As Kubernetes becomes the de facto for container orchestration, more and more developers (and enterprises) want to run Apache Cassandra on Kubernetes. It’s easy to get started with this – especially considering the capabilities that Kubernetes’ StatefulSets bring to the table. Kubernetes, though, certainly has room to improve when it comes to storing data in-state and understanding how different databases work.
Why Kubernetes?
For example, Kubernetes doesn’t know if you’re writing to a leader or a follower database, to a multi-sharded leader infrastructure, or to a single database instance. StatefulSets – workload API objects used to manage stateful applications – offer the building blocks required for stable unique network identifiers, stable persistent storage, ordered and smooth deployment and scaling, deletion and termination, and automated rolling updates.
However, while getting started with Cassandra on Kubernetes might be easy, it can still be a challenge to run and manage (and running Docker is another challenge in itself).
Overcoming hurdles
To overcome some of these hurdles, we decided to build an open source Cassandra-operator that runs and operates Cassandra within Kubernetes. Think of it as Cassandra-as-a-Service on top of Kubernetes. We’ve made this Cassandra-operator open source and freely available on GitHub. It remains a work in progress between myself, others on my team, and a number of partner contributors – but it is functional and ready for use. The Cassandra-operator supports Docker images, which are open source and available as well (via the same link).
This Cassandra-operator is designed to provide “operations-free” Cassandra: it takes care of deployment and allows users to manage and run Cassandra, in a safe way, within Kubernetes environments. It also makes it simple to utilize consistent and reproducible environments.
While it’s possible for developers to build scripts for managing and running Cassandra on Kubernetes, the Cassandra-operator offers the advantage of providing the same consistent reproducible environment, as well as the same consistent reproducible set of operations through different production clusters.
And this is true across development, staging, and QA environments. Furthermore, because best practices are already built into the operator, development teams are spared from operational concerns and are able to focus on their core capabilities.
What is a Kubernetes operator?
A Kubernetes operator consists of two components: a controller and a custom resource definition (CRD). The CRD allows devs to create Cassandra objects in Kubernetes. It’s an extension of Kubernetes that allows us to define custom objects or resources using Kubernetes that our controller can then listen to for any changes to the resource definition.
Devs can define an object in Kubernetes that contains configuration options for Cassandra, such as cluster name, node count, jvm tuning options, etc. – all the information you want to give Kubernetes about how to deploy Cassandra.
You can isolate the Cassandra-operator to a specific Kubernetes namespace, define what kinds of persistent volumes it should use, and more. The Cassandra-operator controller listens to state changes on the Cassandra CRD and will create its own StatefulSets to match those requirements.
It will also manage those operations and can ensure repairs, backups, and safe scaling as specified via the CRD. In this way, it leverages the Kubernetes concept of building controllers upon other controllers in order to achieve intelligent and helpful behaviours.
How does it work?
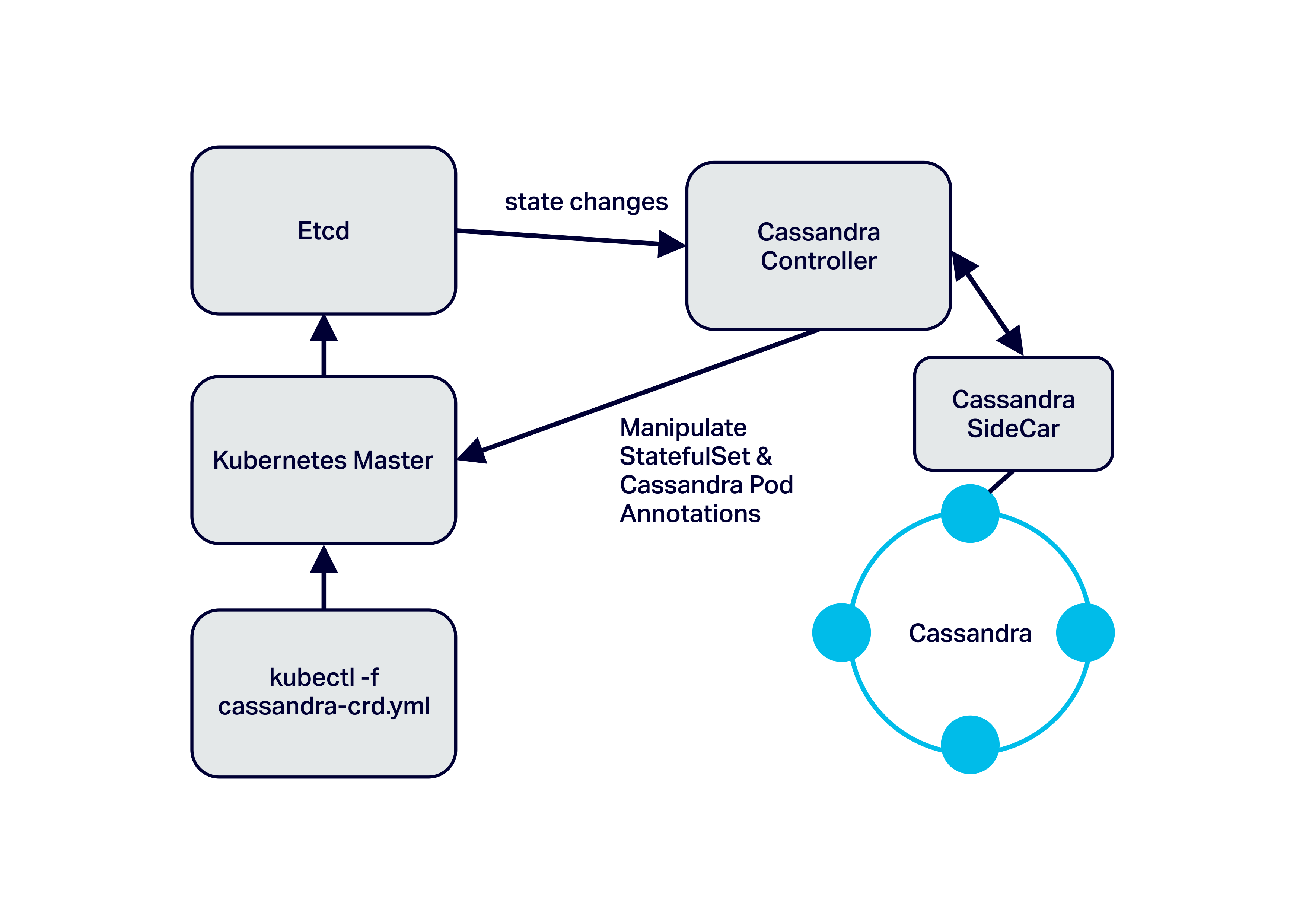
Architecturally, the Cassandra controller itself connects to the Kubernetes Master. It listens to state changes and manipulates Pod definitions and CRDs. It then deploys those, waits for changes to occur, and repeats until the entirety of necessary changes is fully completed.
The Cassandra controller can, of course, perform operations within the Cassandra cluster itself. For example, want to scale down your Cassandra cluster?
Instead of manipulating the StatefulSet to handle this task, the controller will first see the CRD change. The node count will change to a lower number (say from six to five). The controller will get that state change, and it will first run a decommission operation on the Cassandra node that’s going to be removed.
This ensures that the Cassandra node stops gracefully and that it will redistribute and rebalance the data it held across the remaining nodes. Once the Cassandra controller sees that this has happened successfully, it will modify that StatefulSet definition to allow Kubernetes to finally decommission that particular Pod. Thus, the Cassandra controller brings needed intelligence to the Kubernetes environment to run Cassandra properly and ensure smoother operations.
As we continue this project and iterate on the Cassandra-operator, our goal is to add new components that will continue to expand the tool’s features and value.
A good example is the Cassandra SideCar (included in the diagram above), which will begin to take responsibility for tasks like backups and repairs. Current and future features of the project can be viewed on GitHub. Our goal for the Cassandra-operator is to give devs a powerful open source option for running Cassandra on Kubernetes with a simplicity and grace that has not yet been all that easy to achieve.
Ben Bromhead is CTO at Instaclustr, which provides a managed service platform of open source technologies such as Apache Cassandra, Apache Spark, Elasticsearch and Apache Kafka.