Abstract
Apache Kafka Streams is a framework for stream data processing. In this blog, we’ll introduce Kafka Streams concepts and take a look at one of the DSL operations, Joins, in more detail.
In the next blog, we’ll have a look at some more complete Kafka Streams examples based on the murder mystery game Cluedo.
Introduction
This blog starts to explore Apache Kafka Streams. But as Apache Kafka is a distributed streaming platform, how is this different to what we’ve been exploring in our previous Kafka blogs? Well, Kafka actually has four core APIs, three of which we’ve looked at already (Producer API, Consumer API, Connector API). The fourth is the Streams API:
The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, transforming the input streams to output streams.
The Kafka Streams API enables you to build complex data pipelines, containing application code to perform low-latency streaming data transformations, enrichment, content-based delivery, filtering, alerting, anomaly detection, aggregation, merging, temporal processing, and much more.
Concepts
At a high level, the Kafka Streams API enables you to react to and process one event at a time, from input topics, in a client application, and produce events to output topics. This is the simplest use case and is comparable to what you can do with the consumer and producer API. It’s stateless, you just react to each event without consideration of previous events or state. What’s more powerful is that processing can also be stateful, taking into account time duration (using windows), and state (streams can be turned into tables and back to streams).
In this section, we’ll introduce the core streams concepts, including Topology, Keys, Windows, KStreams, KTables, SerDes, and Domain-specific language (DSL) operations.
Streams is a Client library that provides the framework for a client application, so it only needs java and the Kafka Streams client library to run. The only external dependency is a Kafka cluster. However, note that the application also uses RocksDB as its default embedded persistent key-value store. Depending on your operating system you may have to obtain the latest RocksDB jar.
Topology of Streams Processing
I found Topology fun at school! Topology (in Maths) is about how many holes or surfaces objects have. A mobius strip only has one side, and Topology explains why doughnuts go so naturally with coffee (they are topologically equivalent as they both have a single hole):
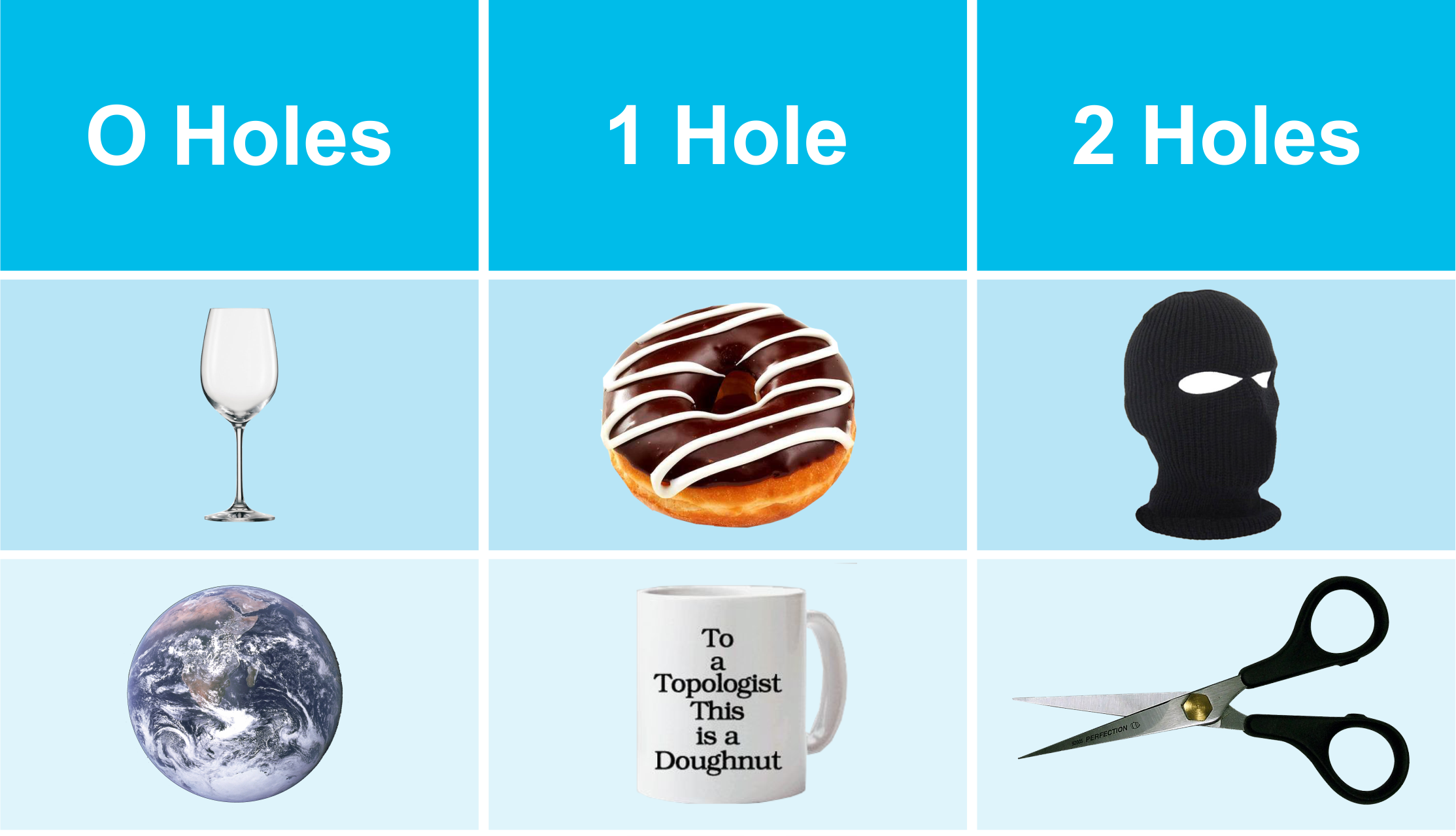
Topological Equivalence
A stream is an unbounded, ordered, replayable, continuously updating data set, consisting of strongly typed key-value records. Stream processing is performed by defining one or more graphs (directed & acyclic) of stream processors (nodes) that are connected by streams (edges), called a Processor Topology.
Processors transform data by receiving one input record, applying an operation to it, and producing output records. Some processors are “special”. A source processor doesn’t receive records from other processors, but only from Kafka topics. A sink processor doesn’t send records to other processors, but only to Kafka topics.
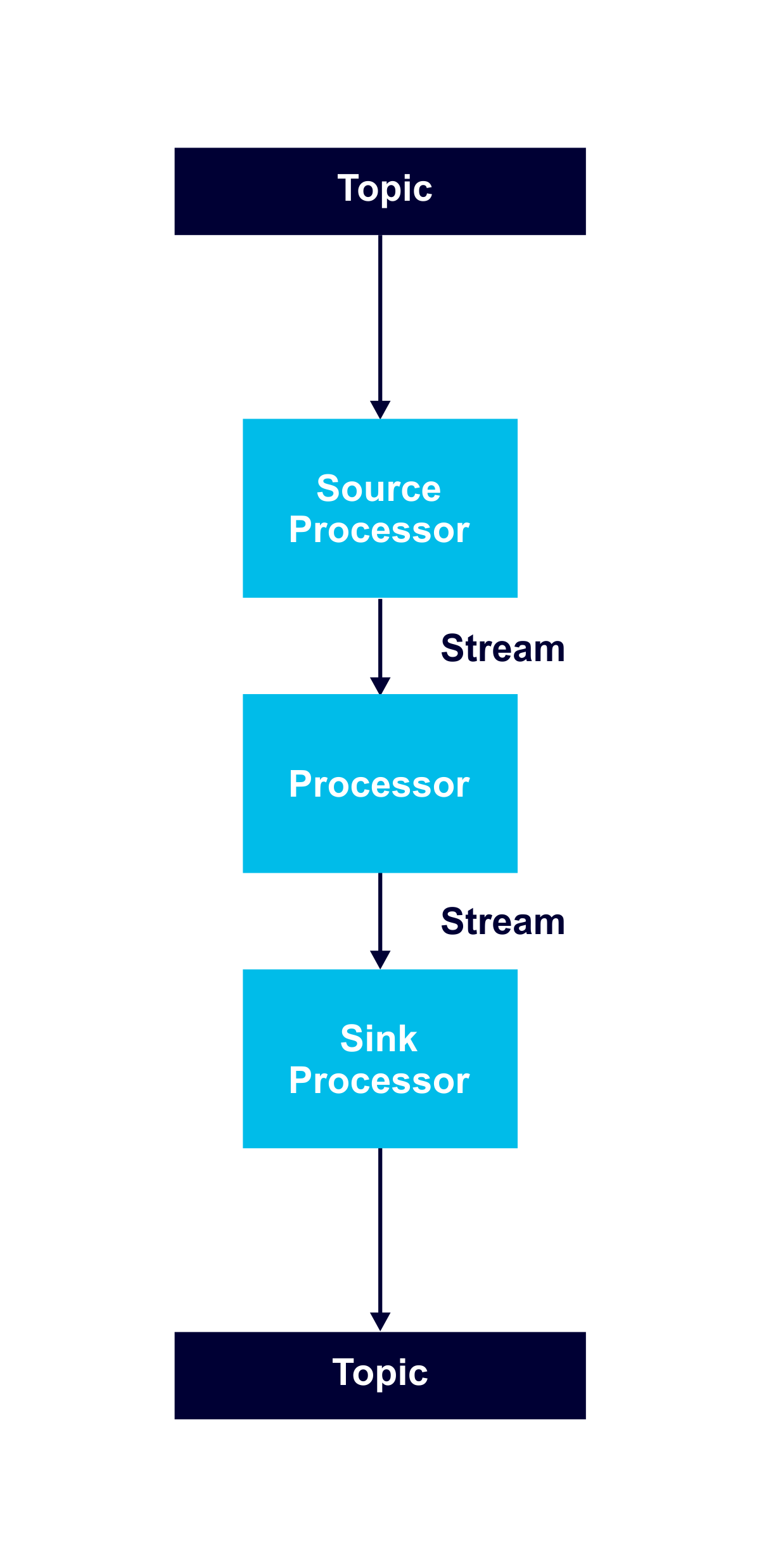
Multiple instances of streams applications can be run, and they are multi-threaded, so processor nodes can be run in parallel. However, as Kafka relies on partitions for scalability you must ensure you have sufficient topic partitions for the number of stream tasks running.
In Kafka Streams, the basic unit of parallelism is a stream task. A task consumes from a single Kafka partition per topic and then processes those records through a graph of processor nodes.
Here’s an example of a more complex Processor Topology:
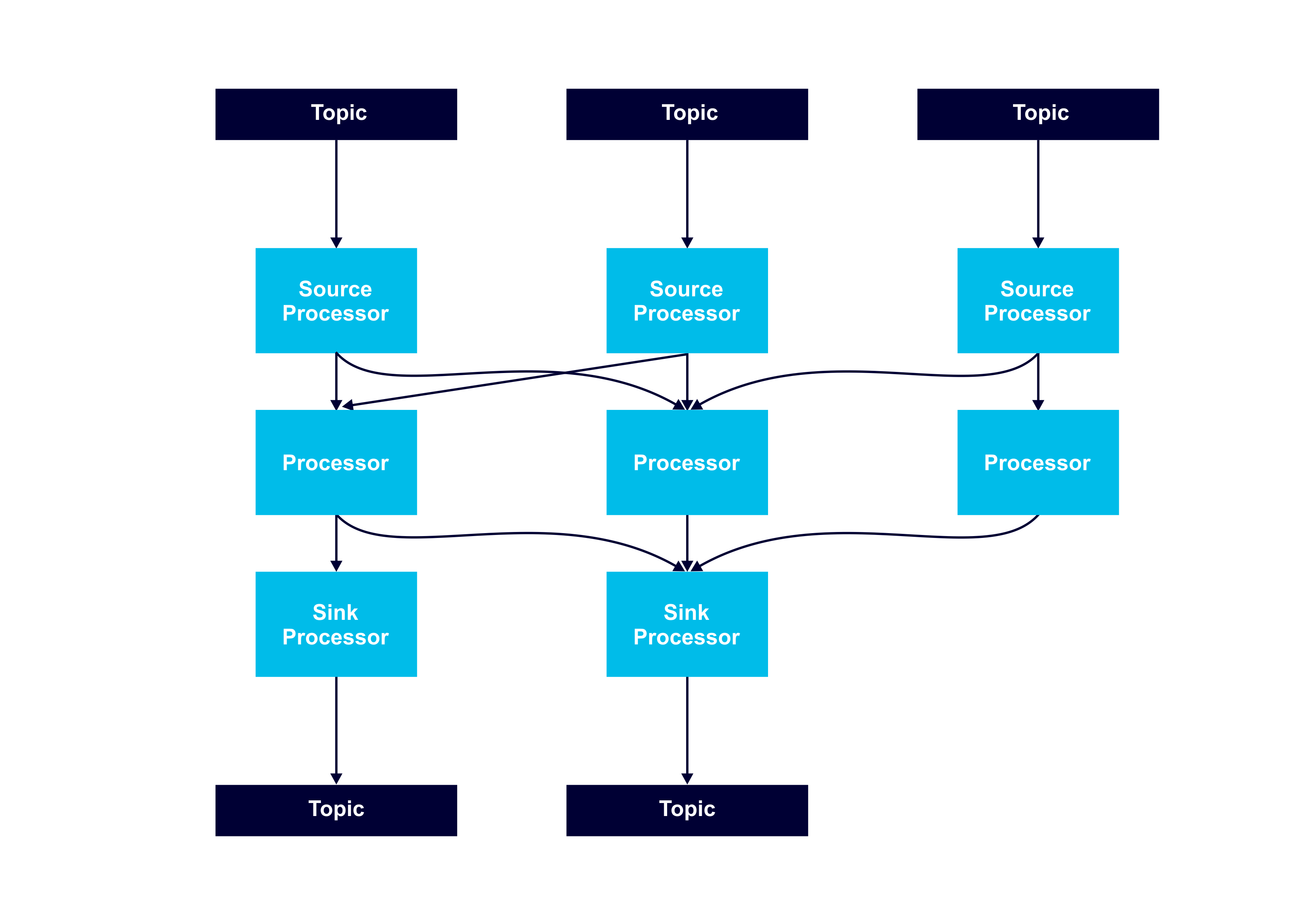 It’s advisable to have a record key for streams so that partitioning works predictably and all stream operations are available (e.g. a key is essential for joins).
It’s advisable to have a record key for streams so that partitioning works predictably and all stream operations are available (e.g. a key is essential for joins).
Windowing based streams operations rely on time. Be default time is interpreted as event time (i.e. the time at which an event was generated by an external device). Timestamps are embedded in the Kafka records, and the time semantics are configured in Kafka.
Streams operations are available in three flavours. There’s a built in Streams DSL which provides functional style operations, a Processor API so you can define lower level procedural operations, and also a query language called KSQL. We’ll look at the DSL next.
DSL Built-in abstractions for Streams and Tables
The Streams DSL has built-in abstractions for streams and tables called KStream, KTable, GlobalKTable, KGroupedStream, and KGroupedTable.
The DSL supports a Declarative functional programming style, with stateless transformations (e.g. map and filter) as well as stateful transformations such as aggregations (e.g. count and reduce), joins, and windowing.
What are KTables? KTables are a way of keeping and using the state. A KTable has key/value rows and only retains the latest value for each key. Incoming records are interpreted as a “changelog stream”, resulting in inserts, updates, or deletes as follows for an input record <key, value>:
|
1 2 3 4 |
If key==null discard If key not in KTable then insert <key, value> If key in KTable then update <key, value> If key in KTable and value==null then delete <key, value> |
Note that each KTable instance of every Streams application instance will be populated with data from only the assigned partitions of the input data. Collectively, across all application instances, all input topic partitions are read and processed. On the other hand, for GlobalKTable, the local GlobalKTable instance of every application instance will be populated with data from all the partitions of the input topic.
DSL Operations: You are in a dark cave, there are doors to the left, ahead, and right. Which do you open?

At university, I wasted several (ok, lots of) nights playing text and then ascii graphics based dungeon adventure games (probably rogue? When you died you had to start from scratch again). Without a map, I invariably fell into a pit and was devoured by monsters. I really needed a map!
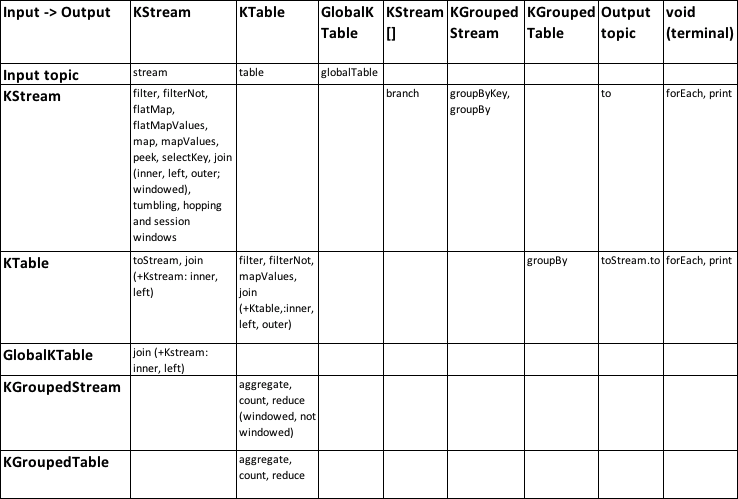
Likewise, I spent several frustrating hours trying to hack a Kafka processing topology together with a bunch of random DSL operations without much luck. And then I stumbled on this Very Important Diagram. It shows the mappings between input types, operations and output types. This is crucial information for creating streaming applications of any realistic topological complexity as it’s very easy (for me at least) to get confused.
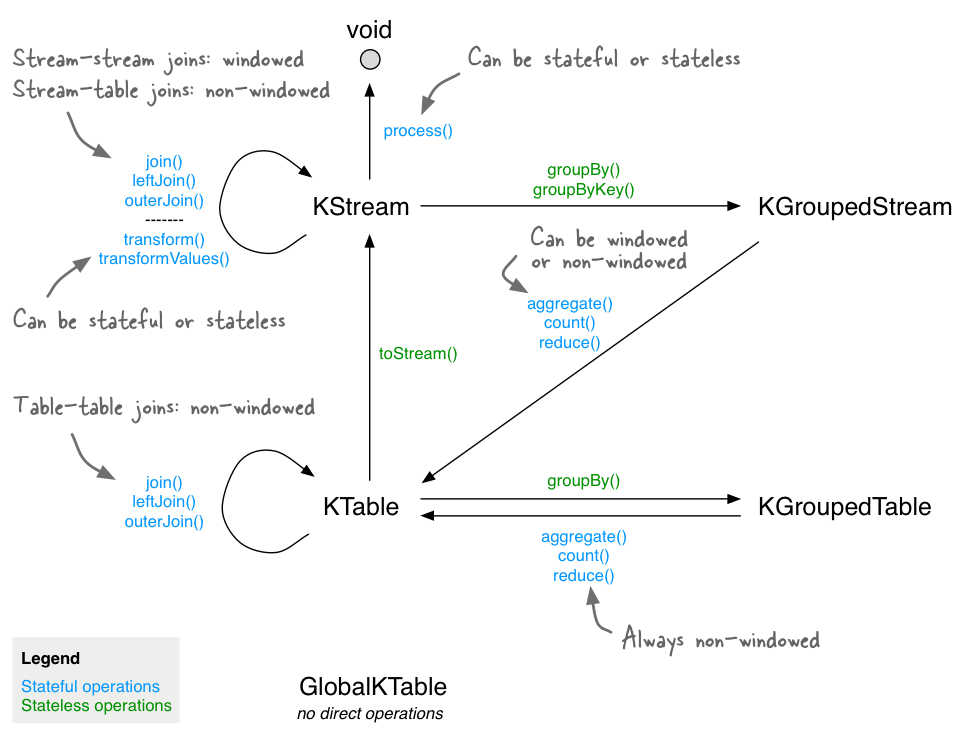
However, I noticed that it’s not 100% complete, so I created the following table with all the DSL operations showing the input/output mappings for each:
| Input | DSL Operation | Output |
| Input topic | stream | KStream |
| Input topic | table | KTable |
| Input topic | globalTable | globalTable |
| KStream | filter, filterNot, flatMap, flatMapValues, map, mapValues, peek, selectKey, join (KStream+KStream; inner, left, outer; windowed), windows (tumbling, hopping, session) | KStream |
| KStream | branch | KStream[] |
| KStream | groupByKey, groupBy | KGroupedStream |
| KStream | to | Output topic |
| KStream | forEach, print | void (terminal) |
| KTable | toStream, join (KStream+KTable) inner, left | KStream |
| KTable | filter, filterNot, mapValues, join (KTable+KTable) inner, left, outer | KTable |
| KTable | groupBy | KGroupedTable |
| KTable | toStream.to | Output topic |
| KTable | forEach, print | void (terminal) |
| GlobalKTable | join (KStream+GlobalKTable) inner, left | KStream |
| KGroupedStream | aggregate, count, reduce (windowed, not windowed) | KTable |
| KGroupedTable | aggregate, count, reduce | KTable |
Here’s the complete matrix (as an image so you can click and expand it):
SerDes
When I googled SerDes (I may have misspelled it) Google suggested I was looking for Sir Dee, evidently, a famous 16th-century scientist and alchemist, pictured here performing an experiment for Queen Elizabeth I :
 (Source: Wikimedia Commons)
(Source: Wikimedia Commons)
{kind=link}
Kafka SerDes is magic but of a different sort. Every Kafka Streams application must provide SerDes (Serializer/Deserializer) for the data types of record keys and values to materialize the data when:
- data is read from or written to a Kafka topic
- data is read from or written to a state store
SerDes can be provided by:
- Setting default SerDes in a StreamsConfig instance.
- Specifying explicit SerDes when calling the appropriate API methods, overriding the defaults.
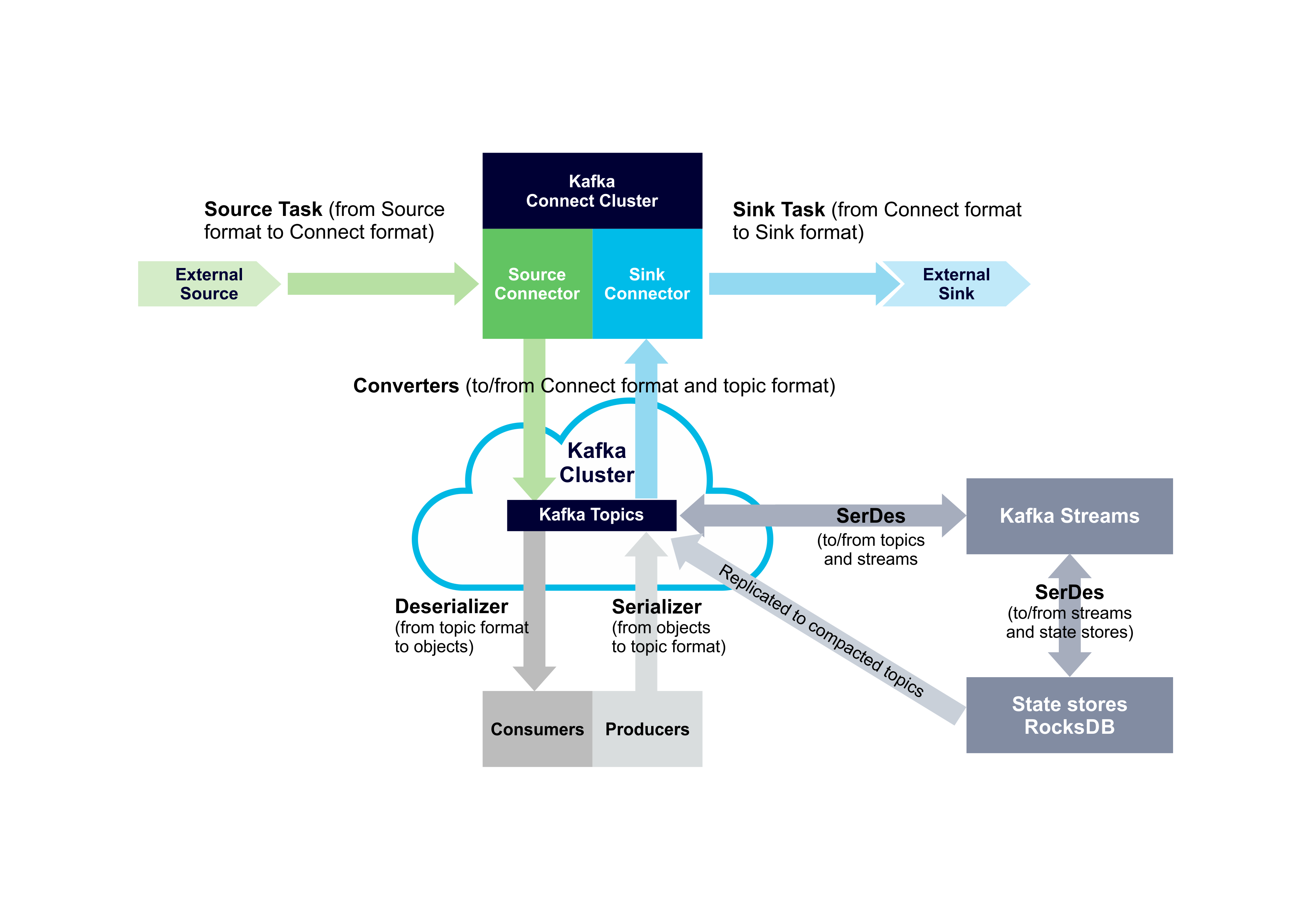
So it looks like there are at least three types of data conversion paths needed within Kafka: (De-)Serializers (Kafka Consumers and Producers), Converters (Kafka Connect), and SerDes (Kafka Streams). There are also Connect Source and Sink Tasks which transform data between 3rd party systems and Kafka Connect. This diagram adds SerDes to the diagram we previously created and shows the main data conversion paths in a Kafka system:
Three Joins
 (Source: Shutterstock)
(Source: Shutterstock)
There seem to be lots of different ways to join ropes (I wasn’t a Scout so I only know the reef knot), and joins are also a significant part of the Kafka Streams DSL. How do joins work? What do they do? Streaming applications often need to do lookups of databases for each incoming event (e.g. to enrich the event stream, to check state to decide on the correct action, etc). Kafka streams allows joins between streams and tables to do this with low latency and high throughput. Joins are mostly performed (except KStream+GlobalKTable) over the key (i.e. leftRecord.key == rightRecord.key), and there are therefore some partitioning/key requirements. You can also do joins between two streams.
A join is performed over a pair of input streams/tables. The output type is always the same as the 1st input (“left”) I.e. KStream+KX -> KStream, KTable+KX -> KTable. This table shows join permutations, with left and right inputs (row, column) and the join types and result type (cell):
| Left+Right join | Kstream | Ktable | GlobalKTable |
| Kstream | inner, left, outer (windowed) -> Kstream | inner, left -> Kstream | inner, left -> Kstream |
| Ktable | Invalid | inner, left, outer -> Ktable | Invalid |
The “trigger” event is normally from a left KStream. The exception to this is records with null keys or values, and for KStream+KStream joins when an event from either the left or right stream triggers the join.
Depending on the operands, joins are either windowed joins or non-windowed joins. KStream+KStream joins are always Windowed (sliding windows) in order to limit the amount of data involved in the join (as streams are unbounded by default). For KStream+KStream joins there can be an output record for each matching record on the right hand stream and there can be multiple such events. Each output record has the key of the leftRecord (which is the same as the rightRecord.key) and a new value provided by the user-supplied ValueJoiner (which is the 2nd argument of the join operation).
Records are output as follows:
leftRecord.key != null &&
leftRecord.value != null &&
leftRecord.key == rightRecord.key &&
abs(leftRecord.time – rightRecord.time) <= window size
→
KeyValuePair(leftRecord.key, ValueJoiner(leftValue, rightValue, joinedValue))
Here’s a simple (partial) example to find things (e.g. people and events) in the same location (e.g. travel destinations) in a week time window and make recommendations. The input topic has records with Strings <location, person/event>:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> people = builder.stream(“people-topic”); KStream<String, String> event = builder.stream(“event-topic”); KStream<String, String> recommendations = People .join(events, // ValueJoiner (leftValue, rightValue) -> leftValue + “ recommendation “ + rightValue, // Window duration JoinWindows.of(TimeUnit.DAYS.toMillis(7)), // Optional, if not present uses defaults from Configuration Joined.with( Serdes.String(), // key Serdes.String(), // left value Serdes.String()) // right value ) .to(“recommendations-topic“); |
If the people input stream has 3 records:
<london, elizabeth>
<venice, james>
<rio, mary>
And the attractions stream has 4 records:
<london, royalwedding>
<venice, biennale>
<rio, samba parade>
<rio, samba school rehearsal>
Assuming they all occur in the time Window then the output is:
<london, elizabeth recommendation royalwedding>
<venice, james recommendation biennale>
<rio, mary recommendation samba parade>
<rio, mary recommendation samba school rehearsal>
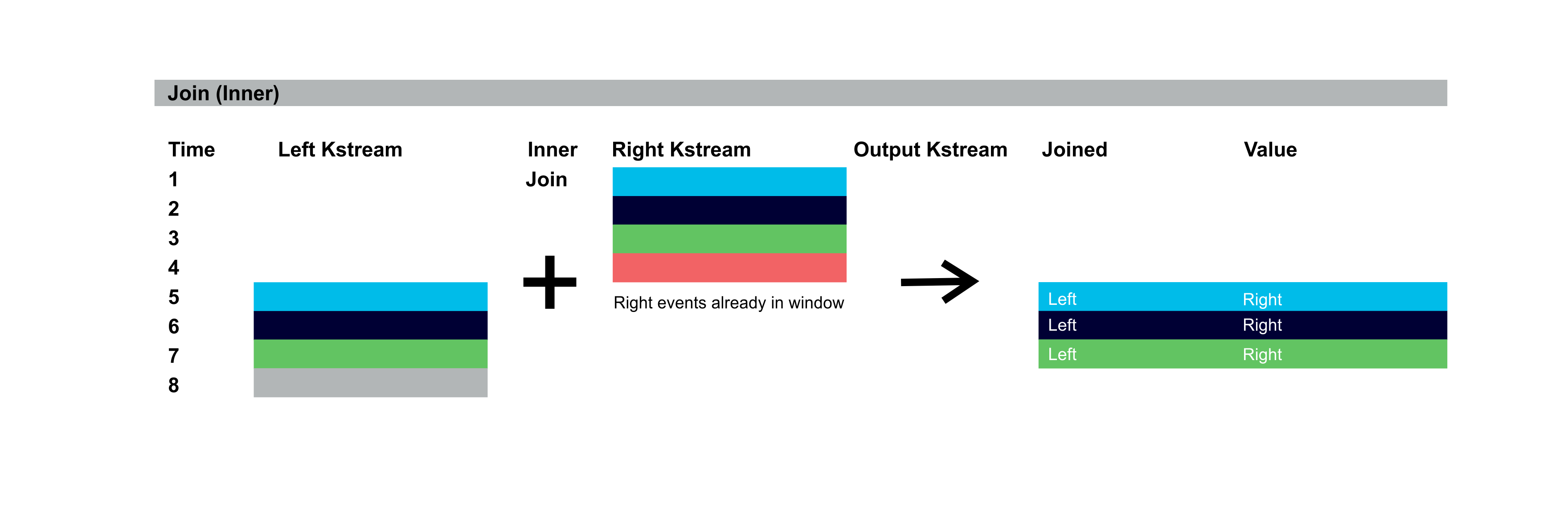
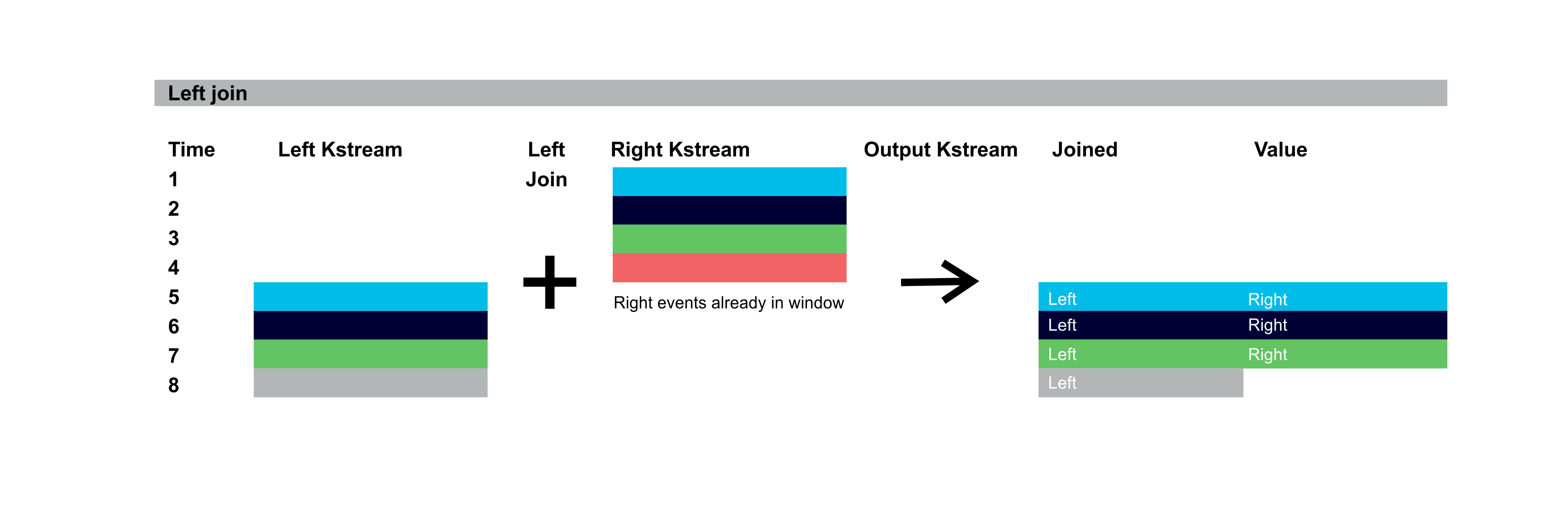
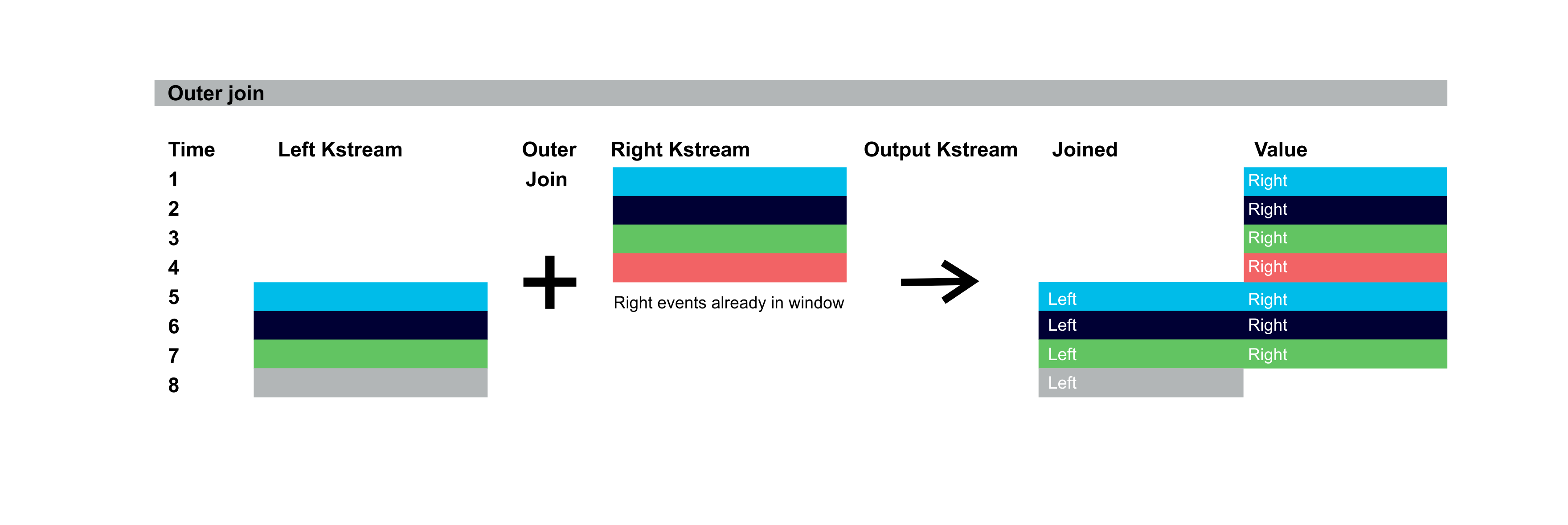
KStreams joins support Inner, Left, and Outer Join semantics similar to relational databases. The diagrams below illustrate the output records for inner, left, and outer joins over Left and Right KStreams. Colours represent records with the same key. The Right KStream events are assumed to have already occurred and are in the Window period and will potentially match with the incoming Left KStream events. The resulting records have either joined values (Left and Right), or just Left or Right values. Time flow down the screen. For the inner join, 4 events occur first on the Right KStream, but as there are no events in the Left KStream for the Window there is no output. Then 4 events occur on the left KStream. The first 3 events match keys already in the Right KStream Window and are output with joined values:
For the left join, only events on the left KStream trigger matching. As before the first 3 events in the Left Kstream match with keys in the Right KStream Window and are outputted with joined values. But as we’re using a left join the 4th event, which doesn’t match a key in the Right KStream, is output but with the left value only:
For the outer join, the first 4 events on the right KStream trigger matching, but as there are no events in the left KStream window outputs are produced with only the right values. And then the 4 events in the left KStream output events as in the left join case. A total of 8 output events are emitted for this example, 3 of them have joined values:
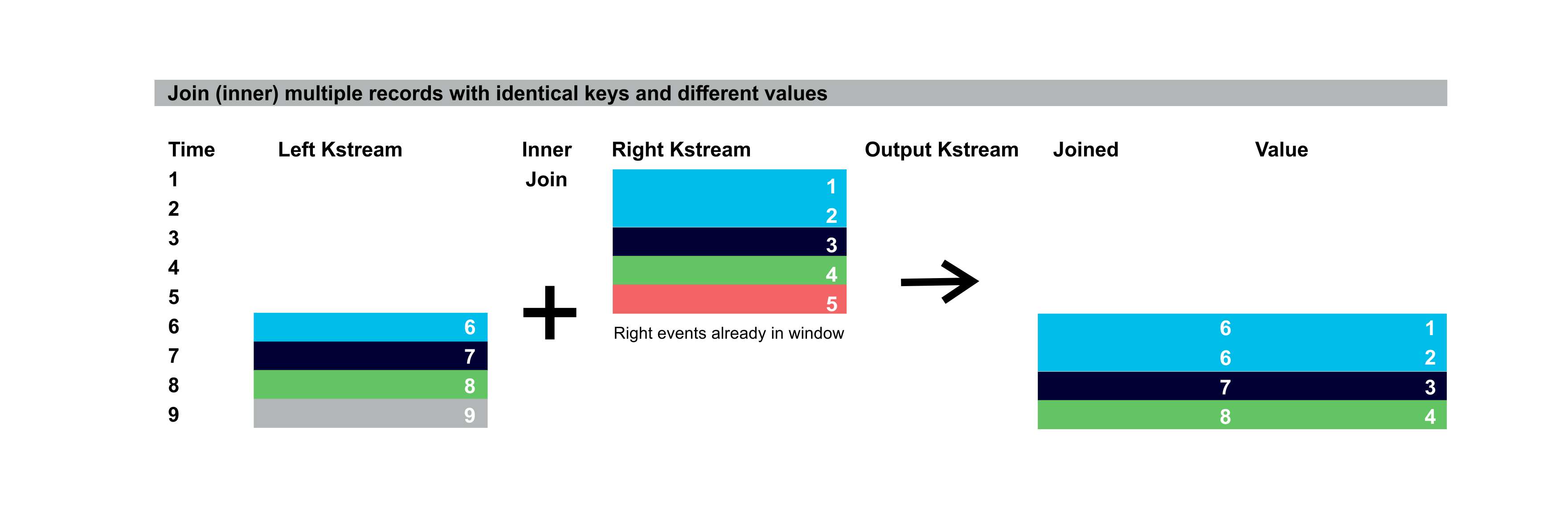
Unlike relational databases where records are unique per key, Kafka topics and streams can have multiple records for the same key. This can result in multiple records being emitted for a single input event as in the following example of inner join where there are two records in the right KStream window with the same key as an incoming event in the left stream (blue) resulting in two output events:
In the next blog, we’ll explore some examples in more depth based on the murder mystery board game Cluedo!
Related Articles:
- Apache Kafka Connect Architecture Overview
- Apache Kafka “Kongo” Part 6.2 – Production Kongo on Instaclustr
- Apache Kafka “Kongo” Part 6.1 – Production Kongo on Instaclustr
- Apache Kafka “Kongo: Part 5.3: Apache Kafka Streams Examples
- Apache Kafka “Kongo” Part 5.2: Apache Kafka Streams Examples
- Apache Kafka “Kongo” Part 4.2: Connecting Kafka to Cassandra with Kafka Connect
- The Instaclustr “Kongo” Part 4.1: Connecting Kafka to Cassandra with Kafka Connect
- The Instaclustr “Kongo” Part 3: Kafkafying Kongo – Serialization, One or Many topics, Event Order Matters
- The Instaclustr “Kongo” Part 2: Exploring Apache Kafka application architecture: Event Types and Loose Coupling
- The Instaclustr “Kongo” Part 1: IoT Logistics Streaming Demo Application