indexes.
Repo: https://github.com/facebookresearch/faiss
License: MIT license
GitHub stars: 40K+
Contributors: ~250
Key features of Faiss:
- Dense vector similarity search: Supports nearest neighbor search using Euclidean distance, dot product, and cosine similarity.
- Approximate and exact indexing: Includes indexing methods such as HNSW, NSG, binary vectors, and compressed quantization indexes.
- GPU acceleration: Provides GPU implementations for vector indexing and search, including multi-GPU support.
- Compressed vector storage: Supports quantization and compressed representations to reduce memory usage.
- Large-scale indexing: Designed to handle datasets that may not fit entirely in RAM.
- Python and C++ APIs: Includes native C++ implementation with Python wrappers for integration into machine learning workflows.
3. Chroma
![]()
Chroma is an open source vector database for AI applications and embedding-based retrieval. It provides APIs for storing documents, embeddings, metadata, and similarity search operations, with support for local, embedded, and client-server deployments.
Repo: https://github.com/chroma-core/chroma
License: Apache-2.0 license
GitHub stars: 28K
Contributors: 150+
Key features of Chroma:
- Collection-based storage: Organizes vectors and associated documents into collections.
- Automatic embedding workflows: Supports automatic tokenization, embedding generation, and indexing, while also allowing custom embeddings.
- Metadata filtering: Supports filtering queries using structured metadata fields.
- Similarity search APIs: Provides vector and text-based query interfaces for nearest neighbor retrieval.
- Persistent or in-memory deployment: Can run in-memory for prototyping or persist data to disk for longer-term storage.
- Python and JavaScript clients: Supports integration through Python and JavaScript SDKs.
4. Milvus
![]()
Milvus is an open source vector database built for large-scale similarity search and AI workloads. It supports deployments ranging from lightweight local setups to distributed clusters capable of handling billions of vectors.
Repo: https://github.com/milvus-io/milvus
License: Apache-2.0 license
GitHub stars: 40K+
Contributors: 300+
Key features of Milvus:
- Distributed vector storage: Supports horizontal scaling for datasets containing billions of vectors.
- High-speed similarity search: Optimized for retrieval across high-dimensional embeddings.
- Multiple deployment models: Includes lightweight, standalone, and distributed deployment options.
- Metadata and hybrid search: Supports metadata filtering and hybrid retrieval workflows.
- AI framework integrations: Integrates with tools such as LangChain, LlamaIndex, OpenAI, and Hugging Face.
- Python client support: Provides APIs for collection management, insertion, search, and deletion operations.
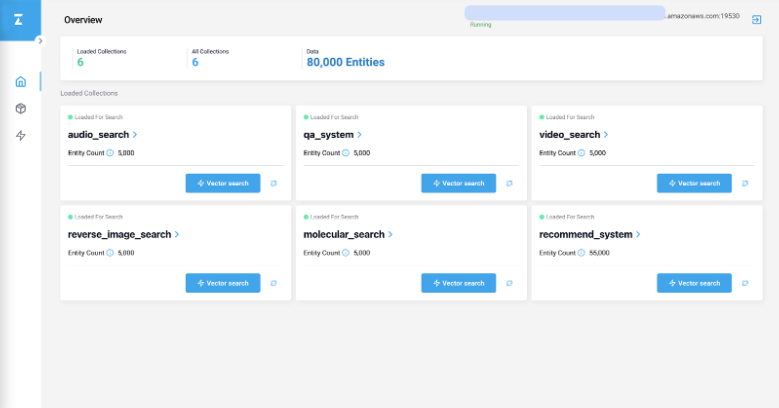
Source: Milvus
{kind=link}
5. Qdrant
![]()
Qdrant is an open source vector search engine written in Rust for real-time AI retrieval and similarity search. It supports dense and sparse vector retrieval, metadata filtering, reranking, and distributed deployment models.
Repo: https://github.com/qdrant/qdrant
License: Apache-2.0 license
GitHub stars: ~30K
Contributors: 150+
Key features of Qdrant:
- Dense and sparse hybrid search: Combines vector and keyword search in a single query pipeline.
- ’etadata filtering: Supports nested, geo, text, and vector-aware filtering conditions.
- Multivector support: Allows multiple vectors to be associated with a single object for multimodal retrieval.
- HNSW-based indexing: Applies filtering during HNSW traversal to reduce latency while maintaining recall.
- Quantization support: Includes scalar, binary, and asymmetric quantization for memory-efficient indexing.
- REST and gRPC APIs: Provides APIs and official clients for multiple programming languages.
Source: Qdrant
{kind=link}
6. Weaviate
![]()
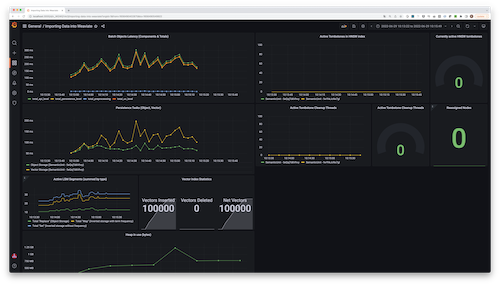
Weaviate is an open source vector database for semantic search, retrieval-augmented generation (RAG), and AI agent workflows. It supports vector, keyword, and hybrid retrieval through REST, GraphQL, and language-specific SDKs.
Repo: https://github.com/weaviate/weaviate
License: BSD-3-Clause license
GitHub stars: 16K+
Contributors: 150+
Key features of Weaviate:
- Semantic and hybrid search: Supports vector, keyword, and combined hybrid retrieval methods.
- Built-in vectorization: Can generate embeddings internally or connect to external ML models.
- GraphQL and REST APIs: Provides multiple query interfaces and SDKs for Python, Go, TypeScript, and JavaScript.
- Multi-tenant architecture: Supports tenant-aware data isolation and indexing.
- Scalable distributed architecture: Designed for workloads ranging from small deployments to billion-scale vector datasets.
- AI workflow support: Includes features for RAG pipelines, AI agents, and contextual search systems.
Source: Weaviate
{kind=link}
Related content: Read our guide to vector search
General purpose databases supporting vector data
7. PostgreSQL
![]()
PostgreSQL is an open source relational database system with extensible data types, indexing methods, and query capabilities. Vector support is commonly added through extensions, allowing PostgreSQL to combine structured relational data with embedding storage and similarity search.
Repo: https://github.com/postgres/postgres
License: PostgreSQL License
GitHub stars: 21K+
Contributors: 100+
Key features of PostgreSQL for Vector Data:
- Extensible architecture: Supports custom data types, indexing methods, and extensions.
- Advanced indexing: Includes GiST, GIN, BRIN, KNN GiST, multicolumn, and expression indexes.
- JSON and document support: Supports JSON/JSONB, XML, arrays, and key-value data structures.
- Full-text search: Provides built-in text indexing and search functionality.
- ACID transactions and MVCC: Supports transactional consistency and concurrent workloads.
- Replication and partitioning: Includes synchronous and logical replication, partitioning, and disaster recovery features.
Source: PostgreSQL
{kind=link}
8. Cassandra

Apache Cassandra is an open source distributed NoSQL database for high availability and horizontal scalability across multiple data centers and cloud environments. Vector search capabilities are commonly integrated alongside its distributed storage model for large-scale AI and retrieval workloads.
Repo: https://github.com/apache/cassandra
License: Apache-2.0 license
GitHub stars: 9K+
Contributors: 450+
Key features of Cassandra for Vector Data:
- Masterless distributed architecture: Eliminates single points of failure across clusters.
- Linear horizontal scaling: Increases read and write throughput by adding nodes without downtime.
- Multi-datacenter replication: Replicates data across regions for fault tolerance and low-latency access.
- Fault-tolerant operation: Supports node replacement and regional outage recovery without service interruption.
- High-throughput writes: Optimized for large-scale transactional and event-driven workloads.
- Cloud and Kubernetes support: Supports deployment across on-premises, cloud, and containerized environments.
Source: Apache
{kind=link}
9. Valkey
![]()
Valkey is an open source in-memory key/value datastore derived from Redis OSS. It supports multiple data structures, clustering, replication, scripting, and extensibility through modules, making it suitable for caching, real-time applications, and vector-enabled workloads through extensions.
Repo: https://github.com/valkey-io/valkey
License: BSD 3-Clause license
GitHub stars: 25K
Contributors: 850+
Key features of Valkey:
- In-memory key/value storage: Supports low-latency access for real-time workloads.
- Rich data structures: Includes strings, hashes, lists, sets, sorted sets, bitmaps, and HyperLogLogs.
- Replication and clustering: Supports standalone, replicated, and clustered deployments.
- Lua scripting support: Allows server-side scripting for custom operations.
- Module extensibility: Supports custom modules that add commands and data types.
- Official client libraries: Provides client support for Python, Java, Go, Node.js, PHP, and C#.
10. CockroachDB
![]()
CockroachDB is a distributed SQL database compatible with PostgreSQL and capable of scaling globally distributed applications. It combines relational transactions, horizontal scaling, and geographic data distribution, while also supporting AI and vector search workloads.
Repo: https://github.com/cockroachdb/cockroach
License: BSL 1.1, MIT license, CockroachDB Community License (CCL)
GitHub stars: ~30K
Contributors: 800+
Key features of CockroachDB for Vector Data:
- Distributed SQL architecture: Automatically distributes and replicates data across nodes.
- Horizontal scalability: Scales from small clusters to petabyte-scale deployments without manual sharding.
- PostgreSQL compatibility: Supports PostgreSQL-compatible SQL interfaces and tooling.
- Strong consistency: Maintains transactional consistency across distributed regions.
- High availability and failover: Supports automated failover and regional resilience.
- Geo-distributed deployment: Supports locality-aware data placement and compliance controls.
Source: CockroachDB
{kind=link}
Streamlining performance and reliability: Instaclustr's managed approach to vector database management
Instaclustr is a leading provider of managed solutions for open-source technologies offering comprehensive management services for vector databases. These databases are commonly used in applications such as machine learning, data analytics, and recommendation systems.
Instaclustr’s management of vector databases encompasses various aspects to ensure optimal performance, scalability, and reliability. Instaclustr provides a fully managed service, handling the deployment, configuration, and ongoing maintenance of the vector database infrastructure. This relieves organizations from the complexities of managing and operating the database themselves, allowing them to focus on their core business objectives.
One key aspect of Instaclustr’s management approach is expertise in tuning and optimizing vector databases. Instaclustr has a deep knowledge of the underlying technologies and understands the intricacies of configuring the database for specific use cases. This expertise enables fine-tuning of database parameters, indexing strategies, and query optimization techniques to maximize performance and minimize query latency.
Scalability is another critical aspect of Instaclustr’s management of vector databases. As datasets grow in size or the workload demands increase, Instaclustr can seamlessly scale the vector database infrastructure to handle the additional load. It employs horizontal scaling techniques, such as sharding and replication, to distribute the data and workload across multiple nodes, ensuring high availability and efficient utilization of resources.
Instaclustr also places a strong emphasis on security and data protection. It implements robust security measures to safeguard the vector database infrastructure, including encryption at rest and in transit, access controls, and regular security audits. Additionally, it provides automated backups and disaster recovery solutions to ensure data integrity and availability in the event of any unforeseen incidents.
For more information on Instaclustr and vector databases, see: