A “sink connector” sounds simple—until you realize different systems use the term from different perspectives.
In Apache Kafka Connect, a sink connector means data flowing out of Kafka into another system. In ClickHouse, the database itself is often called the sink—the place data flows into.
The term is correct in both cases. The confusion comes down to one question: Sink… relative to what?
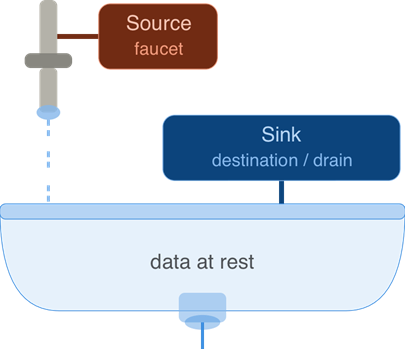
Sinks in data systems
In data-flow language, a source is where records originate, and a sink is where they end up. Think of water: it runs from a faucet (source) and disappears down the drain (destination). In software, “sink” almost always means the destination that absorbs or stores data.
Put together, a sink connector delivers data into a destination: a database, object store, search index, or analytics engine. Kafka and ClickHouse both use the term correctly— “sink” simply means the system downstream of Kafka, and a sink connector is how data gets from Kafka topics to that downstream system.
A common reason you encounter both terms in the same conversation is a real-world pipeline: your application is generating high-volume event data—clickstreams, IoT readings, application logs, or financial transactions—and you need that data available for querying in near real-time. Kafka handles ingestion and buffering at scale. ClickHouse handles fast analytical queries on the other end. The sink connector is the bridge between them.
Kafka Connect: “sink” means “out of Kafka”
Apache Kafka Connect splits integrations into two families. Source connectors read from an external system and produce events into Kafka topics. Sink connectors consume from Kafka topics and write to an external system.
Sink connectors connect data from Kafka topics to sink systems—databases, object stores, search indexes, even other Kafka clusters via MirrorMaker 2. The connector handles the Kafka consumer side for you: reading from topics, managing offsets, and writing records to the destination.
Kafka is the durable, re-playable log in the middle. The sink connector is the egress path—it turns your stream into something your warehouse, lake, or application can use.
ClickHouse: “sink” often means “into ClickHouse”
From ClickHouse’s perspective, ClickHouse itself is the sink—the place events flow into for fast analytical queries.
The most common path for high-throughput ingestion is the ClickHouse Kafka Connect Sink, a Kafka Connect plugin whose product name emphasizes ClickHouse as the destination. Data moves from a Kafka topic, through a Connect worker running the plugin, and lands in a ClickHouse table ready for columnar queries and fast aggregations. NetApp Instaclustr supports this setup end-to-end—if you want to see it built out then read our Terraform series (1, 2, 3), our Kafka Guide, or our Kafka articles.
This is also where the terminology overlap becomes most visible. The ClickHouse Kafka Connect Sink is simultaneously a Kafka sink connector (it consumes from Kafka) and a path into ClickHouse (ClickHouse is the sink). Same integration, two valid descriptions depending on which system you are standing in front of.
Why both say “sink” and why that trips people up
Both communities borrow the same metaphor: data drains toward a resting place.
In Kafka Connect, sink describes where Kafka is in the flow. Kafka is upstream; the connector moves topic data out into another system. The named component is “sink connector”, but the physical sink is your database or bucket.
In ClickHouse-oriented writing, sink describes where ClickHouse is in the flow. External systems or Kafka are upstream; ClickHouse is downstream – the sink for ingestion.
The word is correct in both worlds – but it anchors to different systems. Once you recognize that, the confusion clears up.
A picture that makes it concrete
The full pipeline in one line:
Source systems -> Kafka Connect source connectors -> Kafka topics -> Kafka Connect sink connector -> Sink systems
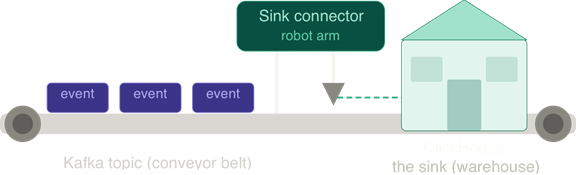
To make it tangible: imagine a conveyor belt (your Kafka topic) carrying boxes (events). A robot arm loads boxes from the belt into a warehouse. The robot arm is the sink connector. The warehouse is the sink.
If the warehouse is ClickHouse, you can truthfully say either “we use a sink connector on Kafka” or “ClickHouse is our sink for that stream.” Same pipeline, different focal point.
Pipeline:
Application -> Kafka -> Sink Connector -> ClickHouse
Replace ClickHouse with S3 or PostgreSQL, and the pipeline still works.
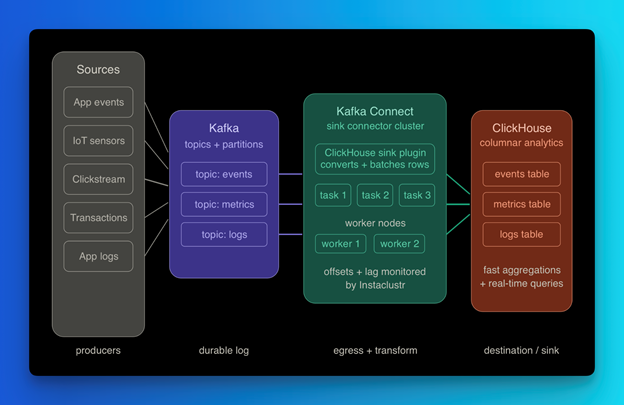
What this looks like in practice on a managed platform
Running Kafka Connect sink connectors in production means managing distributed workers that balance partitions, track offsets, and apply schema conversions. The operational surface adds up fast: consumer lag needs monitoring, retries need configuring, failed records need routing to dead-letter topics, and batch sizes need tuning to match your destination’s write throughput. Getting all of that right before you write a single line of application code is a real cost.
On NetApp Instaclustr, both the Kafka Connect cluster and the ClickHouse cluster are managed infrastructure. Instaclustr runs Kafka Connect in distributed mode, providing managed worker infrastructure designed for resilience and throughput. Connect workers are deployed and monitored by the platform, while connector configuration and task parallelism remain customer‑defined. Note that task count—which controls parallelism at the connector level—is still configured by your team based on your partition count and throughput needs. When you configure a ClickHouse Kafka Connect Sink on Instaclustr, you are writing connector configuration—topic names, table mappings, batch settings—not provisioning VMs or managing JVM heap. Consumer lag and insert error metrics are surfaced through the platform so you can act on them without standing up separate monitoring.
The underlying pipeline is still open source Kafka Connect talking to open source ClickHouse. The managed layer removes the operational overhead that makes sink connectors harder to run reliably than they are to understand conceptually.
The core takeaway: Sink relative to what?
Kafka sink connectors are conceptually simple: they move data from one place into a final destination.
When you encounter the term, simply ask: sink relative to what?
- If the answer is Kafka, you are looking at a consumer that drains a topic.
- If the answer is ClickHouse, you are looking at an ingestion path into an analytics engine.
- If the answer is both, you are probably looking at a ClickHouse Kafka Connect Sink.
If you remember one thing, let it be this: “sink” only makes sense relative to a specific system. Understanding this distinction will help you build and discuss better data pipelines.
Ready to run this pipeline in production?
Everything covered in this article is available as fully managed infrastructure on Instaclustr, with customers configuring connectors, schemas, and throughput to meet their workload requirements. We can manage the operational complexity while you get the full power of open source without the overhead of running it yourself.
You can read more helpful articles at instaclustr.com/blog/ or if you’re ready to try it yourself, start a free trial on the Instaclustr Platform today.