A complete rundown leading up to ApacheCon USA, starting a week before the final event. This blog provides a brief of things I learnt during the 4-day event, including a summary of talks I attended and presented.
1. Countdown begins: The week before ApacheCon
I’m looking forward to ApacheCon 2019 next week in Las Vegas. The Apache Software Foundation has been around since 1999 when it started out with a single project, their “Apache” HTTP Server. Fast forward to 2019 (20 years on) and there are 334 projects and 48 incubating! I’m expecting the conference to be abuzz with this level of activity on display. Three of the Open Source technologies that Instaclustr provides as managed services are Apache projects, Cassandra, Kafka, and Spark, so ApacheCon is an obvious choice of destination for Instaclustr to attend (as sponsors) and speak at this year. The conference spreads over 4 days next week with a great choice of presentations in multiple tracks including: Cassandra, IoT, Geospatial, Streaming, Machine Learning, and Observability! We have talks in the Cassandra and Observability tracks, but I’m attending (and blogging about) talks in other tracks that have interesting or challenging use cases (e.g. IoT, geospatial, ML, streaming, etc.), technologies that are complementary to Cassandra and Kafka, or that are directly competing to better understand the technical and business tradeoffs for our customers.
Just found out that one of my tech Gurus (ok, probably my only Guru) is speaking at ApacheCon next week! James Gosling (ring a bell? programming language, starts with “J”, type of coffee, etc.) is speaking on “My personal journey to Open Source”. Java was/is hugely influential because of its portability (JVM) and elegant Object Oriented language features, and I was intensely relieved when it came along as I could finally ditch “C” (and I hadn’t bothered to learn C++) and I’ve been using it ever since (25 years!)
 (Source: Shutterstock)
(Source: Shutterstock)
2. Destination Paris? Venice? Rome? New York?!—Las Vegas!
I’ve arrived! ApacheCon is being held in the Flamingo Casino/Hotel in Las Vegas. If you haven’t been to Las Vegas before (like me) arriving in Las Vegas comes as a bit of a shock. It’s essentially a Disneyland for grownups, with bright “neon” lights, casinos, 24-hour gambling, shows, crowds of people, but built in the middle of a desert miles from anywhere else. The whole city is hyperreal, the casinos on the “Strip” are mostly themed on famous world cities. There’s a half-sized Eiffel tower (and a two-thirds size Arc de Triomphe) in the French-themed casino (complete with famous French streets undercover). I had heard about the Eiffel tower, so I wasn’t too surprised.
 (Source: Paul Brebner)
(Source: Paul Brebner)
It was immediately apparent that it was appropriate to hold ApacheCon in this environment. Las Vegas is the pinnacle of artificiality, and scale (the Venetian is the largest hotel in the world!). And it’s built in the middle of a huge desert, nearby (via part of the old Route 66) one of the grandest natural features in the world, the Grand Canyon (which I saw after the conference, seems soooo big you can’t really appreciate its scale easily—you can occasionally spot the Colorado way down in the bottom of the Canyon).
 (Source: Shutterstock)
(Source: Shutterstock)
The Grand Canyon ends with the Hoover Dam, also a very large scale construction (it’s the size of the Great Pyramid of Giza, and the lake it created is the largest in the USA). So, the location is definitely appropriate for a conference about large scale software. However, I actually think that ApacheCon “out Vegased” Vegas! Vegas, although artificial, seems oddly constrained to copying real cities. I mean, where are all the moon or space travel to the stars themed Casinos?! ApacheCon isn’t as constrained—software really is only limited by imagination!
 (Source: Shutterstock)
(Source: Shutterstock)
Attending ApacheCon as a speaker/sponsor provided a great opportunity to mingle with interesting people, talk with Cassandra developers and big users, discover more about a range of Apache projects (core, complementary, competing), and hear some inspiring keynotes. If you didn’t get to ApacheCon this year I hope some of these insights will be useful and give you a feel for the ApacheCon vibe, and if you were there, there’s a good chance you didn’t get to all the same talks as I did (there were lots of tracks, and sometimes the same time slot had lots of interesting talks so I had to pick at random, sorry Ben!)
 (Source: Paul Brebner)
(Source: Paul Brebner)
3. Core Technology Talks (Cassandra, Kafka)
It’s amazing that the ApacheCon talks were so well attended given the various temptations just outside the door including real flamingos!
 (Source: Paul Brebner)
(Source: Paul Brebner)
Apache Cassandra (actually split over 2 tracks as they received so many Cassandra presentation submissions)
Apache Cassandra community health—Ben Bromhead, Scott Andreas
I’ll start with this presentation as it was by Instaclustr’s co-founder and CTO, Ben Bromhead, on the “state of the community”, from the perspective of a leadership position in a company with a long term (since 2013) interest in the Apache Cassandra project. Ben shared lots of revealing graphs of metrics relevant to community health, including trends in the number of issues created and resolved since 2014, code additions and subtractions, code commits, committer stats (there are more now than 2017), release activity, commits by top contributors, google search term trends, and database engines ranking.
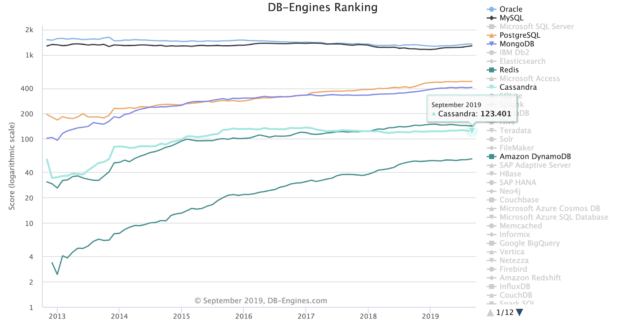
He also had some cautionary tales regarding Cassandra API compatible(ish) implementations (e.g. edge cases always crop up, all abstractions/translations are leaky!)
Based on the data, Ben concluded with some Instaclustr observations. Cassandra is increasingly the database of choice for large organizations building out an internal DBaaS capability (on-prem and cloud), and looking to reduce the risk of vendor lock-in. But Cassandra is still facing some challenges with project velocity, although efforts for 4.0 are likely to pay off in the longer term making it easier to introduce and test new features. He believes that the next 6-12 months are critical with the (potential) release of 4.0 for building back up velocity and interest in the project.
Two years in the making: What’s new with Apache Cassandra 4.0?—Dinesh Joshi
A quick summary of Dinesh’s talk (which is all my notes revealed) is that Cassandra 4.0 has taken 2 years to develop (and the focus has now shifted to testing as the project approaches an official release), and due to a variety of improvements (e.g. From Zero Copy Faster Streaming support to Virtual Tables and Audit Logging) will offer better operability, scalability, latencies, and recoveries. How good is that! Instaclustr plans to run our Cassandra certification framework and report the results for Cassandra 4.0 for the preview release.
 (Source: Paul Brebner)
(Source: Paul Brebner)
Casandra@Instagram 2019, Dikang Gu
(and Cassandra Traffic Management at Instagram, Michaël Figuière)
Instagram is a big user of Cassandra, with 1000s of nodes, 10s of millions of queries per second, 100s of production use cases, and Petabytes of data over 5 data centers.
They have developed a Storage API that supports Put, Get, GetRange, MultiGet, BatchMutate, and Delete in front of Cassandra, for multiple different client languages and applications. A clever architectural trick, leveraging this abstraction, is the use of Proxy Nodes for the Cassandra query path. Proxy Nodes significantly improve the read latency as they are dedicated to reads only. They can also be easily scaled as they are stateless. Another refinement is replacing Proxy nodes by a custom Cassandra gateway which has a smaller footprint and supports clients written in different languages. This also potentially facilitates future traffic optimizations including optimistic concurrency (a way of increasing concurrency in technologies such as Enterprise Java).
Another challenge they have, due to running multiple Cassandra data centers and having billions of users in different locations, is global replication and locality of reference. The solution is the Akkio data locality layer, and “sharding the shards”!
I was intrigued to hear they have developed a pluggable high-performance storage engine for Cassandra, using RocksDB, and appropriately named “Rocksandra”. I’d previously encountered RocksDB as it’s the state store used in Kafka streams (as the ktable backing store). However, it isn’t distributed, so it’s an “interesting” idea to make it distributed using Cassandra, while also improving the performance of Cassandra. They say it improves the p99 read latency by 10x. Just to add to the head-spinning-ness of this idea, over lunch one day of the conference I was chatting with Vincent Royer (Elassandra guy) and the conversation turned to replacing the RocksDB Kafka streams state store with Casandra. So, if this works out, you could run Cassandra as the distributed Kafka streams state store, but with RocksDB as the pluggable Cassandra storage engine (in theory).
This talk left me with several head-spinning ideas, and it was really eye (and brain) opening to better understand the challenges faced, and creative solutions developed by a very large Cassandra user such as Instagram.
How Netflix manages petabyte-scale Apache Cassandra in the cloud—Joey Lynch
Vinay Chella
Netflix is another big user of Cassandra, running more than 10,000 nodes. They provide a self-service console to their development teams to enable them to quickly and reliably provision, scale, manage, and delete Cassandra clusters. They have developed sophisticated automation for Cassandra, to enable declarative management, maintenance, and migration, and they mentioned a Cassandra sidecar project as a potential future home for this automation technology.
Of course, Instaclustr already offers a comprehensive managed Cassandra as a service, on multiple cloud providers, via the Instaclustr console and provisioning/monitoring APIs. We have also open-sourced a whole bunch of helpful tools to help with running your own Cassandra, see next talk.
Instaclustr’s Open Source Tools For Cassandra: LDAP/Kerberos, Prometheus Exporter, Debug Tooling and K8s Operator—Adam Zegelin
This talk (available here) was by one of Instaclustr’s Co-Founders, and SVP of Engineering, Adam Zegelin.
 (Source: Paul Brebner)
(Source: Paul Brebner)
Leveraging our extensive experience managing thousands of Cassandra nodes for our customers, Instaclustr has developed and made available these seven really useful Open Source Tools for Apache Cassandra:
- Instarepair, repairs for when repairs don’t work, it can pause and resume and throttle, get it here: https://github.com/instaclustr/instarepair/
- Cassandra-sstable-tools, for offline analysis of SSTables, including data model and compaction tuning, get it here: https://github.com/instaclustr/cassandra-sstable-tools
- Cassandra Kerberos Authenticator, application single sign-on for Cassandra CQL users – for more details see: https://www.instaclustr.com/blog/kerberos-authenticator-for-apache-cassandra/
- Cassandra LDAP Authenticator, to verify usernames/passwords against LDAP/AD for centralised user management, for more details see: https://www.instaclustr.com/blog/apache-cassandra-ldap-authentication/
- Cassandra Backup & Restore Tool, takes snapshots, uploads snapshots to cloud storage or remote file systems, has throttling and automatic “de-duplication”, get it here: https://github.com/instaclustr/cassandra-backup
- Cassandra Prometheus Exporter, exporter for Cassandra metrics, fast (134ms!), bypasses JMX (which is slow), easy to use, knows about Cassandra specific metrics, and follows Prometheus guidelines for metrics naming, get it here: https://github.com/instaclustr/cassandra-exporter
- Cassandra Operator for Kubernetes, an operator for running Cassandra on K8s! Provides Cassandra-as-a-Service on top of Kubernetes, or “Instaclustr in a box”! Features include safe scaling, backups, repairs, security, and Prometheus integration for monitoring, get it here: https://github.com/instaclustr/cassandra-operator
The Flamingo pool party was an ongoing distraction.
 (Source: Paul Brebner)
(Source: Paul Brebner)
Apache Kafka
Apache Kafka vs. Integration Middleware (MQ, ETL, ESB) – Friends, Enemies or Frenemies?—Kai Waehner
I attended this talk as I’m from a middleware background, and I’m very interested in trends around microservices and integration. I also knew that Kafka was developed by Linkedin as a scalable pub-sub messaging system, to migrate a complex point to point integration architecture to centralized scalable data pipeline. Kai emphasised the well-known features of Kafka that make it suitable (by design!) for use as enterprise middleware including being event-based, real-time streaming, massively scalable, high availability and reliability, persistent, decoupling between clients provides idea endpoints for microservices, handles back-pressure (i.e. acts as a buffer), etc. Kafka is designed as a “dumb” broker, allowing for smart clients. This also ensures that all the components are independently scalable and reliable.
Somewhat surprising was the warning that businesses may inadvertently introduce an anti-pattern into their use of Kafka based on the “old” ways of providing a single centrally managed heavyweight ESB (this was originally a Thoughtworks observation). Instead, the recommendation is to allow product teams to manage their own connectors and stream applications. From an agility perspective this does make sense, but teams typically don’t want to (and don’t have the experience) to manage these components from an operational perspective. Best-practice is for teams to use a managed provider such as Instaclustr’s managed Kafka service to manage at least the Kafka clusters (yes, multiple Kafka clusters make sense) and Kafka Connectors. Our experience in the recent Anomalia Machina project shows that it’s relatively easy for developers to use technologies such as Kubernetes to manage (and scale) Kafka applications (which includes Kafka streams).
Of course, there are some uses where you still need to run multiple middleware technologies at the same time (e.g. during migrations, for legacy systems, for request-response patterns etc.), and Kafka is well suited for integration with other systems, and has some tricks of its own including the use of correlation Ids for request-response patterns, and using interactive queries for external applications to access state resulting from streams processing.
Finally, Kai suggested that once Kafka is introduced into an enterprise as a data integration pipeline, new microservice components can be developed which just interact with Kafka. I asked Kai if he had seen any trends in the use of microservices frameworks with Kafka, but he hadn’t seen any convergence to any particular framework yet, which suggests that using Kafka as a microservices platform is still in its early days, with lots of rapid (and possibly divergent) developments likely in the near future. I did notice that he has another talk (not presented at ApacheCon) on this exact question, where he suggests Kubernetes, Envoy, Linkerd, and Istio (some of our suggestions as well).
 (Source: Paul Brebner)
(Source: Paul Brebner)
Processing IoT Data from End to End with MQTT and Apache Kafka—Kai Waehner
This talk focused on the use of MQTT with Kafka. MQTT is an IoT protocol specifically tailored for constrained devices, unreliable networks and large numbers of devices/connections. Use cases include cars, robots, machines, drones, smart cities, etc. However, it doesn’t support streaming, scalability, buffering, etc. Kafka, on the other hand, is designed for these and more, but not for large numbers of connections and other IoT specific features. The solution is to match them together. When matching them, Kai mentioned a number of things you need to take into account including throughput and latency requirements, ingestion from devices to Kafka only or bi-directional communication for control of devices as well, integration patterns, pull vs. push, mapping many devices to fewer topics, and IoT specific features.
I discovered that there are multiple possible integration architectures. The first uses the MQTT broker with Kafka Connect. This is the most feature-rich pipeline, is entirely open source, but does require running the MQTT broker somewhere. The alternatives are a MQTT proxy (not open source) or the REST proxy (open source). A custom Kafka client is also possible.
The REST Proxy is a particularly good choice as it’s available as an add-on with the Instaclustr managed Kafka service. The REST Proxy is appropriate for integration of both Java and non-Java MQTT applications with Kafka, is simple and well understood, has easy security, is scalable with standard HTTP load balancers, but is only suitable for use cases with lower throughputs.
Kafka, Cassandra and Kubernetes at Scale: Real-time Anomaly detection on 19 billion events a day—Paul Brebner
Ok, I didn’t really attend this talk as I presented it in one of the Cassandra tracks. This was a summary of my Anomalia Machina blog, demonstrating the scalability, performance, and cost-effectiveness of a combination of Apache Kafka, Cassandra, and Kubernetes, with results from our experiments allowing the anomaly detection application to scale to 19 Billion anomaly checks per day, the full talk is available here.
4. Complementary Technologies (GeoMesa, Druid, Flink, Lucene, Prometheus, OpenTracing)
 (Source: Paul Brebner)
(Source: Paul Brebner)
Apache GeoMesa
Using GeoMesa on top of Apache Accumulo, HBase, Cassandra, and big data file formats for massive geospatial Data—James Hughes
GeoMesa is a suite of Apache-licensed, open-source tools for streaming, persisting, managing, and analyzing spatio-temporal data at scale. Geomesa uses 3 foundational libraries (JTS, Spatial4J, SFCurve) for Geometry, Topology, and Indexing. It leverages Kafka for streaming, Cassandra for persistence, and Spark and Zeppelin for analysis at scale.
The talk focused on the issues surrounding indexing and querying geospatial data in key-value stores, including Cassandra. This resonated with me as this is precisely the problem I was looking at in my recent blog series (Geospatial Anomalia Machina). For Cassandra, GeoMesa uses Z2/Z3 filters, CQL/Transform filters, and other specialized filters, and for streaming data, the GeoMesa Kafka data store for in-memory indexing. James mentioned another project, GeoWave, which adds support for multi-dimensional indexing, geographic objects and geospatial operators to Cassandra and other distributed key-value stores.
This talk was an interesting summary of GeoMesa, explaining the purpose, architecture, supporting technologies, and problems/solutions to indexing and queries, concluding with an impressive demonstration of real-time visualisation of big geospatial data! I talked to James after the talk and received a personalised demonstration, it looked like GeoMesa would be a good fit for visualising the results of my Geospatial Anomalia Machina application.
 (Source: Paul Brebner)
(Source: Paul Brebner)
Apache Druid
Inside Apache Druid: Built for High-Performance Real-Time Analytics—Surekha Saharan
Druid is another Apache project that I’ve been interested in for a while. It’s designed for interactive/ad-hoc analytics processing, and as it integrates nicely with Cassandra and Kafka it’s complementary to the Instaclustr platform. Prior to ApacheCon I had arranged to meet up with Surekha, but fortuitously I bumped into her at the speakers’ reception so I got a preview of what her talk was going to cover. Apache Druid is a high performance, open source analytics database built for event-driven datasets. Druid is designed to address the challenges of scale, speed, complexity, high data dimensionality, user concurrency, and data freshness. It is high performance (low query latency, high ingest rates), has powerful analytics (counting, rankling, grouBy, time trends), an internal data store (that integrates to other data stores such as Cassandra, and ensures freshness of data), and is event-driven (so addresses use cases such as clickstream analytics, network flows, user behaviour, digital marketing, service metrics, IoT, etc., and integrates well with Kafka). Of relevance to Instaclustr customers is that Druid can easily be integrated with Cassandra, and Kafka, and can be deployed to cloud providers such as AWS.
Because I’d recently experimented with, and blogged about, geospatial extensions to the Anomalia Machina application, I went along to a few talks from the Geospatial track to find out what the real experts in the field are doing (even if they were using different technology mixes to ours)—and this track had nice pictures.
Apache Flink
GeoSpatial and Temporal Forecasting in Uber Marketplace—Chong Sun, Brian Tang
The problem Uber faced was forecasting from spatiotemporal data. For example, Uber drivers use an app that shows them current and forecast busy regions, so they can decide if it’s worth changing areas. The challenge is that some areas have sparse data, so Uber needed to aggregate data for accurate forecasts. To do this they use a geospatial representation based on hexagons and the H3 library (for indexing).
 (Source: Paul Brebner)
(Source: Paul Brebner)
This is very similar to the problem I faced with my geospatial anomaly detector application, as you need to be able to use data from an arbitrary area, so fixed-size areas aren’t sufficient. The technology they used is Apache Flink (DAG streams processing), with Kafka as the source and sink, and Cassandra as the data store. Flink was used for feature extraction, model building, and model prediction.
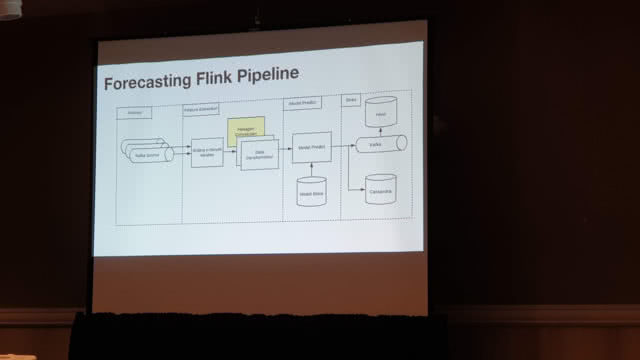 (Source: Paul Brebner)
(Source: Paul Brebner)
The hexagons act as a geohash, with nice properties including uniform adjacency, and low shape and area distortion, giving them the ability to change the resolution from block to city-scale (and beyond, to global scale, with vertices conveniently located in oceans, where Uber currently doesn’t have drivers!) One or a few hexagons are used for block scale, with 500,000 hexagons for San Francisco city scale.
How well did it work? Every minute they process 30 million hexagons for 700 cities to forecast 10 metrics. And they did this with significant savings. Moving to Flink (from Java) and using hexagons reduced the total core count from 3800 to 500 cores. The takeaways I took away from this talk are that (1) picking the right representation and having an efficient pipeline framework are critical for many problems, particularly geospatial processing, and (2) Apache Flink integrates well with Kafka and Cassandra, and Flink appears to be equivalent to Kafka Streams and KSQL.
Apache Lucene
Geospatial Indexing and Search at Scale with Apache Lucene—Nick Knize
I went to this talk because I’d previously experimented with using the Cassandra Lucene Index, which is supported by Instaclustr. As I’d found out in my experiments, how geospatial coordinate systems and geoshapes are indexed makes a huge difference to the performance of database queries, e.g. on Cassandra. Apparently “Block K Dimensional Trees (Bkd)” combined with “Tessellation decomposition” is the secret to efficient geospatial indexes, and shape intersection queries (introduced in Lucene 7.4). Lucene 8.2 introduced the XYShape (for Tessellating & Indexing Virtual Worlds), giving faster indexing of shapes—nearly as fast as points.
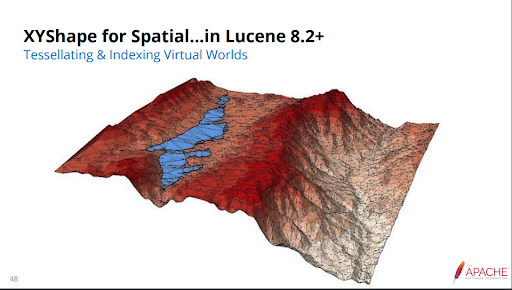 In progress are non-terrestrial planet models, 3D shapes, and geodistance aggregation. Hopefully these features will eventually be incorporated into the Cassandra Lucence plugin.
In progress are non-terrestrial planet models, 3D shapes, and geodistance aggregation. Hopefully these features will eventually be incorporated into the Cassandra Lucence plugin.
Prometheus, OpenTracing/Jaeger (Observability)
Improving the Observability of Cassandra, Kafka, and Kubernetes applications with Prometheus and OpenTracing—Paul Brebner
This was the talk I gave in the Observability track at ApacheCon, focusing on complementary technologies (although not Apache tech this time). As distributed applications grow more complex, dynamic, and massively scalable, “observability” becomes more critical. In this presentation, I explored two complementary open source technologies: Prometheus for monitoring application metrics, and OpenTracing and Jaeger for distributed tracing. I concluded by exploring the benefits of monitoring and tracing technologies for understanding, debugging, and tuning complex dynamic distributed systems built on Kafka, Cassandra, and Kubernetes, see the full talk here.
Another talk in the observability track that I intended to attend, but ran out of time for, was on Apache Skywalking, probably worth checking out if you are interested in a fully-featured cloud-native Open Source APM.
5. Competing Technologies (Pulsar)
 (Source: Paul Brebner)
(Source: Paul Brebner)
Messaging systems have been around for a long time, and different approaches have different features and tradeoffs. I was talking with an interesting gentleman at the ApacheCon speakers reception (on the 1st night of the conference), covering a variety of interesting topics including robotics, the ethics of computer science, and Japanese Pachinko gaming machines (an appropriate topic given the pervasiveness of gambling in Las Vegas). He mentioned that as a teenager he worked on satellite data processing, which, because of dual military and civilian use had to cope with significantly reduced throughput and latencies when the military wanted more capacity. As a result, a message was often sent multiple times, requiring eventual deduplication. In general, exactly-once semantics is a hard problem to solve. We were in the middle of discussing how this could be done with Kafka when a few other people suddenly recognized James Gosling (whoops, I hadn’t recognized him, lucky I hadn’t said anything silly about Java), and joined the conversation. Given that his secret was out, the conversation then naturally turned to Java. It was interesting to discover which languages that pre-dated Java we both knew (e.g. BCPL, which was similar to Java in that it was easily portable—it had an intermediate language like Java—but only a single data type), and hear that the intent behind the JVM wasn’t (as I had always assumed) primarily portability, but rather optimization for different target devices (or more technically, it had good architecture neutrality). Of course, platform portability was one of the enduring benefits of Java.
Apache Pulsar
It’s interesting to observe that Apache is big enough to support multiple projects in similar spaces. For example, even though Apache Kafka was the dominant streaming technology at ApacheCon (16 talks), another Apache streaming technology, Pulsar (from Yahoo), also had a sizeable presence (6 talks). This resulted in sometimes lively discussions about the merits of the different technologies. As a result, I picked up a few things about Pulsar that are different from Kafka. For example, Pulsar has a loosely coupled independent storage layer, so that storage and CPU can be scaled independently. This means that brokers are stateless so horizontal scalability is fast, as there is no partition migration or rebalancing overhead for adding broker nodes or changing consumers. Another common claim was that Pulsar supports millions of topics (possibly due to the different way Pulsar manages message replication).
Another difference is that Pulsar Functions support many operations running on the brokers, including content-based routing, filtering, transformations, alerts, and thresholds, windows, and counting. In contrast, Kafka doesn’t support these operations on the brokers, as a result of the original Kafka design decision to keep the brokers “dumb”. Instead, these sorts of operations are supported by Kafka Streams or Consumer/Producer applications, deployed on their own resources. In practice this means that the scalability of Kafka may be better as these operations don’t impose any overhead (apart from reading/writing events) on the Kafka brokers, and can be scaled independently (my experiments with Anomala Machina show that independent scaling of the “application” is critical for the overall system scalability, as they can consume more resources than the brokers themselves).
6. ApacheCon Keynotes (“vi sucks”, and “Time expands to accommodate your passions and priorities”)
As I expected, a highlight of ApacheCon was the inspiring keynote by James Gosling. After chatting with him informally at the speakers’ reception, some of his experiences as a computer scientist made more sense in the context of his long career. Here he is working on the ISIS 2 satellite code.
 (Source: Paul Brebner)
(Source: Paul Brebner)
He recounted that his first experience of open source was reading the source code of the Pascal compiler (which came on a tape, along with the binary), and he almost didn’t complete his PhD due to the effort of writing and then supporting Emacs on UNIX (“vi sucks”, indeed).
 (Source: Paul Brebner)
(Source: Paul Brebner)
James credited Ivan Sutherland as the Father of Object Oriented programming and therefore Java (Ivan invented Sketchpad, the first program with a GUI and an object model pioneering objects and instances, astonishingly it ran on a 1958 computer which had a screen and a light pen as input!) Sun Microsystems was “full of hippies”, so after he developed Java it was open sourced (but with a complex license). Solaris was not so lucky.

He issued a timeless warning for the Open Source community: platform providers want stickiness, but proprietary extensions always limit portability (which is what developers value most).

James finished with a resounding endorsement of the “Apache Way” of Open Source due to a “clean license, community, code of conduct, and committers”.
 James had a hard act to follow, as his keynote followed another keynote, by someone at the other end of the career lifecycle, Samaira Mehta, of CoderBunnyz fame (a board game for kids to learn coding). She was confident and polished, has at least one superpower (access to a time machine—“Time expands to accommodate your passions and priorities”), and I was bowled over when I found out afterwards that Samaira is 11 years old!
James had a hard act to follow, as his keynote followed another keynote, by someone at the other end of the career lifecycle, Samaira Mehta, of CoderBunnyz fame (a board game for kids to learn coding). She was confident and polished, has at least one superpower (access to a time machine—“Time expands to accommodate your passions and priorities”), and I was bowled over when I found out afterwards that Samaira is 11 years old!

 (Source: Paul Brebner)
(Source: Paul Brebner)
Instaclustr was a Silver Sponsor of ApacheCon USA 2019, here’s some of our friendly staff at our booth. Find out more about Instaclustr’s managed platform for Apache technologies.
I’ll also be speaking at @ApacheCon Europe! #ACEU19 (October 22-24, Berlin). Take a look at the topics and join us at the event: https://t.co/mTnkqSP9Y1
Tickets are still available for #ACEU19 at https://en.xing-events.com/vi/aceu19
