
(Source: Wikimedia Commons)
A ZooKeeper walks into a pub… (actually an Outback pub)
The ZooKeeper notices a very rowdy crowd at a round table who appear to be fighting over forks, and she can’t avoid overhearing this conservation:
Karl (Marx): “Ludwig, I am hungry please lend me a fork”
Ludwig (Wittgenstein): “Karl, I don’t fully understand what you mean by the word ‘fork’”
Karl: “Ludwig, you are not sharing fairly! Niccolo, have you finished with your fork yet?”
Niccolo (Machiavelli): “No, it’s mine, I will never ever give you my fork!”
Karl: “Who invented these silly rules anyway?
Aristotle: “Dijkstra – a computer scientist – whatever that is!”
Karl: “Why can’t I stage a proletarian revolution and take control of all the means of production – I mean forks?”
Confucius: “Ritual leads to greater social harmony”
The ZooKeeper, being trained in the harmonious running of Zoos, goes over to see if she can help out with their resource sharing problem.
ZooKeeper: Gentlemen, perhaps I can be of assistance. Given my often complex and dangerous job as a ZooKeeper I’m sure I can be of service to you! None of my Tasmanian Devils have eaten any of the Wallabies – yet.
The Dining Philosophers (for that was the name of their club): Madam, thank you very much! We accept your kind offer, as some of us are very Hungry at present! Although we have no conception of how you will solve our intractable problem. But then at least we can get back to the more serious matters of Thinking and Eating, hopefully in approximately equal amounts.
So, let’s see how the ZooKeeper solves the Dining Philosophers Problem… Let’s “interview” the ZooKeeper first before we approach the argumentative Philosophers!
1. Apache ZooKeeper

Apache ZooKeeper recently became available as an Instaclustr Managed Service. In order to learn more about it, I browsed the Apache ZooKeeper documentation, watched a couple of ZooKeeper videos (older and newer) and read the O’Reilly ZooKeeper book, so what can I now tell you about ZooKeeper?
ZooKeeper is a mature technology. It originated as a subproject of Apache Hadoop and evolved to be a top-level project of Apache Software Foundation. It became the de facto technology for distributed coordination for much of the 2010’s so it’s used by numerous other projects, including Apache Kafka (currently at least, but see below).
ZooKeeper is designed for distributed systems coordination and meta-data storage, rather than for generic application data storage. It is therefore optimized (in order of priority) for Consistency, Availability, and Performance as follows:
- Consistency
A ZooKeeper cluster (called an ensemble) has a single leader for atomic writes, multiple replicas (for redundancy), and uses the ZAB (ZooKeeper Atomic Broadcast) protocol to ensure sequential ordering and consistency across replicas.
- Availability
A ZooKeeper ensemble supports high availability. If the leader fails another replica immediately takes over. And as long as there are a majority of non-failed servers working then ZooKeeper will still function. A ZooKeeper ensemble should therefore consist of an odd number of servers (e.g. 3, 5, 7), to support 1, 2, and 3 server failures respectively. ZAB also handles failed ZooKeeper servers and leader elections.
- Performance
All the objects are kept in memory so reads are very fast. But writes are slower as they are persisted to a disk log to ensure data durability in case of server failures. The ideal workload is therefore read intensive. To ensure good performance, objects should be kept small, as ZooKeeper is written in Java and garbage collection can easily become an overhead.
But what sort of objects does ZooKeeper store? ZNODES!
1.1 ZNODES
(Source: Shutterstock)
Appropriately, for a ZooKeeper, the only Apache ZooKeeper data structure is a tree (In Zoology, a phylogenetic tree, or “tree of life”, shows the relationship between different species).
The ZooKeeper tree provides a hierarchical namespace, with “/” as the root, and absolute path names such as:
“/Animalia/Chordata/Mammalia/Marsupialia/Dasyuromorphia/Dasyuridae/Sarcophilus/TasmanianDevil”
The namespace is similar to a file system, but each node can have data and children, and the nodes in the ZooKeeper tree are called ZNODES (but “nodes” in a ZooKeeper cluster/ensemble are called servers). ZNODE has version control, and atomic read/writes, and if used in an ensemble, is replicated.
ZNODES can be persistent or ephemeral. Persistent nodes are the default and outlive the client connection that created them. Ephemeral nodes are transient and exist only for the duration of the client session (and they can’t have children). They are useful for discovery of participants, and to trigger an election once a client vanishes.
Optionally, a ZNODE can be a sequence/sequential node (which has a monotonically increasing counter appended, and is therefore useful for locking and synchronization).
So, what can you do with ZNODES?
1.2 Operations on ZNODES
With ZNODES and the ZooKeeper API you can perform the following operations:
- create : create a znode
- delete: delete a znode
- exists: check if a znode exists
- getData: get/read the znode data
- getChildren: get a list of the znode’s children
- setData: set/write the znode data
Note that there is no setChildren operation, as you just create children.
Clients can also set watches on ZNODES. Any change to the ZNODE triggers the watch which sends a notification to the client. But only once, as the watch is then cleared (watches are one time triggers). If you want further notifications you must set another watch.
These operations are fairly low level, and all you can really do in ZooKeeper directly is create and delete ZNODES (in a hierarchical namespace), and write and read data to them, atomically. However, even these simple operations can be used to directly implement naming and configuration services, and group membership. And there are example recipes for higher level distributed systems operations such as Barriers, Queues, Locks, Two-phase commit, and Leader Election.
Now it’s time to find out how the Hungry Philosophers got into their predicament.
2. The Dining Philosophers Problem

The Dining Philosophers Problem is a classic distributed systems concurrency and synchronization control problem—it was invented by Dijkstra in 1965. Basically, the problem involves contention for limited resources (Forks), from multiple consumers (Philosophers). It goes like this:
There are N (normally 5) silent Philosophers seated around a circular table. In front of them they each have a bowl of (infinite) spaghetti. On their left and right is a fork. There is the same number of forks as Philosophers. To eat, a Philosopher must obtain both their left and right forks (in one version the forks are chopsticks, which makes more sense of the requirement to have both of them to eat). The Philosophers alternate between “thinking”, “wanting to eat” (hungry) and “eating”. A simple algorithm looks like this (for each Philosopher):
- “Think” for a random period of time.
- Enter “Hungry” state.
- Wait until the left fork is free and take it.
- Wait until the right fork is free and take it.
- “Eat” for a random period of time.
- Put both forks back on the table.
- Start from 1 again.
Now, because there are insufficient forks to enable all the Philosophers to eat simultaneously, some Philosophers will have to wait for one or both forks. And this isn’t all that can go wrong!
The problem illustrates some of the trickiest problems with distributed systems including starvation, deadlock, race conditions, and fairness. Good solutions minimize the hungry time and maximize eating concurrency and scalability with increasing philosophers. There are a number of solutions, but the most obvious is to use semaphores (also invented by Dijkstra) and timeouts around the forks, and a centralised Waiter (or ZooKeeper) to manage them. Although this can reduce the parallelism as the waiter can become the bottleneck (by introducing a delay even if the requested fork is available).
Just for fun, and to test out the ZooKeeper/Curator election functionality (see below), I came up with my own version and added a leader election to the problem, to allow one Philosopher at time to be the “Boss” and announce a topic of their choice at the start of their “Think” time (step1 and 3 are new):
- Check if I am the leader, if I am, then announce a topic of my choice.
- “Think” for a random period of time.
- If I was the leader, give up the leadership.
- Enter “Hungry” state.
- Wait until the left fork is free and take it.
- Wait until the right fork is free and take it.
- “Eat” for a random period of time.
- Put both forks back on the table.
- Start from 1 again.
For the final version we add wait timeouts to prevent deadlocks (100ms) and the Think and Eat times are randomly distributed from 1-1000ms.
- Check if I am the leader, if I am, then announce a topic of my choice.
- “Think” for a random period of time.
- If I was the leader, give up the leadership.
- Enter “Hungry” state.
- Wait (with timeout) until the left fork is free and take it.
- If I have the left fork then wait (with timeout) until the right fork is free and take it.
- If I have both forks, then “Eat” for a random period of time.
- If I have any forks then put them back on the table.
- Start from 1 again.
Here’s an example trace from the implemented version (i.e. after the ZooKeeper has intervened, see below):
Marx is Thinking…
Machiavelli is Thinking…
Wittgenstein is Thinking…
Aristotle is Thinking…
Confucius is Thinking…
Marx is Hungry, wants left fork 1
Wittgenstein is Hungry, wants left fork 2
Marx got left fork 1
Marx wants right fork 2
Wittgenstein got left fork 2
Wittgenstein wants right fork 3
Wittgenstein got right fork 3
Wittgenstein is Eating
Confucius is Hungry, wants left fork 5
Confucius got left fork 5
Confucius wants right fork 1
*** Marx gave up waiting for right fork 2
Marx putting left fork back: 1
Marx is the BOSS! Everyone now think about Aesthetics
Marx is Thinking…
Confucius got right fork 1
Confucius is Eating
Confucius finished eating! Putting both forks back: 5, 1
Confucius is Thinking…
Wittgenstein finished eating! Putting both forks back: 2, 3
Wittgenstein is Thinking…
Marx is no longer the BOSS
Marx is Hungry, wants left fork 1
Marx got left fork 1
Marx wants right fork 2
Marx got right fork 2
Marx is Eating
Wittgenstein is Hungry, wants left fork 2
*** Wittgenstein gave up waiting for left fork 2
Wittgenstein is Thinking…
Aristotle is Hungry, wants left fork 4
Aristotle got left fork 4
Aristotle wants right fork 5
Aristotle got right fork 5
Aristotle is Eating
Wittgenstein is Hungry, wants left fork 2
Machiavelli is Hungry, wants left fork 3
Machiavelli got left fork 3
Machiavelli wants right fork 4
*** Wittgenstein gave up waiting for left fork 2
Wittgenstein is the BOSS! Everyone now think about Epistemology
Wittgenstein is Thinking…
*** Machiavelli gave up waiting for right fork 4
Machiavelli putting left fork back: 3
Machiavelli is Thinking…
Confucius is Hungry, wants left fork 5
Marx finished eating! Putting both forks back: 1, 2
Everything seems to work more or less as expected with the Philosophers alternating between Thinking, being Hungry and waiting for and taking forks, Eating, putting forks back, and occasionally announcing a topic. Sometimes an impatient Philosopher will give up waiting for a fork and go back to Thinking instead (apparently they can’t Think if they are Hungry). It’s also noticeable that it takes some time for the leader election to occur and for a Philosopher to detect that they have been elected Boss, so sometimes there is no leader (I guess this just reverts back to the traditional rules where “free thinking” is the norm).
How did the ZooKeeper solve the problem? Well, in theory ZooKeeper can be used directly, but it is relatively low level. What we actually need is a Curator (Curators organize and interpret exhibits, including Zoo animals).

(Not all Aussie animals are actually out to kill you, in fact you are probably more likely to be injured by a Horse).
3. Apache Curator
A Curator also walks into the pub…
Apache Curator is a high-level Java client for Apache ZooKeeper. It provides lots of useful distributed systems recipes including Elections, Locks, Barriers, Counters, Catches, Nodes/Watches, and Queues. So, rather than use ZooKeeper directly to implement the Dining Philosophers, I decided to use Apache Curator.
The high-level design of the Java program is as follows, with some details fleshed out with the Curator example code below:
- Set up Curator Client, create Forks, create and start Philosopher threads.
- In each Philosopher thread, Think and Eat (and repeat).
- Terminate the Philosopher threads, compute and display metrics.
The Dining lasts for a fixed amount of time (60s currently) and then they all pack up and go home.
3.1 Curator Client
You use a CuratorFrameworkFactory object to create a CuratorFramework client to each ZooKeeper cluster. For example (for a single ZooKeeper running on localhost):
int sleepMsBetweenRetries = 100; int maxRetries = 3; String zk = "127.0.0.1:2181"; RetryPolicy retryPolicy = new RetryNTimes(maxRetries, sleepMsBetweenRetries); CuratorFramework client = CuratorFrameworkFactory .newClient(zk, retryPolicy); client.start();
To implement the Dining Philosophers Problem we used Leader Latch (for elections), Shared Lock (for forks), and Shared Counter (for metrics). The following examples are simplified (e.g. you also need error handling).
3.2 Leader Latch
Once started, each LeaderLatch negotiates with other participants that use the same latch path and randomly chooses one as the leader. You can check who is the leader with the hadLeadership() method. It can take some time to elect a leader, so in theory you should be able to check/block until a leader has been elected, but I couldn’t work out how to do this.
The only way to release leadership is with close(), which results in another participant being elected as leader, and then to be eligible for subsequent re-election you also have to create a new LeaderLatch and start() it. You also need to watch out for connection problems, which may cause a client to lose leadership.
// For each Philosopher thread
LeaderLatch leaderLatch = new LeaderLatch(client, "/mutex/leader/topic", threadName);
leaderLatch.start();
// Think
if (leaderLatch.hasLeadership())
System.out.println("I’m now the BOSS, think about X");
// Think for a while
// If thread was the leader then relinquish leadership, but rejoin pool again.
if (leaderLatch.hasLeadership())
{
System.out.println("I’m no longer the BOSS");
leaderLatch.close();
leaderLatch = new LeaderLatch(client, "/mutex/leader/topic", threadName);
leaderLatch.start();
}
// Hungry, try to eat, etc.
3.3 Shared Lock

(Source: Shutterstock)
I used the Shared Lock (InterProcessSemaphoreMutex) to implement fork sharing, as this ensures that no two Philosophers think they hold the same lock (fork) at the same time (just imagine the arguments!) We create an Array of Mutexes, so that each fork has its own semaphore (just like each train track has a signal). There are blocking and non-blocking acquire methods, we use the non-blocking method with a timeout so if the Philosopher can’t get the fork after a reasonable period of time they go back to thinking. However, once they have acquired the lock on both left and right forks they keep eating until they are satisfied – i.e. no other Philosopher can steal their forks while they are eating (which would inevitably cause fights):
int numForks = 5; // number of forks = number of Philosophers static InterProcessSemaphoreMutex[] forks = new InterProcessSemaphoreMutex[numForks]; // Create forks for (int i=0; i < numForks; i++) forks[i] = new InterProcessSemaphoreMutex(client, "/mutex/fork" + i); // In each Philosopher thread: // Hungry, want left fork int leftFork = 0; boolean gotLeft = forks[leftFork].acquire(maxForkWaitTime, TimeUnit.MILLISECONDS); // to release a fork forks[leftFork].release();
3.4 Shared Counter

Here’s an example of the Shared Counter used to count how many meals the Philosophers have eaten. Note that because ZooKeeper is persistent, we have to reset the counter to zero at the start of every run otherwise it will just keep incrementing forever. Also, the method trySetCount(int newCount) only succeeds if the value has not changed since the client last read it, so you need to get the current value with getCount() and a loop to ensure eventual success (similar to “optimistic concurrency” control):
int meals = new SharedCount(client, "/counters/meals", 0);
try {
meals.start();
meals.setCount(0);
} catch (Exception e1) {
e1.printStackTrace();
}
...
// In each Philosopher thread:
// Each time a Philosopher eats, increment the meal counter
// trySetCount returns true if it succeeds, else false and try again
boolean success = false;
while (!success)
{
int before = meals.getCount();
success = meals.trySetCount(before + 1);
}
...
// At the end of Dining, print out total meals
System.out.println("Total meals = " + meals.getCount());
4. Single Server and Ensemble Results
4.1 Baseline Results
One of the many advantages of open source software is that you can choose and easily change the scale of deployments with only a linear increase in price (mainly associated with the actual hardware resources, rather than licensing costs). It was therefore convenient to initially develop and test my Java based “Apache ZooKeeper (and Curator) meets the Dining Philosophers” demo on my laptop.
These are the instructions for running a standalone ZooKeeper, and Apache Curator is even easier to deploy as it’s just Java client code.
This enabled me to see how well the solution ran with the default number of five Philosophers and a single Apache ZooKeeper server. Five philosopher threads puts almost no load on the laptop. As well as the total meals eaten metric, I also added a few more metrics to compute the percentage of time (Utilization) the Philosophers spent in each activity (Thinking, Hungry, Eating), and Fork Utilization, etc. These extra metrics also put more load on ZooKeeper.
The results for Five Philosophers is the best-case scenario giving the following base level metrics to compare other results against:
Philosophers Thinking = 61%
Philosophers Hungry = 12%
Philosophers Eating = 27%
Note that in a perfect world where there is no resource contention for forks (i.e. each Philosopher has their own set of forks, which sounds more hygienic and closer to a correct solution to me!), then Thinking and Eating time would be approximately equal at 50% and Hungry time would be 0%. However, because of the design of the problem there will always be fork resource contention, and any change from the base level will therefore be attributable to overhead due to ZooKeeper (given that increasing the number of Forks and Philosophers doesn’t directly increase fork contention, and assuming that there are sufficient client resources).
4.2 ZooKeeper Ensemble Results

(Source: Maritza Rios – Wikimedia Commons)
Next, I tried two different ZooKeeper Ensembles using the Instaclustr managed Apache ZooKeeper service. The only difference for the Curator client is that you have to provide the list of ensemble servers (although there is also a way of discovering them given just one server).
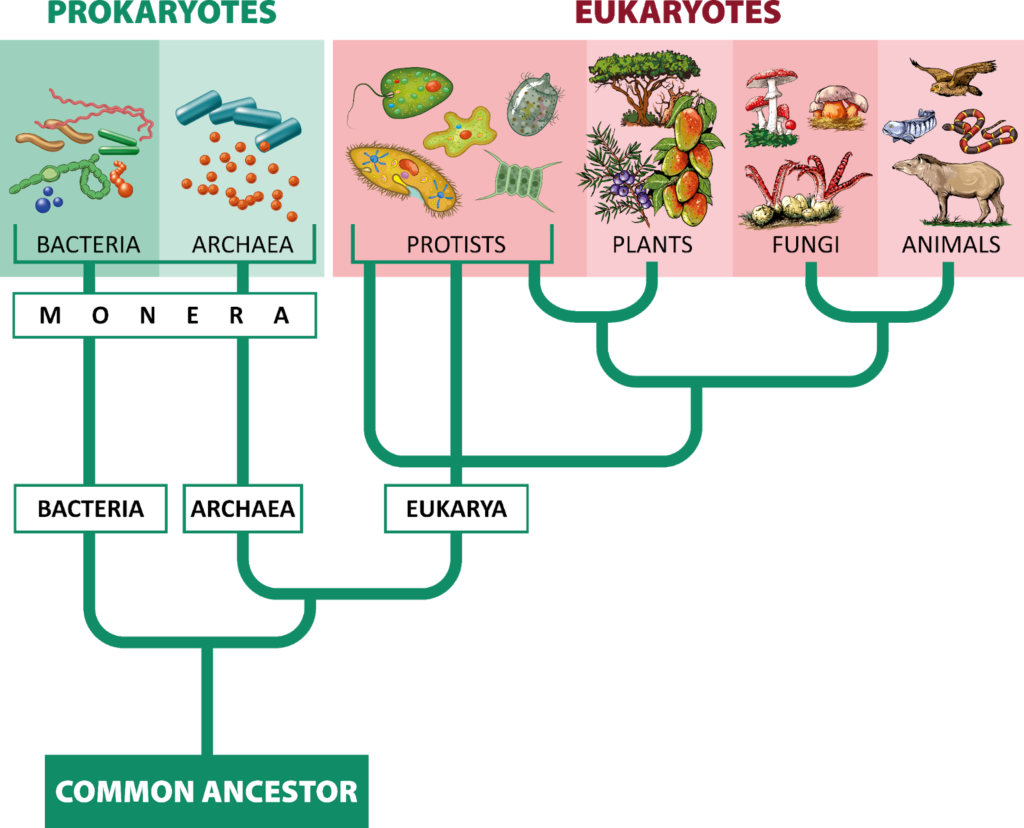
Both ensembles had 3 servers, one of which is the leader, and the other two are the replicas. I tried an ensemble with 2 vCPU core servers (“large” AWS instance types), and compared it to another with 4 vCPU core servers (“xlarge” AWS instance types), increasing the load by increasing the number of Philosopher threads from 5, until the meals eaten throughput (meals eaten per minute) dropped. The client machine was an 8 vCPU core server (AWS “2xlarge”) and was barely utilised. The following graph shows that the peak meals reached 3600 for the 2 core servers (for around 150 Philosophers) compared with 6400 for the 4 core servers (for 200 Philosophers), a factor of 1.8 times improvement.
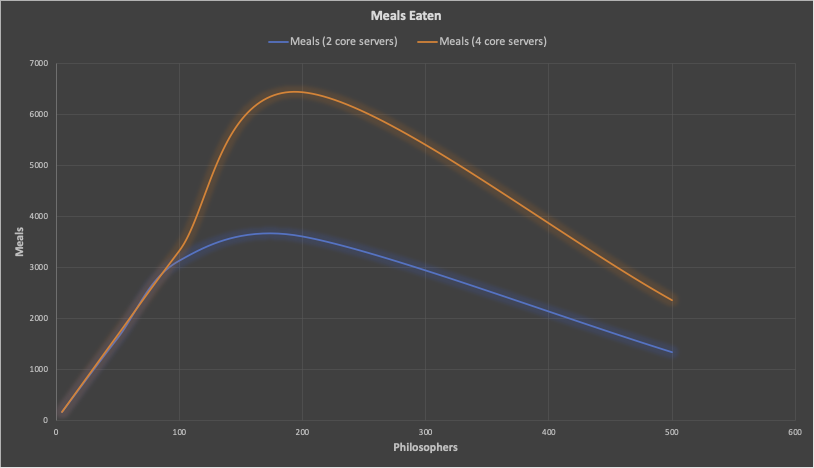
The following graph shows the (undesirable) increase in Hungry % with increasing Philosophers. Both ensembles start at the baseline of Hungry = 12%, but the 2 core server result (blue) increases more rapidly than the 4 core server result (orange).
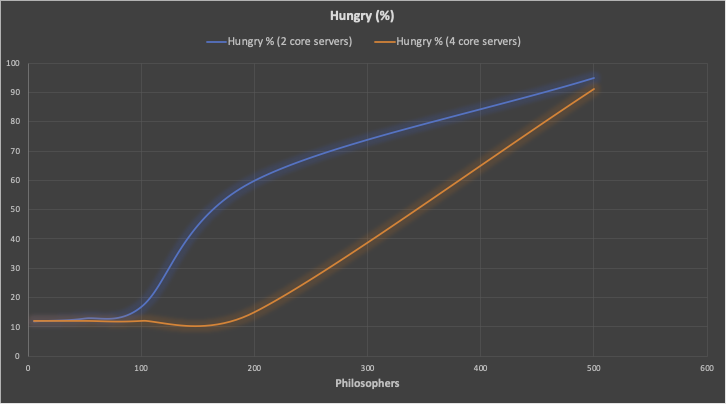
Even though the Dining Philosophers problem wasn’t specifically designed as a benchmark, and it’s not the ideal read heavy ZooKeeper workload, it does demonstrate the ability of ZooKeeper to scale with increasing load and with larger servers.
The peak number of ZooKeeper ops/s (mixed across get/set, acquire/release, and leader election – which is relatively infrequent by comparison at only 0.8 elections per second) achieved was 1,700 ops/s for 100 Philosophers (2 vCPU servers) and 3,600 ops/s for 200 Philosophers (4 vCPU servers). At maximum capacity the leader server was saturated, but the replicas had plenty of spare CPU capacity still (implying that more reads could still be served).
Finally, given that one of the goals of ZooKeeper is availability, how well did things work when one of the servers (e.g. the leader) failed? Fine! One of the other replica servers immediately took over transparently as the leader without any interruption of service. As expected, killing two servers (i.e. a majority of servers) resulted in Curator client errors.
5. Apache Kafka Exits the Zoo

One of the many Apache projects that use ZooKeeper is Apache Kafka. ZooKeeper is used by Kafka to store metadata about partitions and brokers and to elect a broker to be the Kafka Controller (currently there is only one Controller at a time). However, this will change in the future due to “KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum”.
Removing the ZooKeeper dependency will enable metadata to be managed more simply, more scalably and faster, and enable support for more partitions (potentially millions). It’s interesting to note that the “sweet spot” for ZooKeeper throughput was between 100 and 200 clients. This is possibly coincidental, but it also corresponds to my analysis of the optimal number of partitions for maximum Kafka cluster throughput.
How will the ZooKeeper dependency be removed? By using a replacement for ZooKeeper?
No. Kafka needs no Keeper. Fundamentally ZooKeeper is a distributed system for hierarchical data, and Kafka is a distributed system for streaming data. So the trick is to use Kafka itself to replace ZooKeeper, by using Kafka to store Kafka meta-data, using KIP-595: A Raft protocol for the Metadata quorum! Clever.
I’ve also noticed that as many of the Apache projects (e.g. Flink and Pinot) increasingly become “cloud native” and are deployed on Kubernetes, they are no longer dependent on ZooKeeper either, as Kubernetes has an equivalent co-ordination style of service, Etcd.
Of course, you are not limited to using ZooKeeper with Apache projects, and you can even build custom applications to take advantage of its unique features. This is how I got the idea to build a ZooKeeper demonstration application. When Kafka leaves the Zoo then the Dining Philosophers are welcome to fill the vacated enclosure, or even a new distributed system of your own invention. The demo code is available in our Github, and you can spin up a managed Instaclustr Apache ZooKeeper cluster here.