Apache Cassandra is well known for its ability to scale to whatever size you could possibly need. However, the traditional “horizontal” scaling approach of adding or removing cluster nodes to change cluster capacity can be resource-intensive and time-consuming. Scaling a cluster this way can take hours or even days.
Instaclustr’s new dynamic resizing capability dramatically changes this picture by allowing you to vertically scale up or down the processing capacity of each node in a Cassandra cluster, online, in minutes, with the click of a couple of buttons or a single API call. Our benchmarking below demonstrates a fivefold improvement in cluster throughput being within 20-30 minutes. This process can be reversed just as quickly to significantly reduce your infrastructure costs.
This facility provides a huge step forward for organisations that want to efficiently use the proven, open source power of Apache Cassandra while providing flexible processing capacity to allow for patterns such as:
- Weekly or daily large batch analytic processing;
- Periodic large scale data ingestion;
- Peak processing requirements associated with promotions or big events (e.g. Super Bowl, Black Friday); and
- Meeting varying demand across different times of the day.
We have been able to deliver this capability by building on the flexibility of the AWS environment, the sophisticated monitoring and provisioning capability of our managed service, and the inherent capability of Apache Cassandra to handle nodes being taken offline for maintenance without skipping a beat. At a high level the process works as follows:
- Cluster health is checked Instaclustr’s monitoring system including synthetic transactions.
- The cluster’s schema is checked to ensure it is configured for the required redundancy for the operation.
- Cassandra on the node is stopped, and the AWS instance associated with the node is switched to a smaller or larger size, retaining the EBS containing the Cassandra data volume, so no data is lost.
- Cassandra is restarted. No restreaming of data is necessary.
- Monitor the cluster to wait until all nodes have come up cleanly and have been processing transactions for at least one minute (again, using our synthetic transaction monitoring) and then move on to the next nodes.
Nodes can be resized one at a time, or concurrently. Concurrent resizing allows up to one rack at a time to be replaced for faster overall resizing.
This is a very similar operation to the one that our tech-ops team has performed routinely hundreds of times a year to perform patching, upgrades, and other maintenance on customer clusters. So, we’re very confident that a properly configured application can keep using Cassandra throughout this operation without missing a beat. That said, “properly configured’ is important so we highly recommend testing your application against this function before using it in production.
Some Details
This facility is available on specific node sizes available through Instaclustr’s managed service as specified in the table below.
| Instance Size | Resizeable-Small Family
1600GB EBS |
Resizeable-Large Family
3200GB EBS |
| r4.large | resizable – small (r4-l) | resizable – large (r4-l) |
| r4.xlarge | resizable – small (r4-xl) | resizable – large (r4-xl) |
| r4.2xlarge | resizable – small (r4-2xl) | resizable – large (r4-2xl) |
| r4.4xlarge | resizable – large (r4-4xl) |
Dynamic resizing is available between any two sizes in the same family. Moving between families, or migrating an existing cluster to a resizeable cluster, can be completed online with assistance from our tech-ops team.
The size of the disks associated with these families is designed to ensure the systems are not significantly I/O constrained at the largest sizes (as I/O capacity is proportional to disk size for EBS). We don’t support storing more than 2TB on the large family nodes due to operational issues that can result from very dense nodes. Dynamic resizing is available between any two sizes in the same family. Moving between families, or migrating an existing cluster to a resizeable cluster, can be completed online with assistance from our tech-ops team.
Benchmarking
We benchmarked a 9 node cluster using Cassandra-stress mixed operation mode with a 3:1 ratio of reads to writes. We had to use Cassandra-stress mixed mode rather than a yaml stress profile due to an issue with the way Cassandra-stress deals with restarting nodes – a good reminder to test your code with standard Cassandra operational scenarios such as restarting nodes.
The following graphs show the number of operations per second we were able to achieve with each node size at an average p95 latency of approximately 10ms:
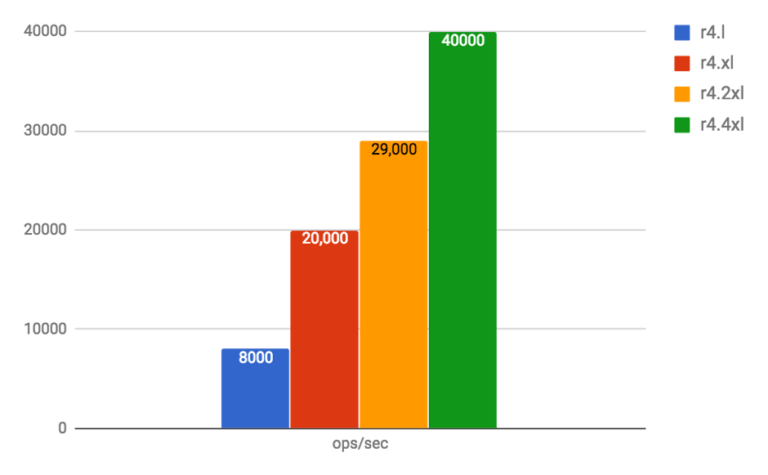
The time taken to perform upsize operations between these sizes is shown in the table below.
| Resize time | r4.large -> r4.xlarge | r4.xlarge -> r4.2xlarge | r4.2xlarge -> r4.4xlarge |
| by-rack resize | 0:20:35 | 00:20:20 | 0:30:55 |
| by node resize | 00:59:59 | 1:04:12 | 0:56:10 |
During the resize, there are some short periods of increased latency that would normally be smoothed out by speculative retry in the driver. This impact is reduced when the number of nodes resized in parallel which is an option you can choose when initiating a resize operation. The charts below show Cassandra-stress reported p95 latencies during a resize operations rack at a time and then node at a time.
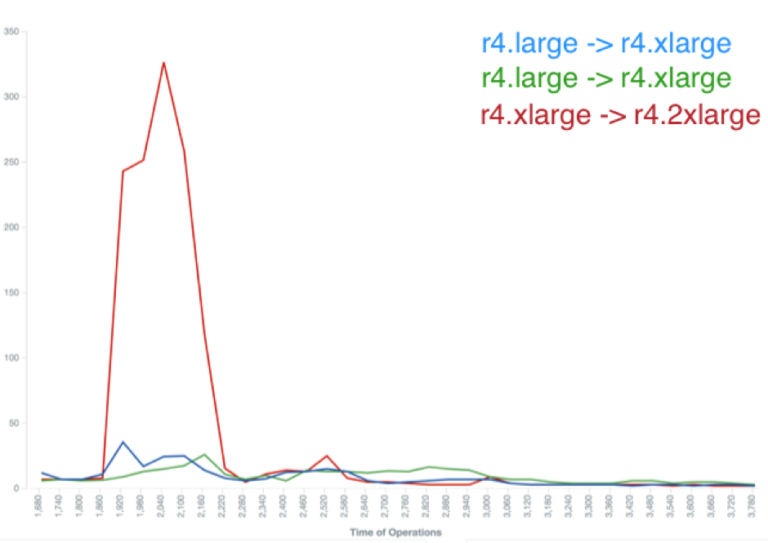 Latency during by-rack resize operation
Latency during by-rack resize operation
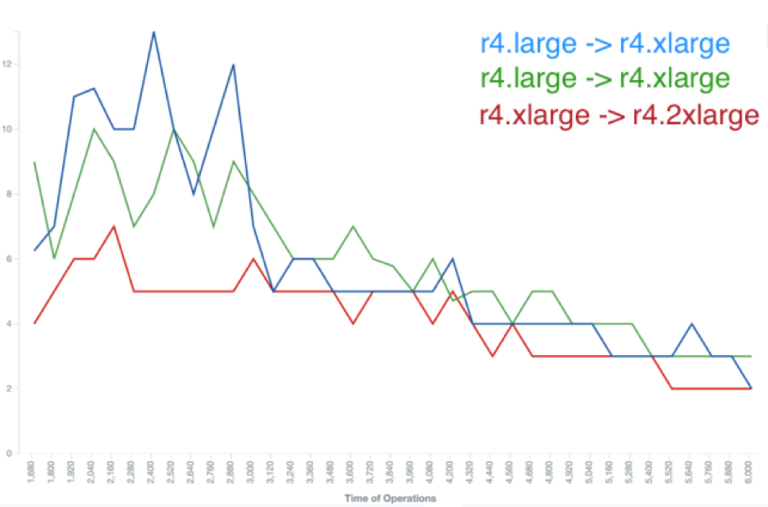 Latency during by-node resize operation
Latency during by-node resize operation
Need more information?
For more information, or if you’d like to trial our dynamic resizing capability, please contact [email protected].