What is open source vector database software?
Several open-source software options are available for vector databases, with prominent choices including Milvus, Qdrant, FAISS, Weaviate, Chroma, OpenSearch, Cassandra, and Pgvector. These solutions are vital for AI and machine learning applications like semantic search and recommendation systems.
Open source vector database software stores, indexes, and searches high-dimensional vectors: numerical representations of data such as text, images, or audio. Unlike traditional relational or document databases, vector databases are optimized for operations like nearest neighbor search, which is crucial for AI and machine learning applications.
These databases allow organizations to build applications that rely on finding similar items or identifying patterns within complex datasets, harnessing the power of vector embeddings. The open source aspect means the software is freely available, with source code that can be modified or extended by anyone. This encourages community-driven innovation, faster bug fixes, and greater transparency regarding data handling and algorithms.
This is part of a series of articles about vector databases
Core capabilities of open source vector databases software
High-dimensional vector storage
A core function of vector database software is its capacity to store vast numbers of vectors, each possibly containing hundreds or thousands of dimensions. This storage is optimized for read and write operations at scale, ensuring that large datasets, such as those generated by modern AI models, are accessible with low latency.
Unlike conventional databases, these systems can efficiently accommodate the unique requirements of vector data, like rapid changes in vector size or structure, without performance degradation. Storing high-dimensional vectors effectively means dealing with the challenges of memory usage, compression, and maintaining quick access. Most open source solutions offer features such as memory mapping, efficient serialization, and sharding.
Indexing mechanisms
Efficient similarity search in large-scale vector datasets depends on indexing techniques. Open source vector databases implement algorithms such as IVF (inverted file), HNSW (hierarchical navigable small world), and Annoy-style approximate nearest neighbor indexes. These indexing methods reduce the number of comparisons needed to find similar vectors, cutting down search time from minutes to milliseconds even when working with millions of items.
Such indexes are essential for practical deployment, especially in latency-sensitive applications like recommendation engines or real-time search. Open source systems often allow customization of indexing parameters, like index type and recall guarantees, so users can tune performance according to their workloads.
Scalability and distributed architecture
Open source vector databases are designed to scale horizontally, supporting distributed deployments across clusters of machines. By sharding data and distributing both storage and search workloads, these systems can manage immense datasets that exceed the capacity of single servers. Horizontal scaling is critical for applications that require real-time responses from vast collections of high-dimensional vectors, such as in eCommerce or content platforms.
Distributed architecture also ensures high availability and fault tolerance. If a node goes down, the workload shifts to other nodes, maintaining uninterrupted service. This resilience makes vector databases suitable for production environments and mission-critical applications.
Metadata filtering and hybrid queries
Vector search alone is rarely enough for practical applications; most real-world use cases require combining vector similarity with traditional filtering based on metadata. Open source vector databases support hybrid queries that blend vector-based nearest neighbor search with structured queries over associated metadata fields. This enables fine-grained control, like retrieving only vectors tied to certain categories or date ranges.
Metadata filtering enables richer, more flexible application logic. For instance, semantic search can be limited to specific document types, languages, or geographic regions. Open source platforms frequently implement efficient bitmaps and indexing on metadata fields, ensuring that filtering doesn’t significantly impact performance even as datasets grow.
Integration with machine learning frameworks
Integration with machine learning frameworks is a key aspect of modern open source vector databases. These systems often provide APIs and plugins to connect directly with frameworks like TensorFlow, PyTorch, or HuggingFace Transformers. Such integrations simplify the process of embedding generation, vector ingestion, and retrieval within end-to-end AI pipelines.
By supporting native ingestion of vectors produced by external ML workflows, and sometimes offering built-in embedding models, these databases close the loop between model training and production deployment. Developers can automate the flow from feature extraction to live search, experiment with different models, or update embeddings dynamically.
Use cases for open source vector database software
Semantic search applications
Semantic search uses vector embeddings to understand content beyond mere keyword matches, enabling retrieval based on meaning and context. Open source vector databases make this possible by supporting nearest neighbor search in high-dimensional space, which can identify subtle relationships between queries and documents. This improves search accuracy, making it more useful for knowledge management, legal research, and technical documentation.
These systems also enable features such as query expansion and contextual ranking, helping retrieve information even if the user input doesn’t match the stored data word-for-word. This is crucial for conversational AI, chatbots, and enterprise search platforms where nuanced understanding and relevance matter most.
Image and video similarity search
With the proliferation of digital media, finding visually similar images or videos is a growing challenge. Open source vector databases address this by indexing embeddings generated from image or video content, often using pre-trained convolutional neural networks or other computer vision models.
Users can search for content that is visually alike, rather than relying on manual metadata or tags, simplifying workflows for media, eCommerce, and digital asset management. Beyond simple similarity, these databases support tasks such as deduplication, copyright detection, and recommendation. They scale efficiently as media collections grow to millions or billions of items, maintaining fast retrieval times even for high-resolution or lengthy video embeddings.
Multimodal search and retrieval
Multimodal search refers to retrieving information using a combination of input types, such as text queries returning image results, or images retrieving related documents. Open source vector databases make this feasible by storing and searching across different embedding spaces concurrently.
Supporting multimodal applications demands careful data organization, type-aware indexing, and cross-modal alignment. Such systems enable use cases in social media, digital marketing, and content moderation, where understanding links between varied data types is essential. Open source solutions often provide playgrounds and APIs to accelerate the development of custom multimodal search interfaces and workflows.
Anomaly detection and pattern recognition
Anomaly detection relies on identifying data points that deviate significantly from established patterns, often measured as outliers in vector space. Open source vector databases can be leveraged to conduct fast similarity and distance calculations over streams of incoming vectors, flagging anomalies in real time. This approach is broadly used in areas like fraud detection, security event monitoring, and equipment fault diagnosis.
These databases also support pattern recognition by enabling clustering and grouping of similar vectors without manual labeling. Through integrated indexing and search functions, developers can build analytical applications that spot trends, segment customer profiles, or classify unseen data.
Tips from the expert

David vonThenen
Senior AI/ML Engineer
As an AI/ML engineer and developer advocate, David lives at the intersection of real-world engineering and developer empowerment. He thrives on translating advanced AI concepts into reliable, production-grade systems all while contributing to the open source community and inspiring peers at global tech conferences.
In my experience, here are tips that can help you better implement and operate open source vector database software with an edge:
- Choose “library vs database” intentionally, then design the boundary: FAISS is a killer retrieval library—but it becomes “a database” only after you wrap persistence, concurrency, replication, backfills, and schema/versioning around it. Decide early whether you want to own that boundary or buy it via a real DB.
- Model your data as “chunks + provenance,” not “documents + embeddings”: For RAG/search, store immutable chunk IDs, source doc version, offsets, and extraction pipeline version. This makes re-chunking and re-embedding tractable and prevents “mystery chunks” when content changes.
- Use dual indexes for churny workloads: High update rates can degrade graph quality (especially HNSW). Maintain a small “fresh” index for recent writes and a larger “stable” index for consolidated data; query both and merge results. Periodically compact fresh→stable.
- Treat delete/TTL as a first-class performance feature: Deletions often turn into tombstones until compaction/merge. Plan compaction windows, vacuum strategy, or segment-merge tuning so TTL-heavy datasets don’t silently rot into slow queries.
- Exploit “vector normalization as an API contract”: If you do cosine similarity, normalize vectors at write time (and enforce it). It simplifies distance math, reduces mistakes across services, and makes debugging scoring anomalies much easier.
Notable open source vector database software
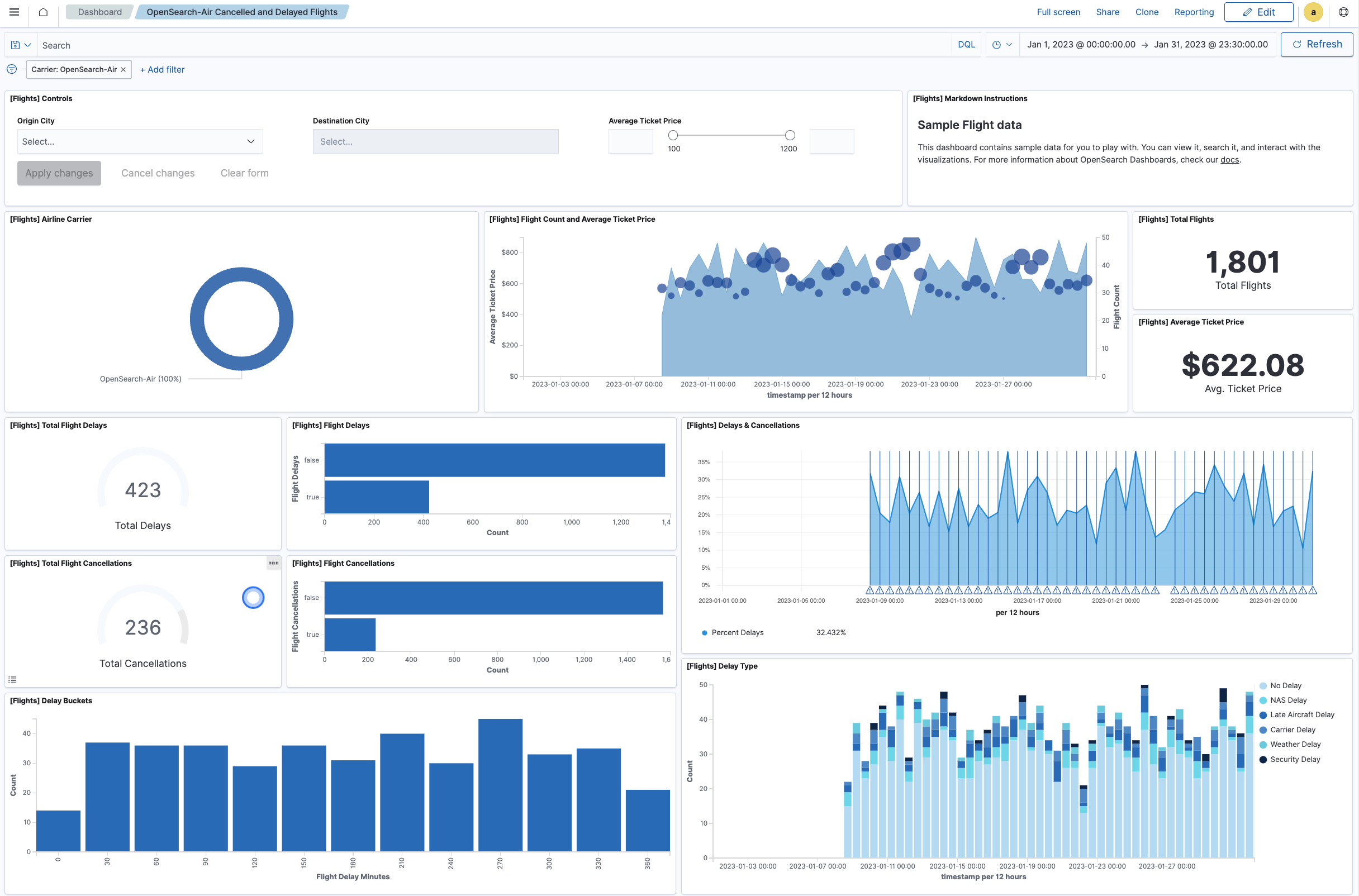
1. OpenSearch
![]()
OpenSearch is an extensible open source platform that integrates vector search capabilities within its analytics and search suite. The OpenSearch Vector Engine supports high-dimensional vector data, making it suitable for a range of AI applications including semantic search, anomaly detection, and recommendation systems.
Key features include:
- Vector and hybrid search: Supports semantic, sparse, hybrid, and multimodal search using vector embeddings and keyword-based techniques
- GPU-accelerated indexing: Uses GPU-based acceleration to speed up vector indexing and large-scale search workloads
- Real-time data ingestion: Allows continuous ingestion and transformation of unstructured data streams for real-time vector search
- Query DSL: Exposes a flexible, JSON-based domain-specific language for building complex queries
- LLM integration: Compatible with popular large language models for embedding storage and retrieval in RAG pipelines

Source: OpenSearch
{kind=link}
2. Apache Cassandra
![]()
Apache Cassandra introduced native vector search in version 5.0, enabling AI-driven similarity search within its scalable, distributed database. It uses a new vector data type and integrates with Storage-Attached Indexes (SAI) to support fast and flexible retrieval of high-dimensional embeddings, making it suitable for natural language processing and recommendation systems.
Key features include:
- Vector data type in CQL: Allows direct storage and retrieval of floating-point embeddings within Cassandra tables
- Similarity-based search: Enables contextual similarity comparisons using vectors generated by ML models
- LLM compatibility: Supports embeddings generated by large language models for semantic queries across various NLP tasks
- Storage-Attached Indexing (SAI): Adds high-throughput, column-level indexing to enable efficient similarity and metadata search
- Distributed and scalable: Maintains Cassandra’s high availability and fault tolerance for vector workloads
3. Pgvector (PostgreSQL)

Pgvector is a PostgreSQL extension that adds support for storing, indexing, and querying vector embeddings within the relational database. It supports a range of distance metrics and indexing options for both exact and approximate nearest neighbor search. Pgvector is designed for integration into AI pipelines while retaining PostgreSQL’s reliability and tooling.
Key features include:
- Diverse distance functions: Supports L2, cosine, inner product, L1, Hamming, and Jaccard distances for similarity comparison
- Flexible indexing: Offers HNSW and IVFFlat indexes to balance speed, recall, and memory usage
- Hybrid filtering: Enables vector search combined with SQL filters and full-text search for hybrid query capabilities
- Wide format support: Handles single-precision, half-precision, sparse, and binary vectors across thousands of dimensions
- PostgreSQL integration: Inherits full support for transactions, joins, replication, and language-agnostic access via standard Postgres clients
Source: PostgreSQL
{kind=link}
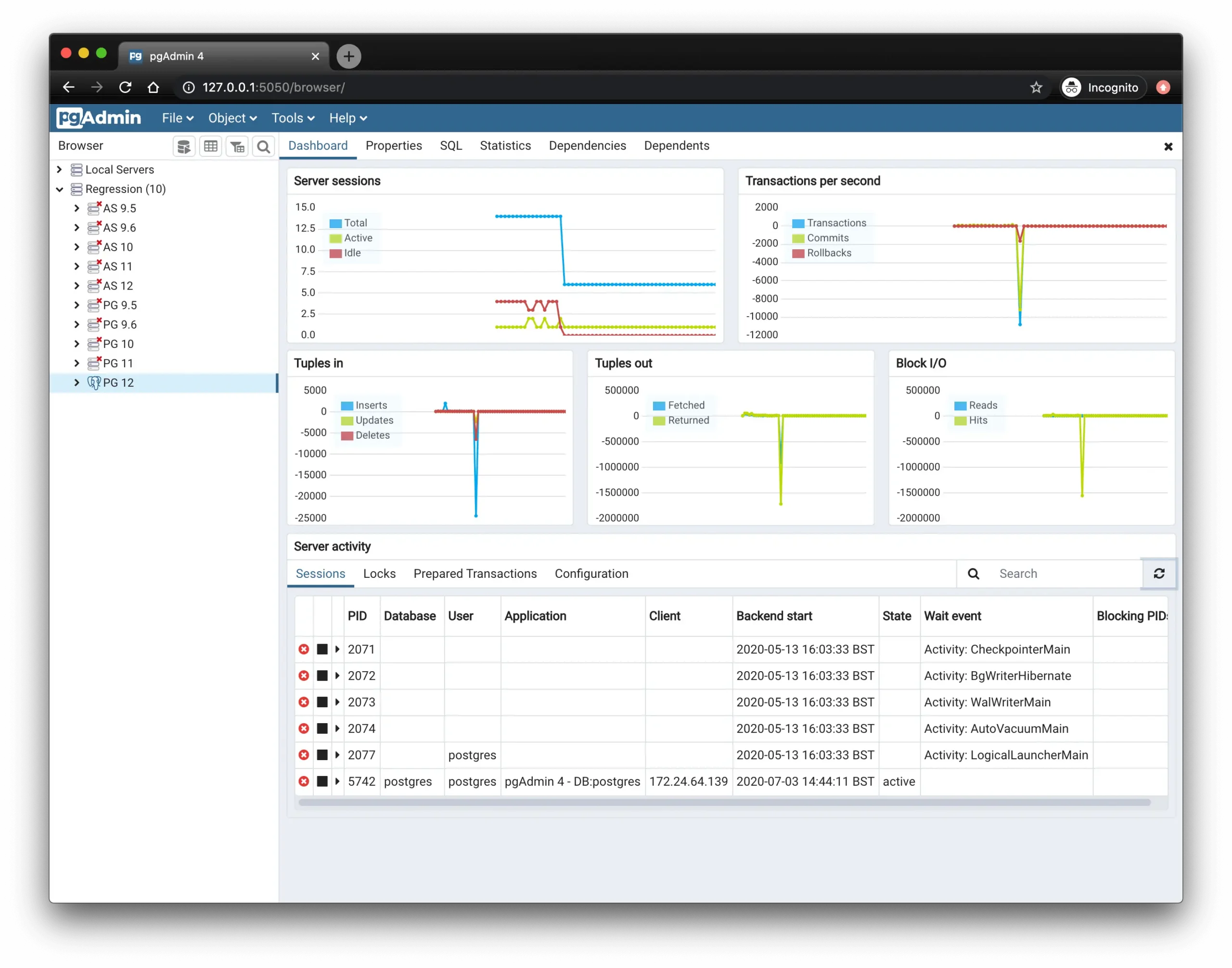
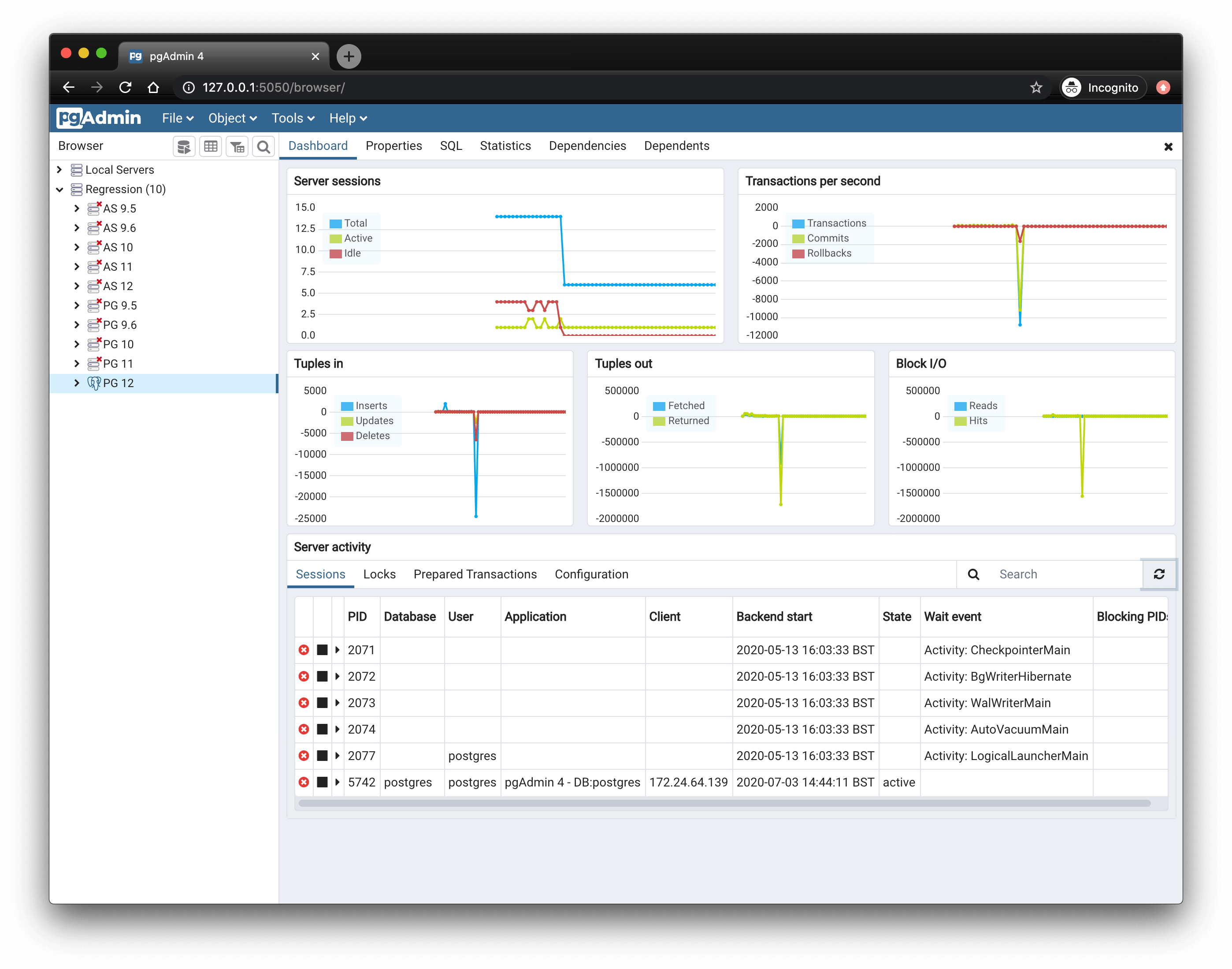
4. Milvus
![]()
Milvus is a high-performance open source vector database supporting AI and generative applications at scale. It enables fast and flexible similarity search across massive volumes of vector embeddings and supports deployments ranging from local development environments to distributed enterprise setups. With a modular architecture and wide-ranging index support, Milvus is optimized for both experimentation and production workloads.
Key features include:
- Modular, scalable architecture: Milvus separates its components, such as coordinators, workers, and storage, allowing each to scale independently. This service-oriented design supports fine-grained resource allocation and high availability in distributed environments.
- Multiple deployment modes: Offers Milvus Lite for quick prototyping on local machines, Milvus Standalone for production use on a single node, and Milvus Distributed for large-scale, clustered deployments with billions of vectors.
- Index support: Supports over 10 index types including HNSW, IVF, product quantization, and GPU-accelerated indexes, allowing users to balance accuracy, speed, and memory usage depending on their application.
- Search options: Enables various search modes like top-K ANN, range-based ANN, and hybrid search with metadata filters. Upcoming support for hybrid dense-sparse search further improves its versatility.
- Consistency model: Provides delta consistency with adjustable staleness tolerance, allowing developers to trade off between query latency and data freshness based on workload needs.
Source: Milvus
{kind=link}
5. Qdrant
![]()
Qdrant is an open source vector database and similarity search engine designed to deliver high performance at scale for AI-driven applications. Built in Rust, it focuses on speed, reliability, and efficient handling of high-dimensional data, making it well-suited for use cases like semantic search, recommendation systems, and retrieval-augmented generation (RAG).
Key features include:
- Rust-based performance and reliability: Qdrant is written in Rust, enabling fast and safe execution even with large datasets. Its efficient memory management and low-level control make it capable of handling billions of vectors.
- Cloud-native scalability: Offers horizontal and vertical scaling along with high availability in managed cloud deployments. Supports zero-downtime upgrades, making it production-ready for enterprise-scale systems.
- Deployment options: Supports quick local deployment via Docker and exposes a developer-focused API. This allows integration into various environments, from local prototyping to large-scale production systems.
- Storage and compression: Built-in quantization and disk-based storage options reduce memory usage and cost. This enables users to scale vector search applications without proportionally increasing infrastructure expenses.
- Similarity search: Handles complex high-dimensional vector queries, including semantic and multimodal search. Its optimized algorithms deliver fast and accurate results across vector types.
Source: QDrant
{kind=link}
6. Chroma
![]()
Chroma is an open source AI-native database to support retrieval-augmented generation (RAG) and other LLM-powered applications. It combines vector search, full-text search, and metadata filtering in one system, allowing developers to store and retrieve embeddings along with their associated data efficiently. Chroma is optimized for fast prototyping and scalable production deployments, offering consistent APIs and SDKs across Python and JavaScript environments.
Key features include:
- Unified retrieval system: Chroma supports vector similarity search, full-text search, document storage, and metadata filtering, providing retrieval capabilities for AI and LLM applications.
- Deployment options: Runs locally as an embedded library, as a single-node server, or as a distributed system for large-scale production. The same API is exposed across all modes, simplifying migration.
- Modular architecture: Built around five independent components (the gateway, log, query executor, compactor, and system database) Chroma offers separation of concerns, better scalability, and consistent query results across modes.
- Indexing and storage: Chroma uses a write-ahead log for durability and index compaction services to maintain up-to-date vector, text, and metadata indexes. In distributed deployments, it uses cloud object storage and local SSD caching.
- Multi-modal and metadata-aware retrieval: Supports retrieval across different data types (text, embeddings, etc.) with filtering based on metadata. This makes Chroma suitable for RAG, search, recommendation, and AI agent use cases.
7. FAISS
![]()
FAISS (Facebook AI Similarity Search) is a high-performance library for similarity search and clustering of dense vectors, designed to support large-scale vector operations both in memory and on disk. Developed by Meta’s FAIR research team, FAISS provides a range of indexing structures and quantization techniques optimized for fast nearest neighbor search, even on billion-scale datasets.
Key features include:
- Indexing options: FAISS includes multiple index types like flat (brute-force), inverted files (IVF), product quantization (PQ), optimized PQ, and HNSW. These cover a range of trade-offs between search accuracy, memory usage, and speed.
- Similarity search: Handles datasets that do not fit entirely in RAM by supporting disk-based indexing and compressed vector storage. It can also return the k-nearest neighbors, perform range searches, and batch process multiple queries efficiently.
- Precision–speed trade-offs: Enables approximate nearest neighbor search to significantly accelerate queries. Users can tune the accuracy-performance balance by choosing index configurations and quantization methods suitable for their workloads.
- Support for multiple distance metrics: Offers more than Euclidean distance. FAISS supports inner product search (for maximum similarity), as well as limited support for L1, Linf, and other distance functions.
- GPU acceleration: Provides GPU implementations for major indexing types, leveraging CUDA for high-throughput, low-latency vector search. GPU support is optimized for batch queries and large-scale workloads.
8. Weaviate
![]()
Weaviate is an open source AI-native vector database to simplify and accelerate the development of applications. It combines vector search, keyword search, and machine learning model integration in one platform, allowing developers to build semantic, hybrid, and retrieval-augmented generation (RAG) workflows with minimal setup.
Key features include:
- Hybrid search built-in: Combines vector similarity and BM25 keyword search out of the box, allowing developers to build hybrid search pipelines without additional infrastructure. Results can be merged and re-ranked to improve semantic relevance and retrieval accuracy.
- ML model integrations: Offers plug-and-play integration with over 20 machine learning models and frameworks for embedding generation. Developers can also bring their own models, helping adapt to evolving ML ecosystems or proprietary architectures.
- RAG support: Enables retrieval-augmented generation use cases by connecting stored vectorized data directly with language models, including support for secure interactions with proprietary or sensitive data.
- Filtering: Supports complex structured queries alongside vector search. Filters can be applied across metadata fields with high performance, enabling precise search results even in large datasets.
- Deployment options: Weaviate can be deployed as a self-hosted service, in Kubernetes environments, or used as a managed cloud service. This ensures compatibility with various infrastructure setups and scaling needs.
Source: Weaviate
{kind=link}
Learn more in our detailed guide to Pgvector
Unleashing the power of vector databases with Instaclustr
Harnessing the power of artificial intelligence and machine learning requires a new approach to data management. Vector databases are at the forefront of this shift, providing the essential infrastructure for similarity searches that fuel applications like recommendation engines, image recognition, and natural language processing. Instaclustr delivers a robust, enterprise-ready platform for deploying, managing, and scaling these critical technologies, empowering smarter, more responsive applications.
Instaclustr simplifies the complexity of running high-performance vector databases. It provides production-ready deployments of leading open source technologies like Casssandra, PostgreSQL with the pgvector extension and OpenSearch, fully optimized for vector search workloads. This enables the power of advanced similarity search without the operational overhead. Instaclustr handles the provisioning, monitoring, and maintenance, so DevOps teams can focus on innovation instead of infrastructure management. The Instaclustr Managed Platform is built for scalability, allowing seamless growth of clusters as data volume and query traffic increase, ensuring consistent performance at any scale.
Instaclustr is designed to fit perfectly within existing data ecosystems. By combining vector database capabilities with other technologies, such as Apache Kafka® for real-time data streaming and Apache Cassandra for massive-scale data storage, organizations can build a unified, powerful data layer. This synergy allows for the creation of sophisticated, end-to-end data pipelines that support even the most demanding data-driven applications. Backed by world-class, 24x7x365 expert support, Instaclustr unlocks the full potential of data.
For more information: