MongoDB and Apache Cassandra are both popular NoSQL distributed database systems. In this article, I will review how the CAP and PACELC theorems classify these systems. I will then show how both systems can be configured to deviate from their classifications in production environments.
The CAP Theorem
The CAP theorem states that a distributed system can provide only two of three desired properties: consistency, availability, and partition tolerance.
Consistency (C): Every client sees the same data. Every read receives the data from the most recent write.
Availability (A): Every request gets a non-error response, but the response may not contain the most recent data.
Partition Tolerance (P): The system continues to operate despite one or more breaks in inter-node communication caused by a network or node failure.
Because a distributed system must be partition tolerant, the only choices are deciding between availability and consistency. If part of a cluster becomes unavailable, a system will either:
- Safeguard data consistency by canceling the request even if it decreases the availability of the system. Such systems are called CP systems.
- Provide availability even though inconsistent data may be returned. These systems are AP distributed systems.
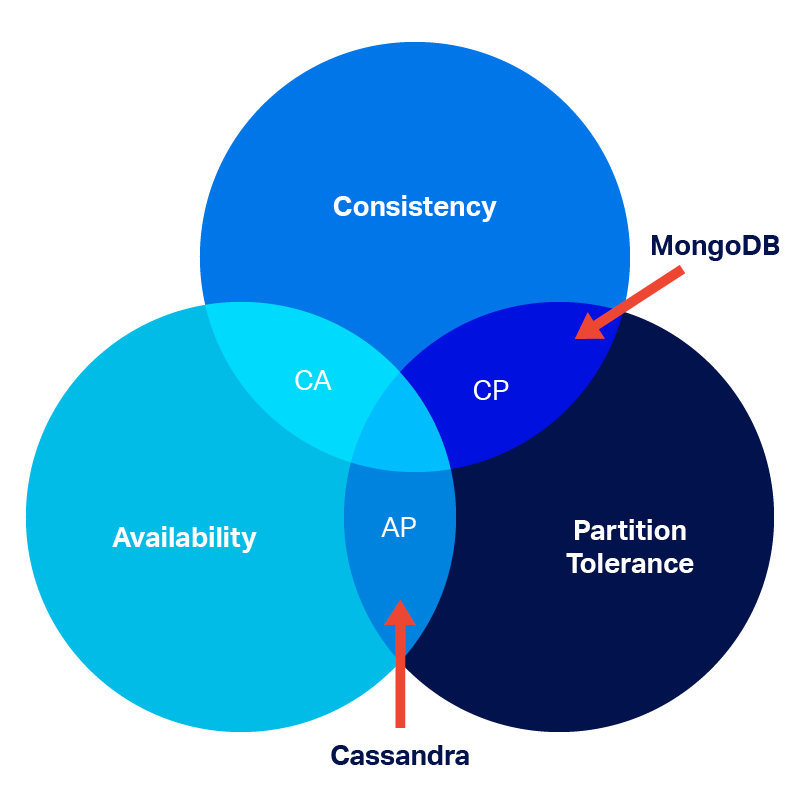
According to the CAP theorem, MongoDB is a CP system and Cassandra is an AP system.
CAP theorem provides an overly simplified view of today’s distributed systems such as MongoDB and Cassandra. Under normal operations, availability and consistency are adjustable and can be configured to meet specific requirements. However, in keeping with CAP, increasing one state decreases the other. Hence, it would be more correct to describe the default behavior of MongDB or Cassandra as CP or AP. This is discussed in more detail below.
PACELC Theorem
The PACELC theorem was proposed by Daniel J. Abadi in 2010 to address two major oversights of CAP:
- It considers the behavior of a distributed system only during a failure condition (the network partition)
- It fails to consider that in normal operations, there is always a tradeoff between consistency and latency
PACELC is summarized as follows: In the event of a partition failure, a distributed system must choose between Availability (A) and Consistency, else (E) when running normally it must choose between latency (L) or consistency (C).
MongoDB is classified as a PC+EC system. During normal operations and during partition failures, it emphasizes consistency. Cassandra is a PA+EL system. During a partition failure it favors availability. Under normal operations, Cassandra gives up consistency for lower latency. However, like CAP, PACELC describes a default behavior
(As an aside, there are no distributed systems that are AC or PC+EC. These categories describe stand-alone ACID-compliant relational database management systems).
Apache Cassandra vs. MongoDB Architectures
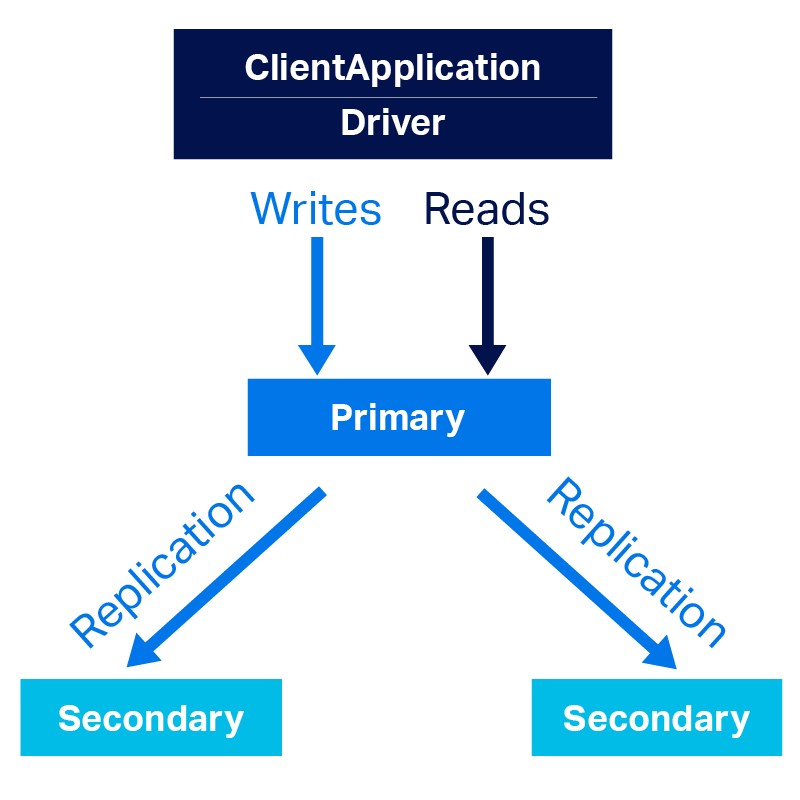
MongoDB is a NoSQL document database. It is a single-master distributed system that uses asynchronous replication to distribute multiple copies of the data for high availability. A MongoDB is a group of instances running mongod and maintaining the same data. The MongoDB documentation refers to this grouping as a replica set. But, for simplicity, I will use the MongoDB cluster.
A MongoDB cluster is composed of two types of data-bearing members:
Primary: The primary is the master node and receives all write operations.
Secondaries: The secondaries receive replicated data from the primary to maintain an identical data set.
By default, the primary member handles all reads and writes. Optionally, a MongoDB client can route some or all reads to the secondary members. Writes must be sent to the primary.
If the primary member fails, all writes are suspended until a new primary is selected from one of the secondary members. According to the MongoDB documentation, this process requires up to 12 seconds to complete.
To increase availability, a cluster can be distributed across geographically distinct data centers. The maximum size of a MongoDB replicaset is 50 members.
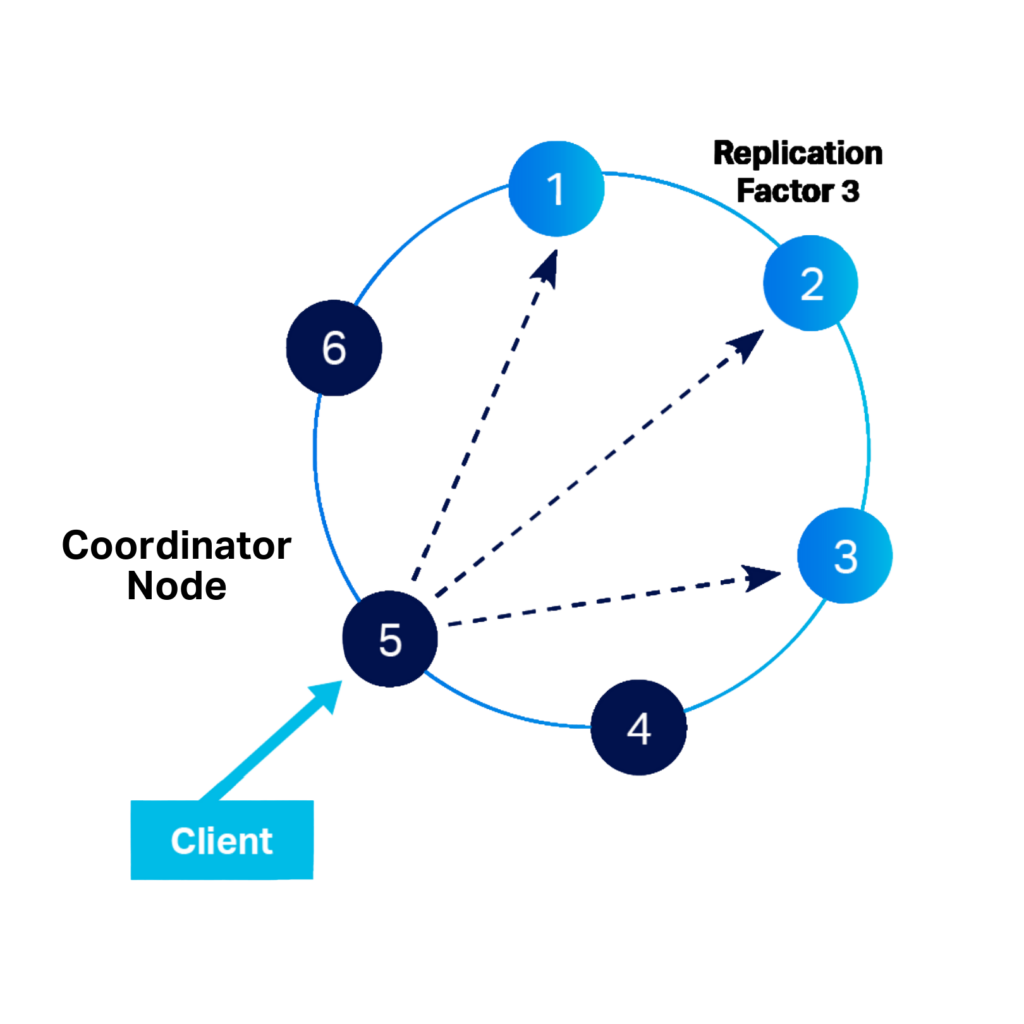
A Cassandra cluster is a collection of instances, called nodes, connected in a peer-to-peer “share nothing” distributed architecture. There is no master node and every node can perform all database operations and each can serve client requests. Data is partitioned across nodes based on a consistent hash of its partitioning key. A partition has one or many rows and each node may have one or more partitions. However, a partition can reside only on one node.
Data has a replication factor that determines the number of copies (replicas) that should be made. The replicas are automatically stored on different nodes.
The node that first receives a request from a client is the coordinator. It is the job of the coordinator to forward the request to the nodes holding the data for that request and to send the results back to the coordinator. Any node in the cluster can act as a coordinator.
Consistency
By default, MongoDB is a strongly consistent system. Once a write completes, any subsequent read will return the most recent value. Cassandra, by default, is an eventually consistent system. Once a write completes, the latest data eventually becomes available provided no subsequent changes are made. It is important to keep in mind that MongoDB becomes an eventually consistent system when read operations are done on the secondary members. This happens because of replication lag (the delay between when the data is written to the primary and when that data is available on the secondary). The larger the lag, the greater chance that reads will return inconsistent data.Tunable Consistency
Both MongoDB and Cassandra have “tunable consistency.” That is, the levels of consistency and availability are adjustable to meet certain requirements. Individual read and write operations define the number of members or replicas that must acknowledge a request in order for that request to succeed. In MongoDB, this level is called read concern or write concern. In Cassandra, the level of acknowledgment is the consistency level of the operation. The definitions of each are shown in Tables 1 and 2.| Read Concern | Description |
| Local | Returns data from the instance without guaranteeing the data has been written to a majority of the instances. This is equivalent to a read uncommitted isolation in a relational database. |
| Available | Same as local. |
| Majority | Guarantees that a majority of the cluster members acknowledged the request. A majority read returns only committed data. |
| Write Concern | Description |
| 0 | Does not require an acknowledgment of the write. |
| 1 | Requires acknowledgment from the primary member only. |
| <number> | Checks if the operation has replicated to the specified number of instances. |
| Majority | Checks if the operations have propagated to the majority. |
| Consistency Level | Description |
| ONE, TWO, THREE | How many replicas need to respond to a read or write request. |
| LOCAL_ONE | One replica in the same data center as the coordinator must successfully respond to the read or write request. Provides low latency at the expense of consistency |
| LOCAL_QUORUM | A quorum (majority) of the replica nodes in the same data center as the coordinator must respond to the read or write request. Avoids latency of inter-data-center communication. |
| QUORUM | A quorum (majority) of the replicas in the cluster need to respond to a read or write request for it to succeed. Used to maintain strong consistency across the entire cluster. |
| EACH_QUORUM | The read or write must succeed on a quorum of replica nodes in each data center. Used only for writes to a multi-data-center cluster to maintain the same level of consistency across data centers. |
| ALL | The request must succeed on all replicas. Provides the highest consistency and the lowest availability of any other level. |
| ANY | A write must succeed on at least one node or, if all replicas are down, a hinted handoff has been written. Guarantees that a write will never fail at the expense of having the lowest consistency. Delivers the lowest consistency and highest availability. |
| Optimization | Read Consistency | Write Consistency |
| Write | ALL | ONE |
| Read | ONE | ALL |
| Balance | QUORUM | QUORUM |
| None: High Latency With Low Availability | ALL | ALL |
Losing Consistency During Normal Operations
Replicating multiple copies of data is how Cassandra and MongoDB increase availability. Data in these copies can become inconsistent during normal operations. However, as we shall see, Cassandra has background processes to resolve these inconsistencies. When MongoDB secondary members become inconsistent with the primary due to replication lag, the only solution is waiting for the secondaries to catch up. MongoDB 4.2 can throttle replication whenever the lag exceeds a configurable threshold. However, if the data in the secondaries becomes too stale, the only solution is to manually synchronize the member by bootstrapping the member after deleting all data, by copying a recent data directory from another member in the clusteror, or by restoring a snapshot backup. Cassandra has two background processes to synchronize inconsistent data across replicas without the need for bootstrapping or restoring data: read repairs and hints. If Cassandra detects that replicas return inconsistent data to a read request, a background process called read repair imposes consistency by selecting the last written data to return to the client. If a Cassandra node goes offline, the coordinator attempting to write the unavailable replica temporarily stores the failed writes as hints on their local filesystem. If hints have not expired (three hours by default), they are written to the replica when it comes back online, a process known as hinted handoffs. Anti-entropy repairs (a.k.a. repairs) is a manual process to synchronize data among the replicas. Running repairs is part of the routine maintenance for a Cassandra cluster.Loss of Consistency During a Failure
If the primary member fails, MongoDB preserves consistency by suspending writes until a new primary is elected. Any writes to the failed primary that have not been replicated are rolled back when it returns to the cluster as a secondary. Later versions of MongoDB (4.0 and later) also create rollback files during rollbacks. When a Cassandra node becomes unavailable, processing continues and failed writes are temporarily saved as hints on the coordinator. If the hints have not expired, they are applied to the node when it becomes available.Availability
Both MongoDB and Cassandra get high availability by replicating multiple copies of the data. The more copies, the higher the availability. Clusters can be distributed across geographically distinct data centers to further enhance availability. The maximum size MongoDB cluster is 50 members with no more than seven voting members. There is no hard limit to the number of nodes in a Cassandra cluster, but there can be performance and storage penalties for setting the replication factor too high. A typical replication factor is three for most clusters or five when there are very high availability requirements. Conversely, when data availability is less critical, say with data that can easily be recreated, the replication factor can be lowered to save space and to improve performance.Fault Tolerance
If the primary member of a MongoDB cluster becomes unavailable for longer than electionTimeoutMillis (10 seconds by default), the secondary members hold an election to determine a new primary as long as a majority of members are reachable. During the election, which can take up to 12 seconds, a MongoDB cluster is only partially available:- No writes are allowed until a new primary is elected
- Data can be read from the secondary if a majority of the secondary members are online and reads from the secondary members have been enabled
Fault Tolerance With Multiple Data Centers
Both MongoDB and Cassandra clusters can span geographically distinct data centers in order to increase high availability. If one data center fails, the application can rely on the survivors to continue operations. How MongoDB responds to the loss of a data center depends upon the number and placement of the members among the data centers. Availability will be lost if the data center containing the primary server is lost until a new primary replica is elected. The data can still be available for reads if it is distributed over multiple data centers even if one of the data centers fails. If the data center with a minority of the members goes down, the cluster can serve read and write operations; if the data center with the majority goes down, it can only perform read operations. With three data centers, if any data center goes down, the cluster remains writeable as the remaining members can hold an election. The fault tolerance of a Cassandra cluster depends on the number of data centers, the replication factor, and how much consistency you are willing to sacrifice. As long as the consistency level can be met, operations can continue.| Number of Failed Nodes Without Compromising High Availability | ||||
| RF 1 | Consistency Level | 1 DC | 2 DC | 3 DC |
| 2 | ONE/LOCAL_ONE | 1 node | 3 nodes total | 5 nodes total |
| 2 | LOCAL_QUORUM | 0 nodes | 0 nodes | 0 nodes |
| 2 | QUORUM | 0 nodes | 1 node total | 2 nodes total |
| 2 | EACH_QUORUM | 0 nodes | 0 nodes | 0 nodes |
| 3 | LOCAL_ONE | 2 nodes | 2 nodes from each DC | 2 nodes from each DC |
| 3 | ONE | 2 nodes | 5 nodes total | 8 nodes total |
| 3 | LOCAL_QUORUM | 1 node | 2 nodes total | 1 node from each DC or 2 nodes total |
| 3 | QUORUM | 1 node | 2 nodes total | 4 nodes total |
| 3 | EACH_QUORUM | 2 nodes | 1 node each DC | 1 node each DC |
| 5 | ONE | 4 nodes | 9 nodes | 14 nodes |
| 5 | LOCAL_ONE | 4 nodes | 4 nodes from each DC | 4 nodes from each DC |
| 5 | LOCAL_QUORUM | 2 nodes | 2 nodes from each DC | 2 nodes from each DC |
| 5 | QUORUM | 2 nodes | 4 nodes total | 7 nodes total |
| 5 | LOCAL_QUORUM | 2 nodes | Could survive loss of a DC | Could survive loss of 2 DCs |
| 5 | EACH_QUORUM | 2 nodes from each | 2 nodes from each | 2 nodes from each |
Conclusions on Cassandra vs. MongoDB
With the CAP or PACELC theorems, MongoDB is categorized as a distributed system that guarantees consistency over availability while Cassandra is classified as a system that favors availability. However, these classifications only describe the default behavior of both systems. MongoDB remains strongly consistent only as long as all reads are directed to the primary member. Even when reads are limited to the primary member, consistency can be loosened by read and write concerns. Cassandra can also be made strongly consistent through adjustments in consistency levels as long as a loss of availability and increased latency is acceptable. Want to learn more about how to identify the best technology for your data layer? Contact us to schedule a time with our experts.Instaclustr managed Cassandra service streamlines deployment. Get in touch to discuss our managed Cassandra service for your application.