Since the launch of Instaclustr Managed Kafka, we have gained broad production experience managing Apache Kafka across a wide range of use cases. With more production clusters, we are learning more about Kafka and how best to tune and optimise it for performance, scale, and reliability.
Part of the learning was that Kafka is being increasingly used for use cases which require a large number of partitions (in 100s or 1000s). Although Kafka by design is a streaming technology that produces and consumes data sequentially and is expected to predominantly generate sequential I/O, the amount of random I/O increases with the number of partitions (as I/O switches between the files corresponding to each partition). Our initial choice of throughput optimised magnetic disk (ST1) EBS volumes was based on the inherent design of Kafka to do sequential I/O which is still the case when the number of partitions is relatively small. However, now seen a broad range of real-world use cases, we have made the decision to move from magnetic disks to SSD based EBS (GP2) volumes for all AWS instance types that we support. This change has resulted in small price increases for customers running in Instaclustr’s account with infrastructure-inclusive pricing. The increase ranges from 3-14% depending on region and instance configuration – log in to our console for full details.
Introducing i3 instance types
We have also heard from customers with experience running their own Kafka clusters at a significant scale that i3 instances can be a good choice for specific use cases. We have also seen this with Cassandra where many of our customers with relatively hot data (ie high ratio of transactions to data stored on disk) get the best price performance from i3 or c5d instances.
To cater to such application workloads, we have added the i3.xl and i3.2xl instance types to our Kafka offering. They have instance local storage (SSDs) which provides very-low-latency reads and writes for random I/O making it perfectly suitable for high-performance Kafka deployments.
i3 instance type pricing
We have added two high throughput (Production) instance types of i3s – i3.xlarge and i3.2xlarge. Below are their specification and pricing (for US West – Oregon region). Pricing for rest of the regions is available on Instaclustr Console when you login. Alternatively, you can contact the Sales team to get a full list of pricing.
| # | Instaclustr Instance Type | AWS Instance Name | CPU Cores | Memory | Storage Capacity | Price/node/month
US West (Oregon) |
| 1 | Max Throughput Standard | i3.xlarge | 4 | 30500 MB | 884 GB SSD (instance storage) |
$647.18 |
| 2 | Max throughput large | i3.2xlarge | 8 | 61000 MB | 1769 GB SSD
(instance storage) |
$1,294.30 |
Benchmarking results
We did extensive benchmarking to compare the performance and burst usage for clusters with the following configurations.
- r4.xlarge cluster with ST1 (Magnetic disk) EBS for Kafka and Zookeeper
- r4.xlarge cluster with ST1 (Magnetic disk) EBS for Kafka data mount and GP2 (SSD) EBS for Zookeeper data mount
- r4.xlarge cluster with GP2 (SSD) EBS for Kafka and Zookeeper
- I3.xlarge cluster with local SSD storage
The tests included 1 producer and 3 consumers all running on a single machine where each consumer read messages from different consumer groups. Each of these clusters had 3 nodes (running Kafka brokers) with TLS-enabled and no disk encryption. We ran two tests for each, one with 3 partitions and another with 300 partitions to test the performance under scaled conditions. In both the runs, the topic replication factor was 3. We chose to benchmark consumer lag metric as it indicates the end-to-end performance from the time a producer starts writing a message to the time a consumer reads that message.
The test with 3 partitions didn’t have much difference across the clusters with i3 cluster performing marginally lower. The only other difference was the r4 cluster with ST1 configuration consumed burst credit at 0.06% per minute whereas the rest of the clusters managed the workload without consuming burst credit.
As we scaled the system to 300 partitions, the performance difference was easily noticeable.
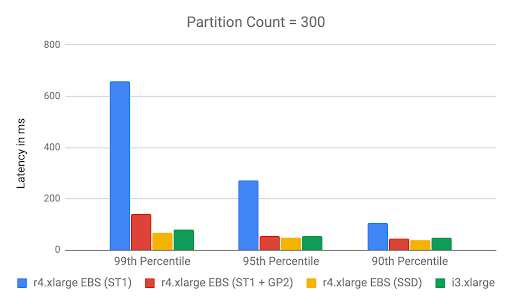
At the 99th percentile, the r4.xlarge EBS (ST1) had a consumer lag of 660ms whereas the r4.xlarge EBS (GP2) was 10x faster at 68ms. Even the r4.xlarge EBS (ST1+GP2) was ~5x faster at 142 ms. However, that configuration consumed burst credit at 0.4% per minute. That means, when the burst credit is exhausted, its performance would go down further. Likewise, r4.xlarge EBS (ST1) consumed burst credit at 0.8% per minute, twice as quickly as the combination configuration. On the other hand, r4.xlarge EBS (GP2) managed the workload without using any burst credit indicating that it can handle a much higher load. I3.xlarge had a consumer lag similar to that of r4.xlarge EBS (GP2) because they both use SSDs as storage. We did notice again that i3 had a slightly larger consumer lag but bear in mind that it is cheaper than an equivalent SSD backed r4.xlarge.
These results are based on a specific workload that had 1 producer, 3 consumers reading messages on different consumer groups, all situated on a single machine, with a fixed message size. But for other workloads with a large number of partitions, producers and consumers, varying message sizes, and other different configurations, theoretically, i3s are expected to perform better than r4s because they can cater to much higher IOPS than SSD EBS backed r4s. If your application has even higher throughput requirements, i3.2xlarge may be the right candidate. We did run the same tests on it and its consumer lag was 26ms (99th percentile), which makes it 3x faster than the i3.xlarge and 2.6x faster than SSD EBS backed r4.xlarge. We plan to run other workloads on i3s to explore and identify use cases where i3s are best suited. We plan to publish those benchmarking results in a future blog.
If you want to know more about this benchmarking or need clarification on when to use i3 instance type for Kafka, reach out to Support team (if you are an existing customer), or contact our Sales team.