Apache Cassandra is an open source non-relational, or NoSQL, distributed database that enables continuous availability, tremendous scale, and data distribution across multiple data centers and cloud availability zones. Simply put, it provides a highly reliable data storage engine for applications requiring immense scale.
Data modeling is a process used to analyze, organize, and understand the data requirements for a product or service. Data modeling creates the structure your data will live in. It defines how things are labeled and organized, and determines how your data can and will be used. The process of data modeling is similar to designing a house. You start with a conceptual model and add detail to produce the final blueprint.
The ultimate goal of Cassandra data modeling and analysis is to develop a complete, well organized, and high performance Cassandra cluster. Following the five Cassandra data modeling best practices outlined will hopefully help you meet that goal:
Five Best Practices for Using Apache Cassandra
- Don’t try to use Cassandra like a relational database
- Design your model around 3 data distribution goals
- Understand the importance of the Primary Key in your data structure
- Model around your queries
- Conduct testing to ensure the performance of your mode.
Cassandra Is Not a Relational Database
Do not try to design a Cassandra data model like you would with a relational database.
Query first design: You must define how you plan to access the data tables at the beginning of the data modeling process not towards the end.
No joins or derived tables: Tables cannot be joined so if you need data from more than one table, the tables must be merged into a denormalized table.
Denormalization: Cassandra does not support joins or derived tables so denormalization is a key practice in Cassandra table design.
Designing for optimal storage: For relational databases this is usually transparent to the designer. With Cassandra, an important goal of the design is to optimize how data is distributed around the cluster.
Sorting is a Design Decision: In Cassandra, sorting can be done only on the clustering columns specified in the PRIMARY KEY.
The Fundamental Goals of the Cassandra Data Model
Distributed data systems, such as Cassandra, distribute incoming data into chunks called partitions. Cassandra groups data into distinct partitions by hashing a data attribute called partition key and distributes these partitions among the nodes in the cluster.
(A detailed explanation can be found in Cassandra Data Partitioning.)
A good Cassandra data model is one that:
- Distributes data evenly across the nodes in the cluster
- Place limits on the size of a partition
- Minimizes the number of partitions returned by a query.
Distributes Data Evenly Around the Cassandra Cluster
Choose a partition key that has a high cardinality to avoid hot spots—a situation where some nodes are under heavy load while others are idle. Limits the Size of Partitions For performance reasons, choose partition keys whose number of possible values is bounded. For optimal performance, keep the size of a partition between 10 and 100MB.Minimize the Number of Partitions Read by a Single Query
Ideally, each of your queries will read a single partition. Reading many partitions with a single query is expensive because each partition may reside on a different node. The coordinator (this is the node in the cluster that first receives the request) will generally need to issue separate commands to separate nodes for each partition you request. This adds overhead and increases the variation in latency. Unless the data set is small, attempting to read an entire table, that is all the partitions, fails due to a read timeout.Understand the Importance of the Primary Key
Every table in Cassandra must have a set of columns called the primary key. (In older versions of Cassandra, tables were called column families). In addition to determining the uniqueness of a row, the primary key also shapes the data structure of a table. The Cassandra primary key has two parts: Partition key: The first column or set of columns in the primary key. This is required. The hashed value of the partition key value determines where the partition will reside within the cluster. Clustering key (aka clustering columns):Are the columns after the partition key. The clustering key is optional. The clustering key determines the default sort order of rows within a partition. A very important part of the design process is to make sure a partition key will:- Distribute data evenly across all nodes in a cluster. Avoid using keys that have a very small domain of possible values, such as gender, status, school grades, and the like. The minimum number of possible values should always be greater than the number of nodes in the cluster. Also, avoid using keys where the distribution of possible values is highly skewed. Using such a key will create “hotspots” on the cluster.
- Have a bounded range of values. Large partitions can increase read latency and cause stress on a node during a background process called compaction. Try to keep the size of partitions under 100MB.
Model Around Your Queries
The Cassandra Query Language (CQL) is the primary language used to communicate with a Cassandra database. In syntax and function, CQL resembles SQL which makes it easy for those who know the latter to quickly learn how to write queries for Cassandra. But there are some important differences that affect your design choices. A well known one is that Cassandra does not support joins or derived tables. Whenever you require data from two or more tables, you must denormalize. Search conditions have restrictions that also impact the design.- Only primary key columns can be used as query predicates. (Note: a predicate is an operation on expressions that evaluates to TRUE or FALSE).
- Partition key columns are limited to equality searches. Range searches can only be done on clustering columns.
- If there are multiple partition key columns (i.e. a composite partition key), all partition columns must be included in the search condition.
- Not all clustering columns need to be included in the search condition. But there are some restrictions:
- When omitting columns you must start with the rightmost column listed in the primary key definition;
- An equality search cannot follow a range search.
Don’t Forget About the Data
Creating a complete Cassandra data model involves more than knowing your queries. You can identify all the queries correctly but if you miss some data, your model will not be complete. Attempting to refactor a mature Cassandra database can be an arduous task. Developing a good conceptual model (see below) will help identify the data your application needs.Take a Structured Approach to Design
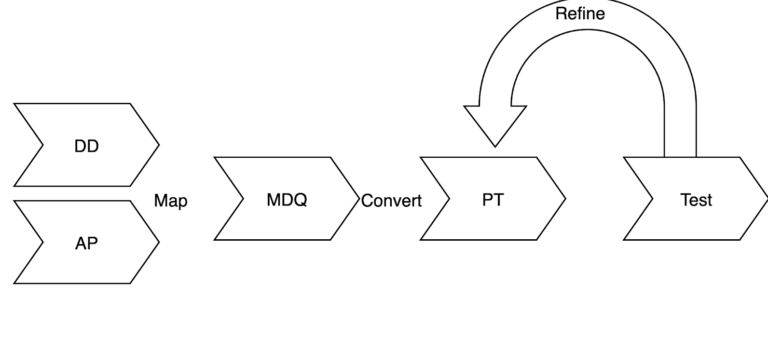
In order to create a data model that is complete and high performing, it helps to follow a big data modeling methodology for Apache Cassandra that can be summarized as:- Data Discovery (DD). This is a high level view of the data your application needs and identifies the entities (things), the attributes of the entities, and which attributes are the identifiers. This may be an iterative process.
- Identify the Access Patterns (AP). Identify and list the queries your application will want to perform. You need to answer the following questions: What data needs to be retrieved together, what are the search criteria, and what are the update patterns? This also may be an iterative process.
- Map data and queries (MDQ). Maps the queries to the data identified in steps 1 and 2 to create logical tables which are high level representations of Cassandra tables.
- Create the physical tables (PT). Convert the logical data model to a physical data model (PDM) by using CQL CREATE TABLE statements.
- Review and Refine physical data model. Confirm that the physical tables will meet the 3 Basic Goals for Cassandra Data Model.
LogSource and LogMessage. For LogSource the key attribute is sourceName. For the entity LogMessage, the key attribute is messageID.
The query we want to execute is: Q1) show the message information about the 10 most recent messages for a given source.
The primary access entity is LogSource because it contains the equality search attribute (sourceName). We create a logical table named LogMessage_by_Source and push the attribute sourceName into it. That becomes the partition key (indicated by the K).
We need to sort by time so messageTime becomes the clustering column in LogMessage_by_Source. (Indicated by C↑)
The secondary entity is LogMessage. The key attribute messageID becomes a 2nd clustering column of the primary key in LogMessage_By_Source to ensure uniqueness of the row. Finally, we add the remaining columns from the secondary source to complete the data needed by the query.
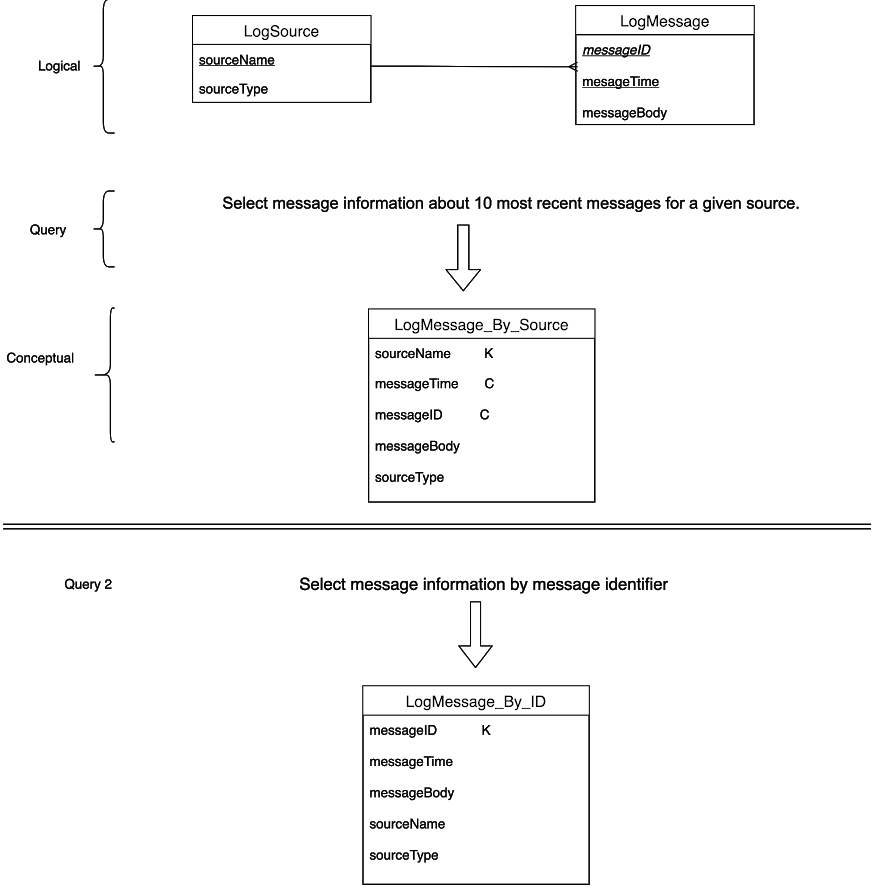
Data Duplication
Data duplication refers to the number of times data must be duplicated in different tables to satisfy access patterns. For example, if we wanted to search for a specific message by its unique identifier we would duplicate the data by creating a new table calledLogMessage_by_ID that uses messageID as the partition key.
Two issues can arise from duplication:
- Increased complexity to maintain data integrity across multiple tables;
- If the data being duplicated is very large it puts size and write pressure on the database.