Today Instaclustr has released beta support for Apache Cassandra 2.2 across all our plans. This article goes under the hood to explore some of the key changes and features in this latest version.
1. Majority of 3.0 features were released in 2.2
Cassandra 3.0 has seen a complete rewrite of the storage system. Given the scope of that change, and to provide early access to other new features scoped for 3.0, the interim 2.2 release candidate was taken. This was a good decision and reduced the size and risk of the 3.0 release. This means the majority of features originally planned for 3.0 are released in 2.2, mostly just leaving the storage system refactor for 3.0. This should also make the upgrade path a little smoother and less risky.
The new features in 2.2 aren’t major modifications to the storage engine. You can safely upgrade from 2.1 to 2.2 without too much risk to existing functionality, although we definitely recommended stabilising on 2.2 before upgrading to 3.0.
2. There are no more Users
Cassandra 2.2 makes a major update to authentication and authorization with the introduction of roles based access control. This change makes it easier to more consistently manage permissions where you have multiple users accessing your Cassandra cluster. Internally, this has been implemented with a change to the schema of the system_auth keyspace. Users and permissions are replaced by Roles and Role Permissions, the credentials table has been merged with the users table meaning usernames and passwords are stored together.
Legacy CQL commands such as CREATE USER have been retained for backwards compatibility and convenience.
The table below summarises the changes to the system_auth keyspace.
| Cassandra 2.1 | Cassandra 2.2 |
CREATE TABLE system_auth.credentials ( |
|
CREATE TABLE system_auth.users ( |
CREATE TABLE system_auth.roles ( |
CREATE TABLE system_auth.permissions ( username text, |
CREATE TABLE system_auth.role_permissions ( |
CREATE TABLE system_auth.role_members ( |
For a detailed explanation of how to use roles and permissions in your cluster, see the Jira ticket and this article from Datastax.
If you are upgrading from earlier versions of Cassandra the system_auth keyspace schema will be transparently migrated on startup.
3. CQL3 – JSON, UDFs, and more DATE functions.
The latest version of CQL introduces the ability to INSERT and SELECT with a JSON-like syntax. You don’t need to update your client drivers to take advantage of this new feature, just include the JSON keyword in your prepared query:
|
1 2 3 4 5 6 7 |
INSERT INTO nodes JSON '{ "name": "m3.xlarge", "disk_quota": 80, "memory_quota": 15000, "cpu_cores": 4, "ssd_backed": "true", }'; |
This version also introduces User Defined Functions, which allows the user to execute arbitrary functions on returned rows. This will likely be a useful feature for many users, but until some security exists around UDFs (to be release in Cassandra 3.0), we will disable UDFs by default (which is also the Cassandra default in this version). If you are considering the need UDF support then please contact [email protected] and we can discuss how we can meet your requirement.
There are seven new functions to manipulate timeuuid and timestamp types.
dateof |
Depreciated, replaced by toTimestamp |
unixtimestampof |
Depreciated, replaced toUnixTimestamp |
toDate(timeuuid) |
YYYY-MM-DD |
toTimestamp(timeuuid) |
1447748464728 |
toUnixTimestamp(timeuuid) |
2015-11-17 08:21:04+0000 |
toDate(timestamp) |
2015-11-17 |
toUnixTimestamp(timestamp) |
2015-11-17 08:21:04+0000 |
toTimestamp(date) |
1447748464728 |
toUnixTimestamp(date) |
2015-11-17 08:21:04+0000 |
Finally you’re still using an old client driver version, it is recommended that you update to the latest version as soon as possible, as the native protocol versions 1 and 2 are marked @Depreciated in 2.2 and will be removed in 3.0.
4. Off heap memtables
We commonly observe latency spikes in clusters due to either compactions or garbage collection, usually occurring when the cluster is approaching capacity and has little headroom for these maintenance tasks.
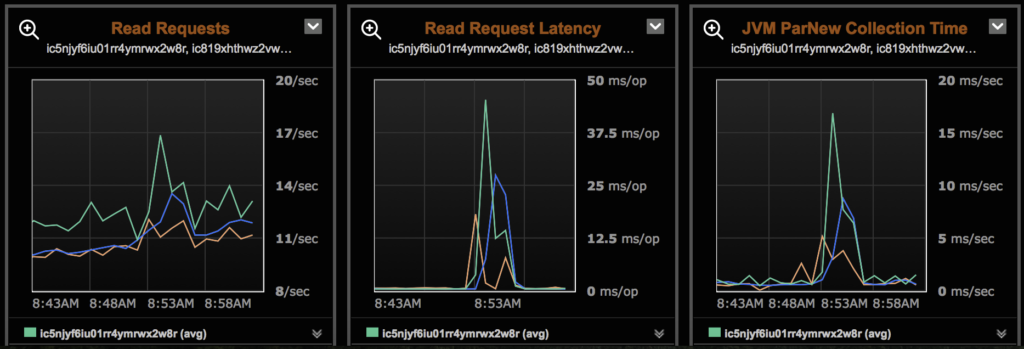
Off heap memtables have been a feature since 2.1 and becomes the default from 2.2 onwards.
Moving the memtable off-heap means that almost all Cassandra data structures are now off-heap, and is good for two reasons. Firstly, we expect that the GC pauses and resultant latency spikes we’ve been observing should cease as there is more heap available for other internal operations.
Secondly, the memtable size is no longer limited by the JVM heap size. A larger memtable allows for both less frequent flushes and larger SSTables, and in turn less compactions.
5. Concurrent repairs, now with logging!
At Instaclustr we run repairs across our clusters once per week, which is the recommended best practice. The engineering team have invested significant effort in automating and tracking this process across the hundreds of nodes we have under management.
Repair is necessary but can be slow. It’s not uncommon for us to see repairs of large clusters take days to complete. A major refactoring of org.apache.cassandra.repair in 2.2 makes some great improvements, most nobably that repairs now run in parallel (with a configurable number of threads, up to a maximum of 4). Previously repair tasks ran in a single, sequential thread. Our initial deployment will continue to use single threaded, but we will undertake some testing and benchmarking to determine the optimal number of threads for parallel repairs without negatively impacting the cluster performance.
Finally, one of the new features I’m keen to explore and take advantage of is the new keyspace system_distributed which tracks repair operations.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE system_distributed.repair_history ( keyspace_name text, columnfamily_name text, id timeuuid, coordinator inet, exception_message text, exception_stacktrace text, finished_at timestamp, parent_id timeuuid, participants set<inet>, range_begin text, range_end text, started_at timestamp, status text, PRIMARY KEY ((keyspace_name, columnfamily_name), id) ) |
I hope this has been a useful overview of some of the new features in the latest version of Cassandra. If you’re keen to give 2.2 a try, we’ve rolled it out in Beta to all our plans as of today so head over to our console and spin up a free trial cluster. Existing users can contact support if you want to have your existing cluster upgraded.
What do you think? Have you tried 2.2 yet? We’d love to hear your thoughts and experiences, so leave us a message in the comments below or hit us up on twitter.
About the author
Brooke Jensen is a Senior Software Engineer working on our provisioning, monitoring and operational applications, as well as providing second level support for customer clusters. Brooke also provides consulting services conducting operational and data model reviews of Cassandra clusters. Brooke has over 11 years of Software Engineering experience with a background in application performance tuning, data analysis, capacity and scalability of enterprise applications, and application development.