Running a fleet of Redis™ clusters for Instaclustr at scale comes with many challenges; keeping clusters up to date being just one example.
We do not want to log on to each node in a cluster and update it manually. Automated processes do things like apply security patches and update versions, but making sure these automated systems run in a way that allows the least amount of interruption possible to our clusters has its own challenges.
We cannot hit all the nodes at once and ask them to update without putting too much load on clusters or bringing replicas down at the same time as master nodes. This would cause downtime for our customers which is something we strive to avoid.
So over time we worked out the safest way to perform updates on Redis clusters while meeting the goals of stability and security.
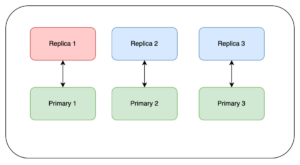
In this blog, we assume that we are performing updates to a 6-node cluster with 3 primary nodes and 3 replica nodes. In Redis, each replica is an exact copy of 1 primary. This means that in the diagrams below if we were to take down Primary 1 and Replica 1 at the same time, one-third of the data would be inaccessible. (The diagram below represents this scenario, with green being a primary node and blue being a replica).
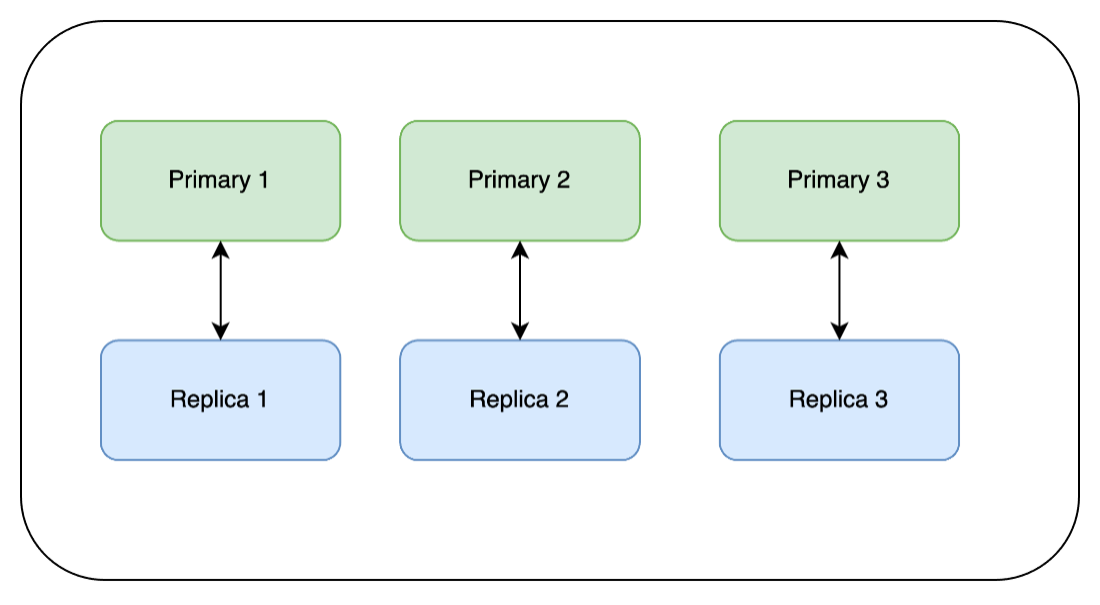
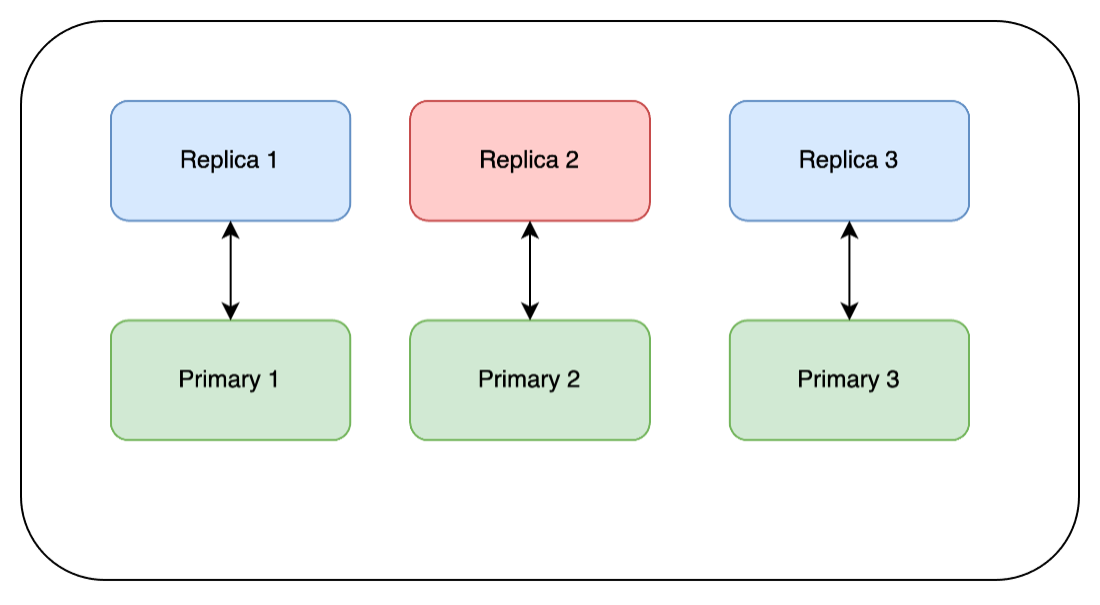
The first thing we do is update the replicas. In Redis, the default is that replicas do not accept writes. However, depending on how your client is set up, it may be reading from both the primary and the replica. In this case there will be some spikes and some stale data read depending on your set up. In the diagram below, red represents the node that is being updated and whose health we wait to come back before moving on to the next node:
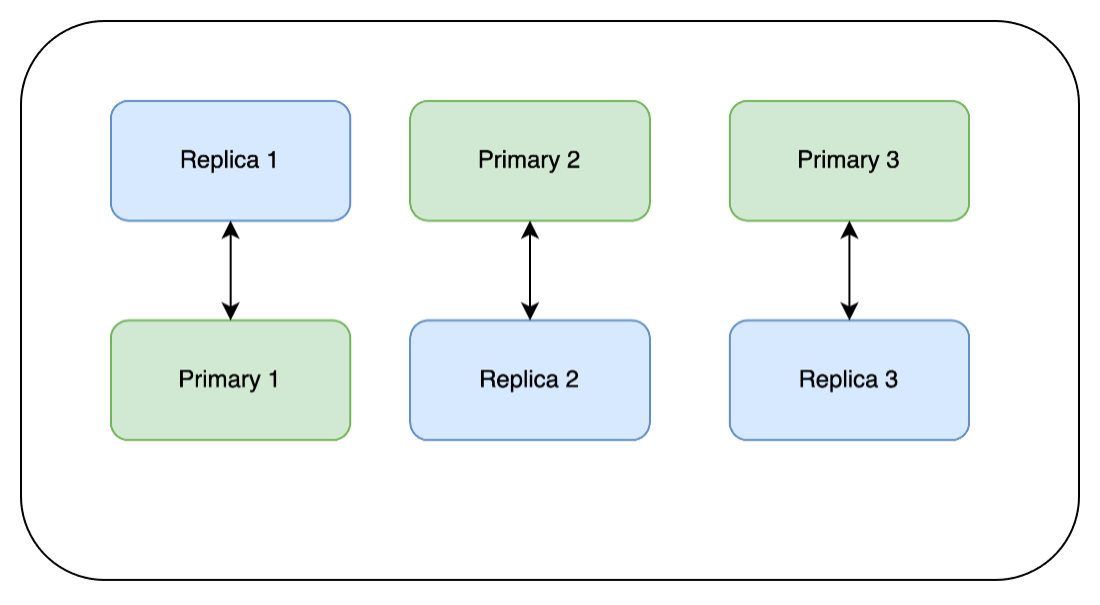
Next, we run the update on Replica 1 and wait for it to complete. Then we wait for it to finish synchronizing with its primary node and for its health to return to green.
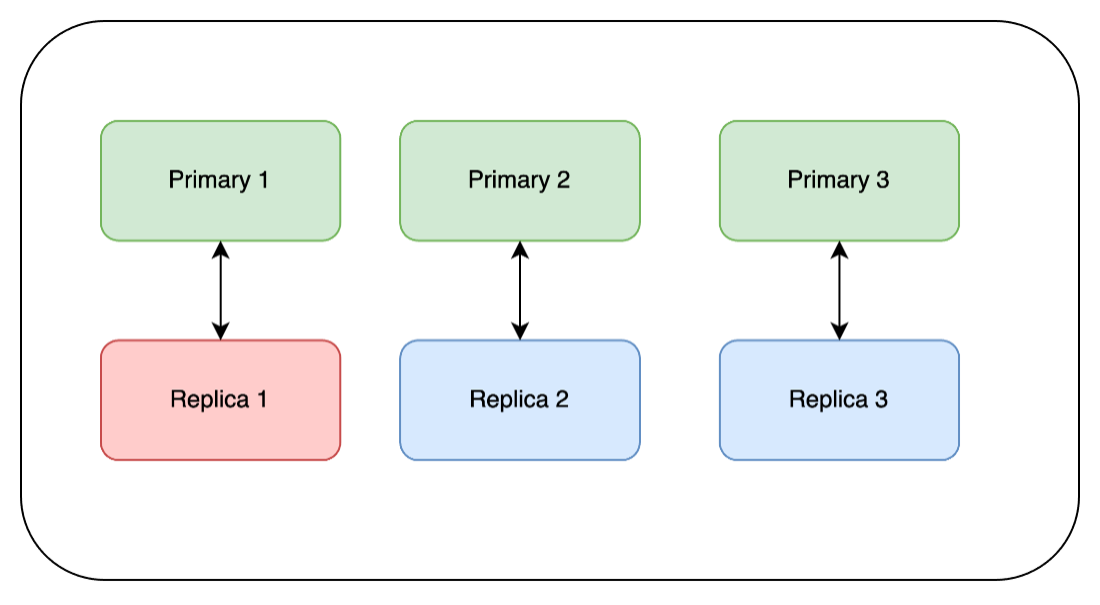
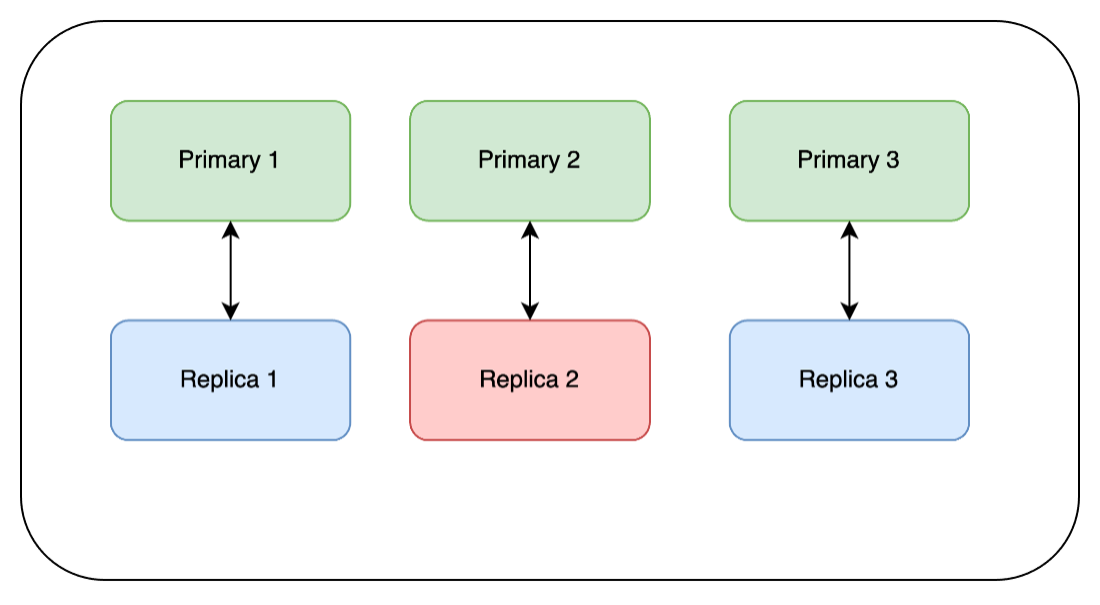
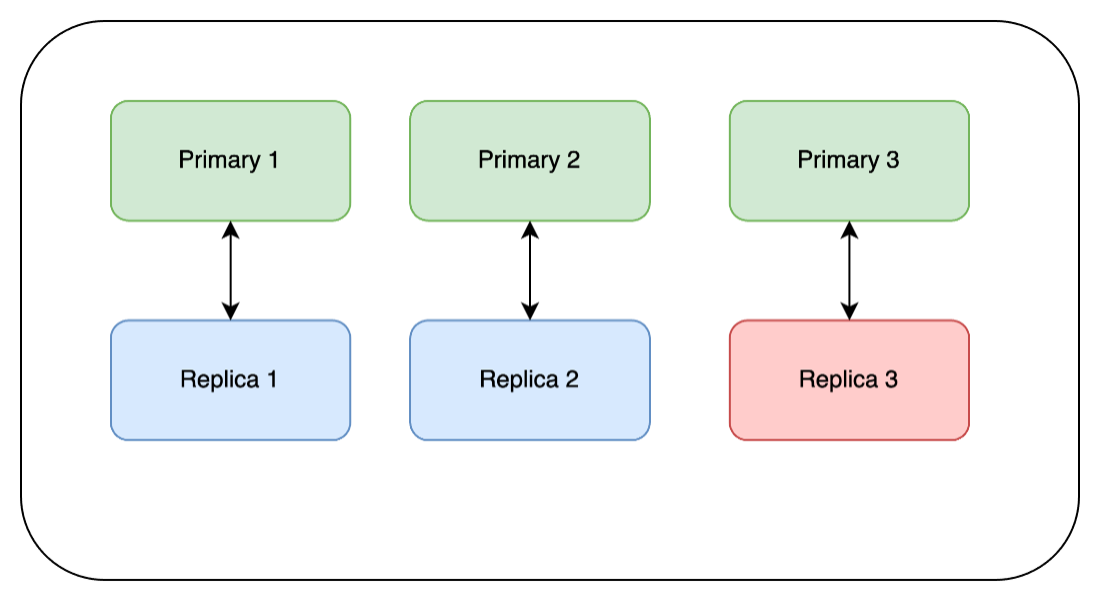
We then repeat the same steps on Replica 2 and Replica 3:
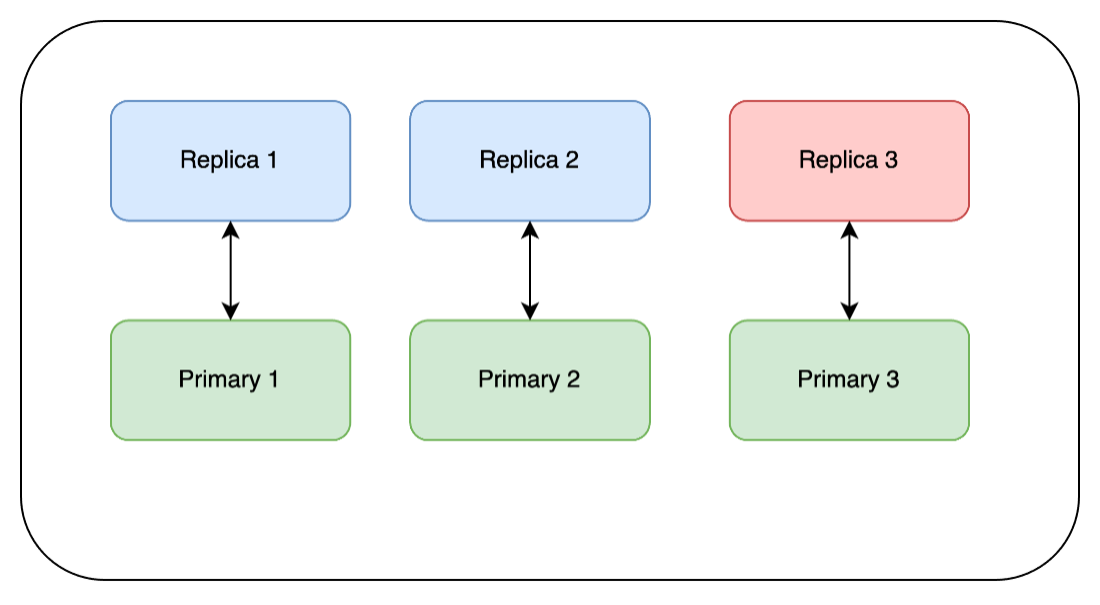
As mentioned above, Redis does not accept writes to the replica nodes, so we need to failover our replicas to become the new primaries because they already have the patch applied. We force a failover and then wait for the health to come back before moving on to the next one.
Note: Redis clients are set up to handle changes in Redis’ topology like this. Redis clustering is configured so that if Primary 1 were to fail, Replica 1 would then become Primary 1. Forcing a failover is similar, except that we are monitoring it even more closely:
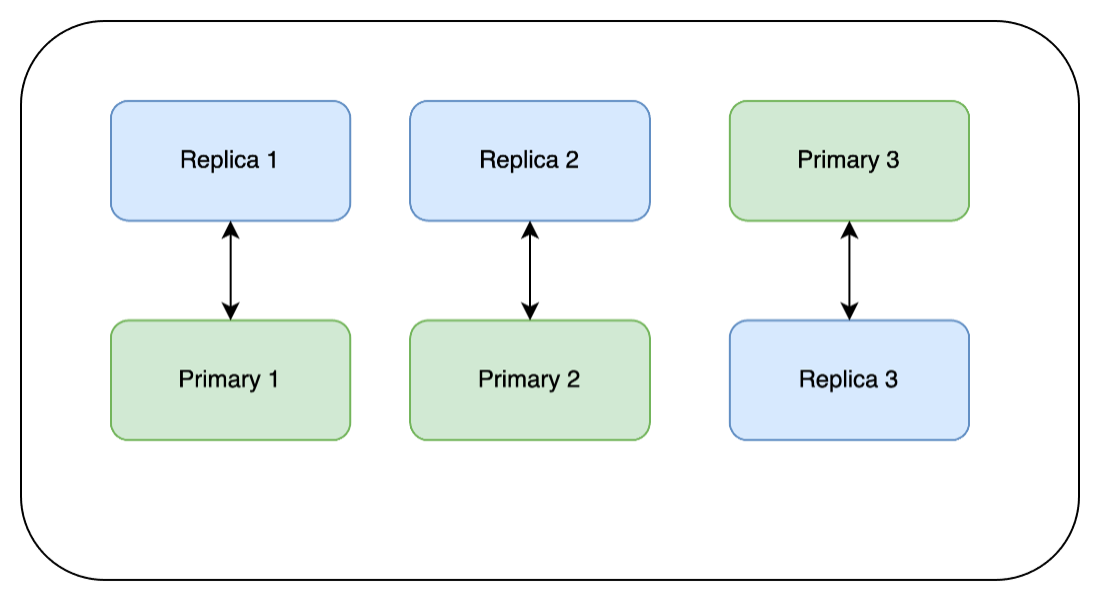
Now our cluster looks like the diagram below, still serving both reads and writes:
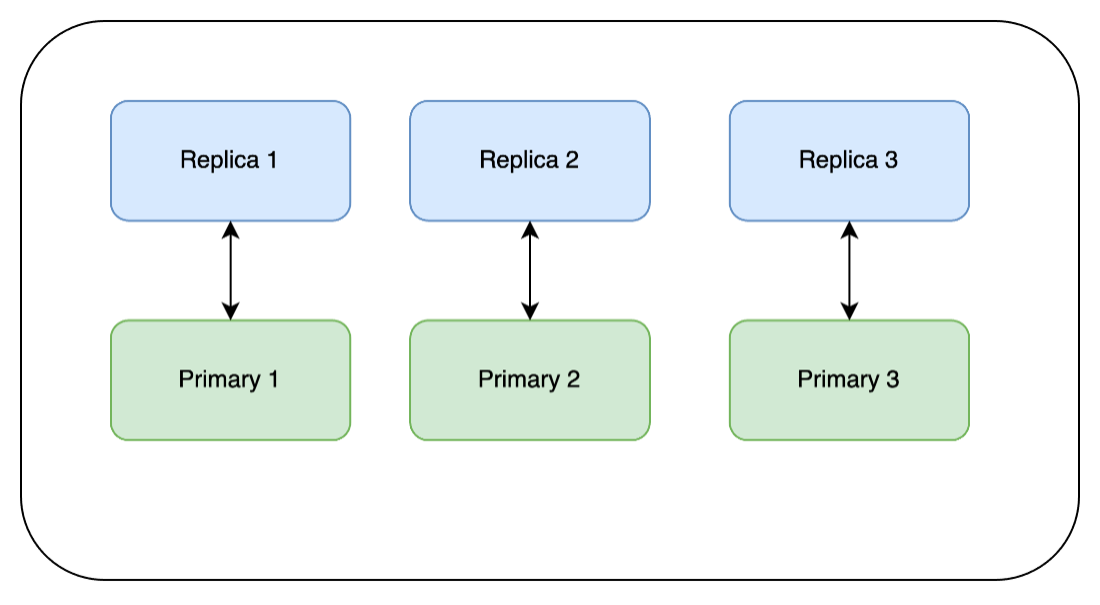
The replicas are now the primaries, so now we can update the replicas (former primaries) while the new primaries serve write requests without interruption. We follow the same pattern as before – update, wait for the health to go green, and continue:
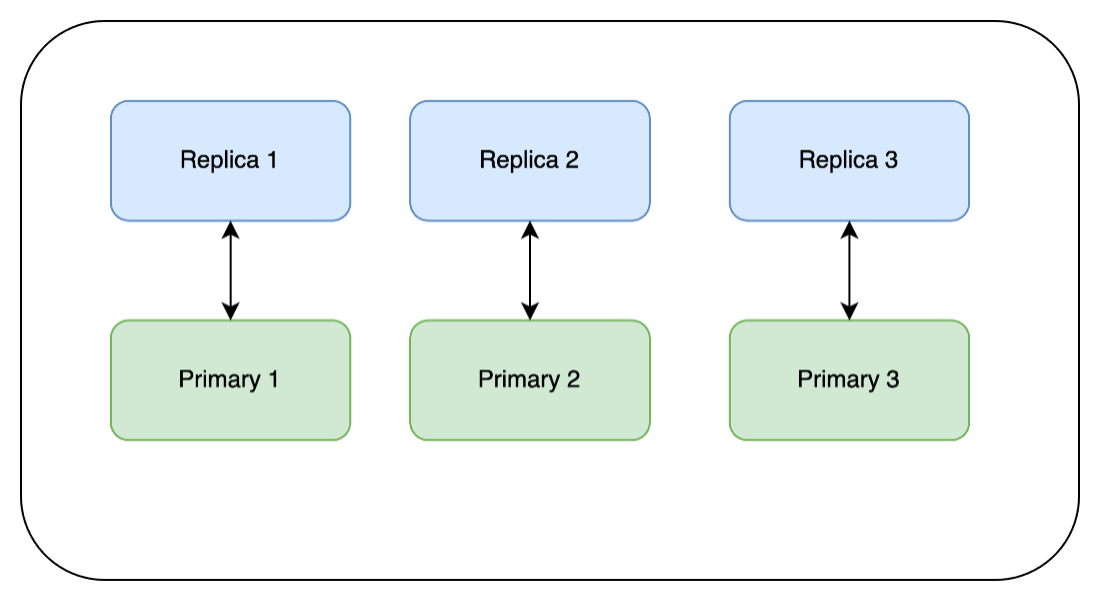
Once these updates are complete the cluster will look like the one below.
Here you have a choice: we can leave it with this topology, or we can revert all nodes back to their original state. This is a preference as to how you have your client set up, or your replicas/primaries configured within the cloud.
What Next?
We have worked hard to make sure that we do not have downtime while performing upgrades on our Redis clusters. However, we think there are improvements that can be made. Next up we are going to treat those primaries/replicas as shards as illustrated below:
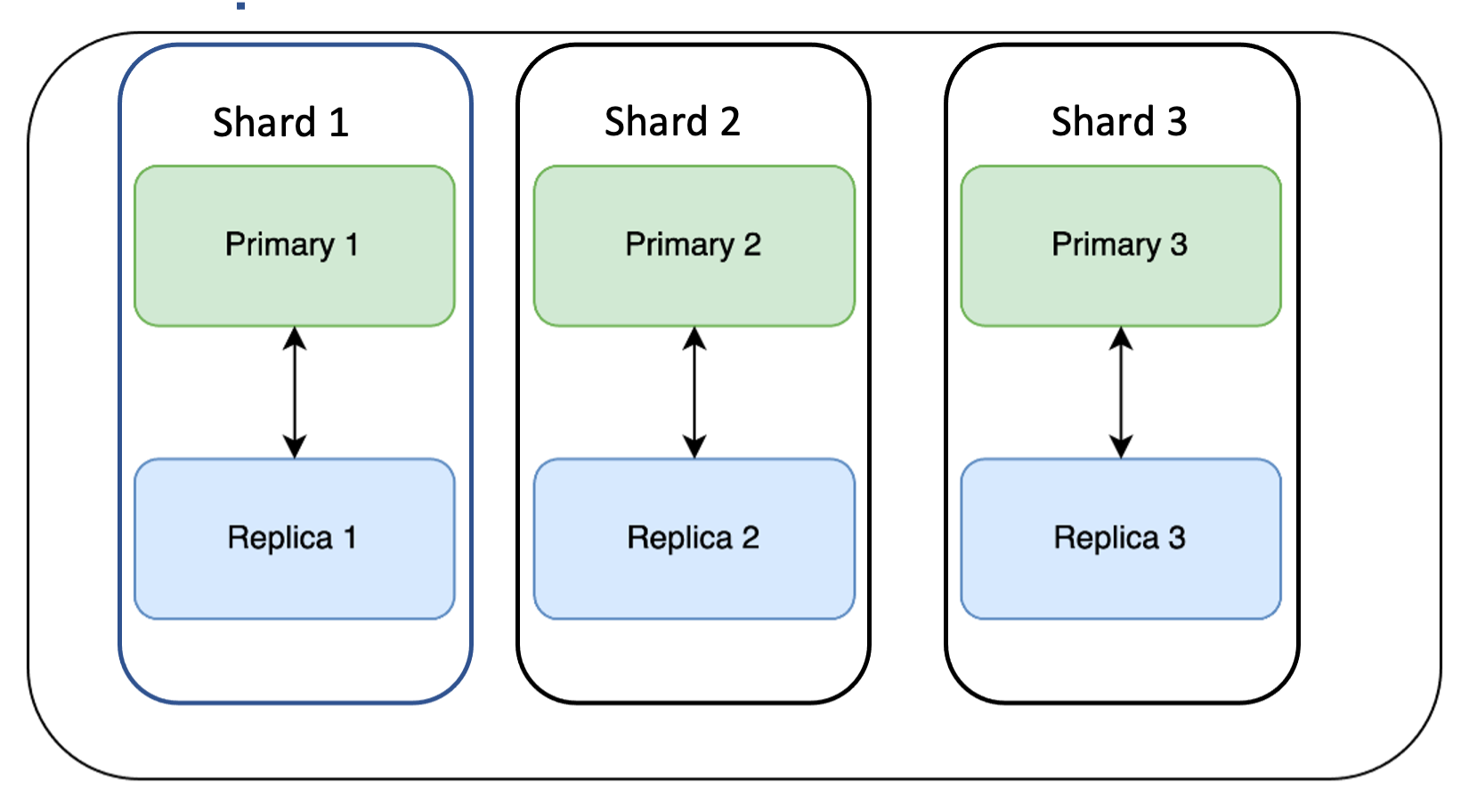
The update would then happen serially one shard at a time as follows:
- Upgrade 1 replica at a time (if there are multiple replicas for a primary)
- Failover to the last upgraded replica
- Upgrade the primary (which should now be a replica)
Some Things to Note About Our Solution
As mentioned above clients can be set to read from both replicas and primaries.
Shown in this example from Lettuce, the default is to read from the primary; however there can be reasons why you would want to read from both. If you are reading from replicas, then updating in this fashion will give you spikes in error responses when reading.
It is very possible to have a cluster set up with no replicas; depending on the use case that is ok.
However, it does mean when updates are performed on the cluster that there will be some impact to the primary nodes. Due to the impact on primary nodes when performing upgrades/updates Instaclustr recommends always having replica nodes.
Interested to see all the benefits of a Redis Managed Service? Reach out to our team and let’s chat about your use case!
Written by
Senior Software Engineer
Site Reliability Engineer