In this blog we deploy the Kongo IoT application to a production Kafka cluster, using Instraclustr’s Managed Apache Kafka service on AWS. We explore Kafka cluster creation and how to deploy the Kongo code. Then we revisit the design choices made previously regarding how to best handle the high consumer fan out of the Kongo application, by running a series of benchmarks to compare the scalability of different options. Finally (in part 6.2) we explore how to scale the application on the Instaclustr Kafka cluster we created, and introduce some code changes for autonomically scaling the producer load and optimizing the number of consumer threads.
Deploying Kongo to an Instaclustr Kafka Cluster
Instaclustr offers managed Apache Kafka 1.1 on AWS, Microsoft Azure, Google Cloud Platform, and IBM Softlayer.
There are a couple of Developer Node Sizes (t2.small and t2.medium, 20-80 GB Disk, 2-4 GB RAM, 1-2 cores per broker), and many Professional Node Sizes (r4.large-r4.2xlarge, 500-4,500 GB Disk, 15.25-61 GB RAM, 1-8 cores per broker). I initially spun up a 3 node Developer cluster for my experiments, which gave good performance (briefly), but soon realized AWS t2 instances provide burstable CPU resulting in the unpredictable behaviour. I then spun up a 3 node cluster on the smallest Professional Node Size:: r4.large, 500 GB Disk, 15.25 GB RAM, 2 cores per node, replication factor 3, both public and private IP addresses (public IP’s are optional), SCRAM (Salted Challenge Response Authentication Mechanism) Password Authentication and User Authorization, and no encryption enabled for EBS, client to broker or broker to broker.
It takes just a few minutes to start this sized Kafka cluster on AWS, and the Instaclustr console provides lots of useful information including a summary of the cluster state, monitoring graphs, information on cluster settings (e.g. Kafka allowed IP addresses in the Firewall rules), connection information (e.g. name, IP addresses, security settings, username and password, and connection configurations for Kafka clients (e.g. CLI, Java, Python, C#).
There’s also a new Kafka specific tab in the console which includes Kafka user management, and topics management. An Instaclustr specific version of kafka-topics (ic-kafka-topics) is available for topic management.
More information about the Instaclustr managed Kafka solution:
- The Instaclustr managed Apache Kafka solution
- Instaclustr Kafka support documents
- Free Kafka trial available from the sign-up page
Here’s an example screenshot of Cluster Summary CPU and Bytes in/out metrics provided by the Instaclustr Kafka console. Other metrics are also available.
 Benchmarking The Kongo Design
Benchmarking The Kongo Design
 Iceland River Delta (Source: Shutterstock)
Iceland River Delta (Source: Shutterstock)
Like river deltas with an alluvial fan many message-based systems have a large number of different destinations for the messages, and some may have a high consumer fan out. This is due to multiple consumers subscribing to the same events, resulting in a higher load on the output of the system than the input. The Kongo IoT application is like this.
Before going live with Kongo in production I wanted to check one of the design choices I made a few blogs back (One or Many Topics?). Kongo has a high consumer fan out. Because there are lots of locations and lots of Goods in each location, each Goods object needs to receive every event in each location. The initial design pattern had a Kafka consumer for each Goods, and a topic for each location. Each Goods was subscribed to the location (topic) where it was currently located, and received every event for that location. This didn’t seem to work well (at least on a laptop), so the design was changed to a single topic, and a consumer which passed events at a given location to all of the Goods that were subscribed to a Guava EventBus topic corresponding to that location.
I was curious to see if this was really the right choice given the larger resources that a real Kafka cluster offers. I benchmarked several variations to see what the general trends were. These benchmarks aren’t very scientific or rigorous (I didn’t tune anything, I didn’t explore all the variables, and I didn’t try and find the maximum capacity). However, they are realistic enough to support high-level findings as they include the relevant application logic and metrics. Namely, events for each location are passed to an onMessage() method in all of the Goods objects currently in that location (this counts as a consumer event), and end to end latency is measured from the time events are produced (the record timestamp) to the time of the onMessage() call. All topics had 3 partitions by default. I tried three alternative designs as follows.
Option 1
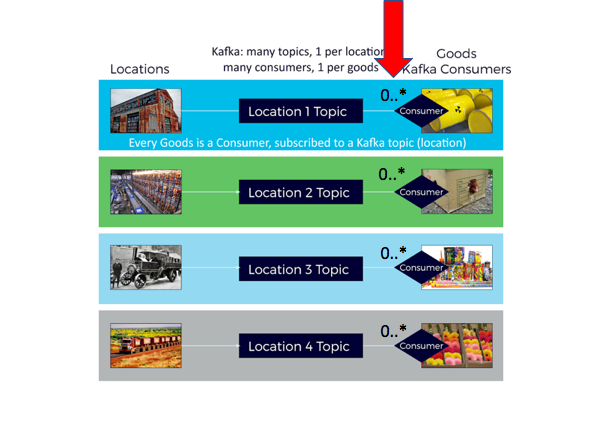
1 topic per location, multiple and increasing numbers of consumers per topic. Each Goods has a consumer which is subscribed to the topic corresponding to the current Goods location. Each consumer is in a unique consumer group, so each consumer gets every event for the topic/location it’s subscribed to. For benchmarking I used 10 topics/locations, and from 10 to 100 Goods. Kafka is responsible for the delivery of each event to multiple consumers. There may be a larger number of locations and therefore topics.
Here’s the original picture corresponding to Option 1, highlighting that each topic may have a very large number of Kafka consumers:
Option 2
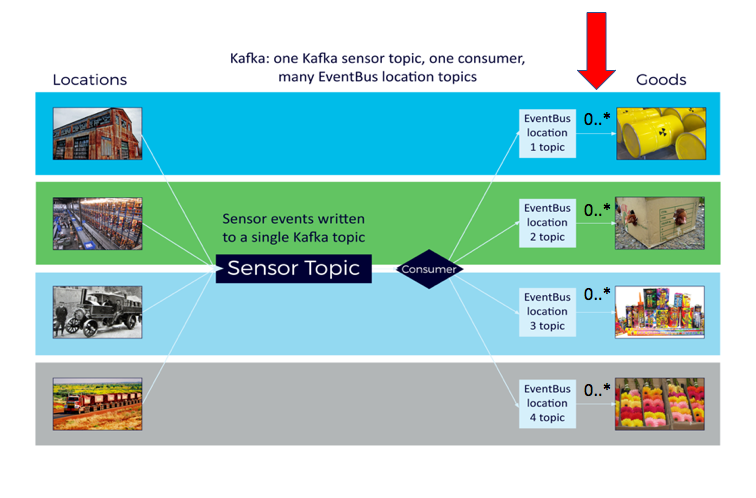
1 topic per location, exactly 1 consumer per topic (possibly more). Each consumer maintains a list of all the Goods that are to receive events at that topic/location, and passes each event to each Goods in the list. There may be a larger number of locations and therefore topics. However, because there is only 1 consumer per topic, Kafka is relieved of the fan-out problem, as the client-side consumers are responsible for delivering each location event to all of the Goods in that location.
Option 3
Exactly 1 topic, multiple consumers for the topic in the same group. The maximum number of (active) consumers is the number of topic partitions. Consumers have the most complex job in this version. They must maintain a list of locations and Goods in each location, and for each location event received from Kafka, deliver it to only and all of the Goods in the same location. I used a HashMap of <location, ArrayList<Goods>> for the benchmark code, in Kongo the Guava EventBus was used. This option best leverages the way Kafka is designed for consumer scalability by having multiple consumers per group over partitioned data. Events for all locations are sent to one topic, and Kafka distributes them equally among the available consumers.
Here’s the original picture for this option, highlighting that the client code handles delivery of the same event to multiple Goods:
Note that a potentially major simplification of the benchmark is that Goods are not moving locations (unlike the real Kongo application), so there is no overhead of changing the mapping between Goods and locations in the benchmark.
Here’s a summary of the options:
| Option | Topics | Consumers |
| Option 1 | Multiple, 1 per location | Multiple per topic, multiple groups per topic |
| Option 2 | Multiple, 1 per location | 1 per topic |
| Option 3 | 1 for all locations | Multiple per topic, 1 group per topic |
What are the likely tradeoffs between the options?
- Option 1 is the “simplest” as it uses Kafka to handle all event deliveries. It may also use the least client-side resources and have the lowest latency, as there is no overhead on the client-side after events are received, as each event is delivered to the correct Goods by design.
- Options 1 and 2 suffer from the problem that as the number of locations increases so does the number of topics (1 per location).
- Options 1 and 2 also suffer from the problem that if any of the consumers fails then the events to the corresponding Goods (option 1) and locations and Goods (option 2) will stop (unless the failure can be detected and new consumers started).
- In the case of Option 1 this would be harder as the consumers are stateful (a specific Goods subscribed to a specific location/topic).
- Option 2 could have multiple consumers in the same group subscribed to each location topic so may be more reliable (similar to Option 3).
- Option 3 is the most robust as it uses Kafka consumer groups to ensure that if a consumer fails the others take over automatically, and each consumer is stateless (but needs access to the global state of which Goods are in each location).
- Options 2 and 3 may result in increased latencies and require extra client-side resources as they handle event delivery to multiple Goods.
- Options 2 and 3 are similar to using application-level caching, once the data is in the application it can be reused multiple times without having to go back to the source.
- If event order matters (which it does for Kongo RFID events) then Option 3 is currently the only solution that will provide guaranteed event ordering (but only within partitions, so we’d need to ensure a 1-1 mapping between location key and partitions).
For simplicity the client side benchmark code was run on a single AWS t2.xlarge instance (4 cores burstable to 8 cores). A separate Producer and Consumer were used, and most results were run with the Producer set to 2 threads generating events as fast as possible for 10 locations, which loaded the Kafka cluster (3 nodes of r4.large instances with 2 cores each) to around 60-80% CPU utilization (i.e. there was still some spare capacity for consumers). With no consumers, this produced around 1,300 events per second going into the cluster.
Results
For all results, we compute the average latency (time from event production to the client calling onMessage for each Goods receiving the message), and the rate of event production (producer event/s). The rate of event consumption (consumer event/s) is also computed, but note that this is NOT actually the number of event/s consumed by the Kafka consumers, but rather an application-level metric of the number of events/s delivered to the correct Goods, i.e. there is significant fan-out. We also compute the total event rate as the sum of these.
For Option 1 the following graph shows the producer, consumer and total event/s with increasing total number of Consumers. There were 10 topics/locations, with an increasing number of consumers and Goods per topic (from 1 Goods per topic to 20 Goods per topic).
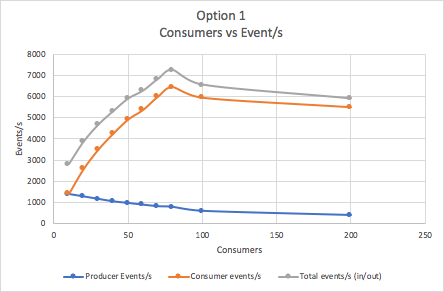
What’s interesting about this? As consumers increase the producer event/s rate drops, but the consumer events/s and total events/s rates increase. There’s some resource contention in the cluster with the consumers winning out causing a drop in producer rate. There’s also an “elbow” at 80 consumers, after which the consumer and total rate drops.
This graph shows that the average latency shoots up above 60 consumers:
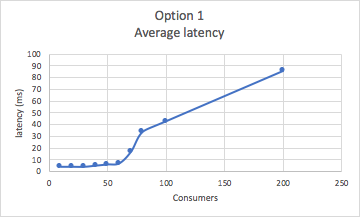
The scalability of this option is poor with a maximum of 8 consumers (Goods) per location/topic for 10 locations/topics for this sized cluster. Given that we have a target of 100s of locations and 1000s of Goods the only solution is a larger cluster or a different design.
For Option 2 we fixed the number of Goods at 100 (10 per location/topic/consumer, same as 100 consumers in Option 1) and increased the number of producer threads to see how far we could push the throughput. Not surprisingly this option is far more scalable and reached 100,000 total events/s as shown by this graph:
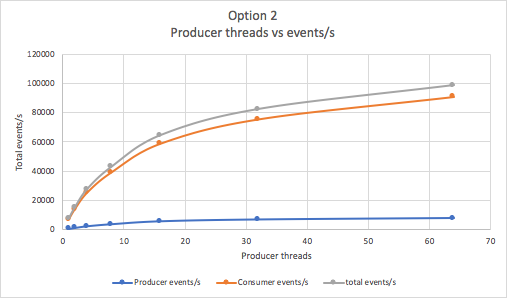
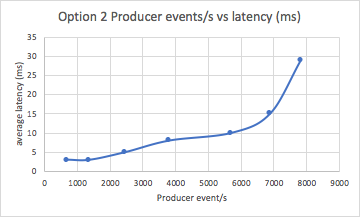
This graph shows that average latency shoots up above 6,000 events/s (16 producer threads):
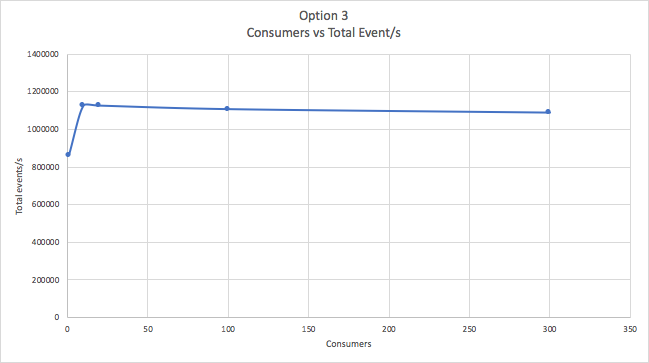
For Option 3 we used 2 fixed producer threads, 1 topic only, 100 locations (increased from 10 for increased realism and giving similar results), 100,000 Goods, and an increasing number of consumers (from 1-300, all in the same consumer group, so load balanced across 300 topic partitions). The number of Goods per consumer thread therefore decreases from a high of 100,000 per consumer to a low of 333.
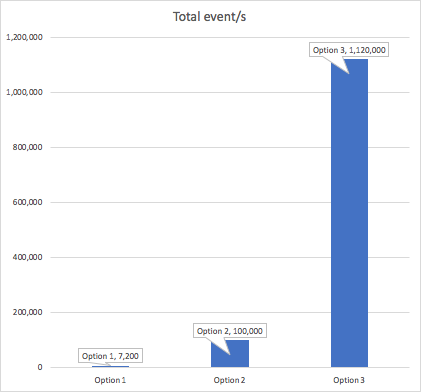
The following graph shows that the maximum throughput achieved was 1.12 million total event/s. For every input event, approximately 1,000 Goods received the event, an impressive fan-out ratio of 1,000:1.
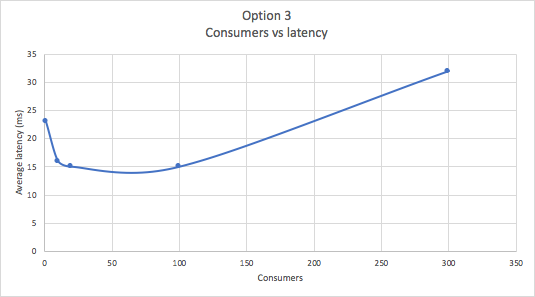
The following graph shows that as consumers increase the latency drops but then rises again. This suggests an optimal range of consumers to achieve a target throughput and latency SLA. Too few consumers and throughput and latency targets will not be met. Too many consumers and latency starts to increase again (although with a small reduction in throughput, as throughput is relatively stable).
The following graph summarizes the maximum throughput (total event/s) achieved for each option. Option 1 had 80 Goods, Option 2 had 100 Goods, and Option 3 had 100,000 Goods.
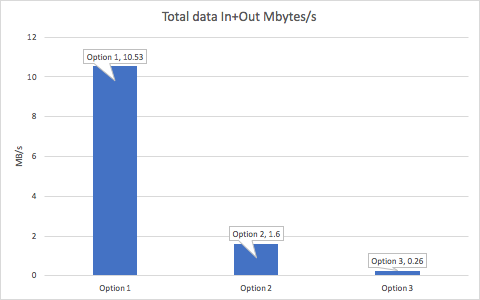
What’s really going on here? In terms of the amount of data in and out per second that the Kafka cluster is handling, there’s an obvious reduction with each option. Option 1 is the worst, as Kafka is responsible for sending each input event to multiple consumers. For the other options, there’s a significantly reduced load on Kafka as the consumers are responsible for “routing” events to multiple Goods objects. This means that the cluster has spare capacity for handling higher producer rates and more consumers (in a single group) to gain increased consumer scalability from multiple partitions. Average message size is 100 Bytes. This analysis also suggests that Option 3 probably still has spare capacity in terms of data bandwidth at least (if latency isn’t critical), and would probably benefit from larger Kafka cluster instance sizes (more cores).
Another observation is that the client application server is potentially doing as much or even more of the work for options 2 and 3 than the Kafka cluster.
In Kongo 6.2 we run Kongo in production.