A Kafka performance model for SSDs/EBS, network, IO, and now—storage!
In my previous series on Apache Kafka® Tiered Storage, we explored how Kafka storage works, including the new Tiered Storage architecture which allows potentially more data to be stored in remote storage (e.g. AWS S3) for less money.
And in Part 3 specifically, we explored some of the space/time trade-offs with Kafka— an interesting point that’s worth digging around some more.
As we discovered already in this new series, records are initially written to local storage on the leader broker (SSD or EBS storage), where they are retained for the “local” retention time (retention.ms if Tiered Storage is not enabled, otherwise local.retention.ms).
If Kafka Tiered Storage is enabled for the cluster and topic then the records are also written to remote storage after a slight delay—(the segment must be closed first, and the write is asynchronous). The remote records/segments are retained for the “remote” retention time (retention.ms).
So, assuming you have a replication factor (RF) of 3 (typical in production) you will actually have 4+ copies of each record (apart from the active segment which only ever has 3) until local segments are deleted, after which the only copy is remote (which is replicated under the hood by AWS S3).
We can easily compute the local and remote data storage quantities using Little’s Law which predicts the population in a system from the throughput and time spent in the system on average:
Users = Throughput x Time
In my previous blog, we discovered that you could pack a certain number of boxes of cheese, rabbits, or eggs in an old-time ‘R’ (Refrigerator) train car. Let’s focus on eggs this time as egg production is easy to understand—it’s all about the chickens!

(Source: Adobe Stock)
Imagine you have a chicken farm with 10,000 chickens, each laying one egg on average every 26 hours. For this part of the system (chicken/eggs sub-system), we know the population of chickens and time to lay, so we can rearrange the formula to compute the egg laying throughput:
Eggs/hour = 10,000/26 = 385 (rounded up)
Let’s assume the eggs are packed and transported once a day, so we are interested in the number of eggs that need to be stored/processed per day (the egg/transportation sub-system), i.e. just throughput times time:
Eggs/day = 385 x 24 = 9240 eggs
Assuming one box of eggs has 30 eggs then you can compute the egg storage requirements as:
Boxes of eggs = 9240/30 = 308
Coincidentally an ‘R’ car could hold 330 boxes of eggs, so the train needs just under 1 ‘R’ car to transport your eggs to market every day (But maybe there should be a saying “Don’t put all your eggs in one railway carriage!”)
For Kafka data storage the equation is:
Data size (TB) = (retention period (s) x data throughput [GB/s])/1000
We can compute this for local and remote storage as follows:
Local data size (TB) = 3 x (local.retention.ms/1000 x producer data volume [GB/s])/1000
Remote data size (TB) = (remote.retention.ms/1000 x producer data volume [GB/s])/1000
Note: these calculations compute the approximate average (ignoring workload spikes) minimum storage space used (it may be more). Due to the way that retention works in Apache Kafka, slightly more space may be needed as once the retention period is reached deletions are typically asynchronous and potentially delayed.
Also note: this doesn’t allow for any storage headroom, and the capacity of the disk will need to be higher—you don’t want to suddenly use up your storage on a Kafka cluster (particularly for fixed sized SSDs—for EBS and S3 this isn’t such an issue).
And another thing: to compute storage sizes, it’s important to use accurate average workload metrics rather than peak metrics; this is one occasion in performance engineering when averages are good! (Why’s that? Normally averages are “wrong”, as they are not statistically robust; medians and percentiles are more robust).
From this we can compute the approximate minimum storage costs as $ TB/month, given the cloud providers’ pricing for different types of storage. For example, AWS EBS is around $0.08 GB/month, and AWS S3 is cheaper at $0.023 GB/month (x 1000 to get $ TB/month). Here are some limitations:
- The cost of SSDs depends on instance type and sizes so I will ignore these for the time being
- There may also be extra costs for data transfer but I’m just looking at storage costs for now
- And note that the storage costs are also simplified a bit (as typically prices depend on tiered quantities)
For the same retention period, more data is stored locally due to replication. And noting how Tiered Storage actually works (records are retained on local storage for local.retention.ms, and on remote storage for retention.ms), it really only makes sense for local.retention.ms << retention.ms.
After enabling Tiered Storage, you therefore have a couple of options:
(1) Retaining the original (local) retention period for the remote storage and reducing the local retention period, or
(2) Retaining the local retention period and increasing the remote retention period.
We can add this to our Kafka performance model (Excel and JavaScript versions) and see what some different scenarios reveal. The new inputs are local and remote retention times (s) and costs ($ GB/month), and it computes local and remote storage used (TB) and storage costs per month.
Let’s start with a simple example: assuming we have one day retention time for local storage to start with. Once Tiered Storage is enabled, let’s assume we have 1-day maximum retention still—for remote storage—but a shorter 1-hour local retention time.
That is, we still have the records available for the same period, but access to records within an hour of creation will be faster using local storage, but slower for records older than an hour.
Here’s a screen shot of the updated javascript calculator for the Tiered Storage option (kafka_storage.html on GitHub here):

The following chart shows the substantial (2.6x) reduction in storage with Tiered Storage enabled:

Unsurprisingly, there are potential cost savings (7x):
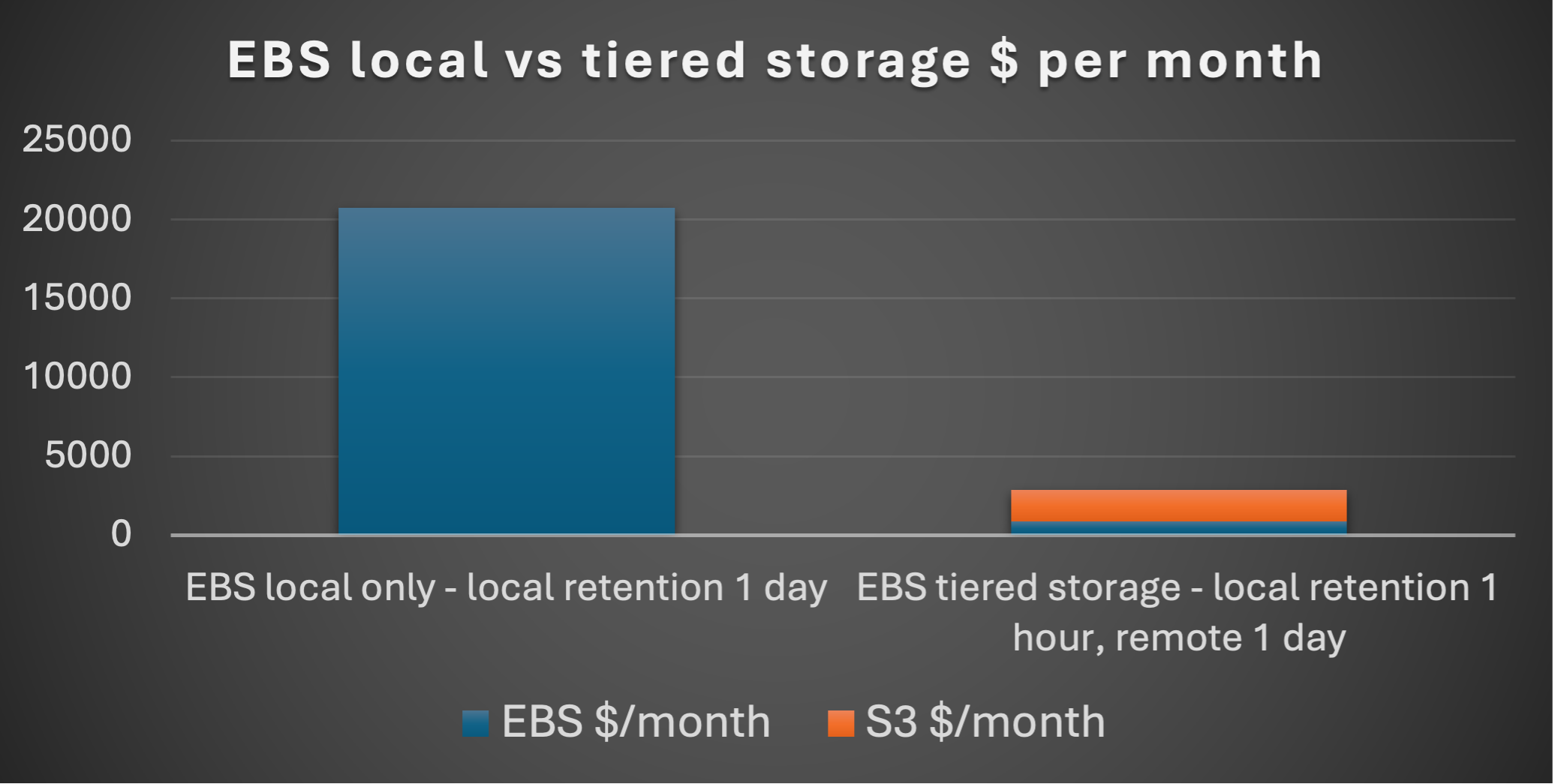
As mentioned above, in addition to offering the possibility of reduced local storage space (and therefore reduced cost), another scenario is to increase the amount and age of the available for replaying.
For example, let’s see what happens if we retain the 1 hour local retention, but increase the remote retention to 1 month.
Here’s the total storage comparison (the local storage amount of 10.8 TB for the Tiered Storage scenario is swamped by the remote storage amount of 2,592 TB):

Increasing the remote retention time means a lot more data must be stored, but the majority of it is on cheaper S3 storage as this cost comparison reveals:
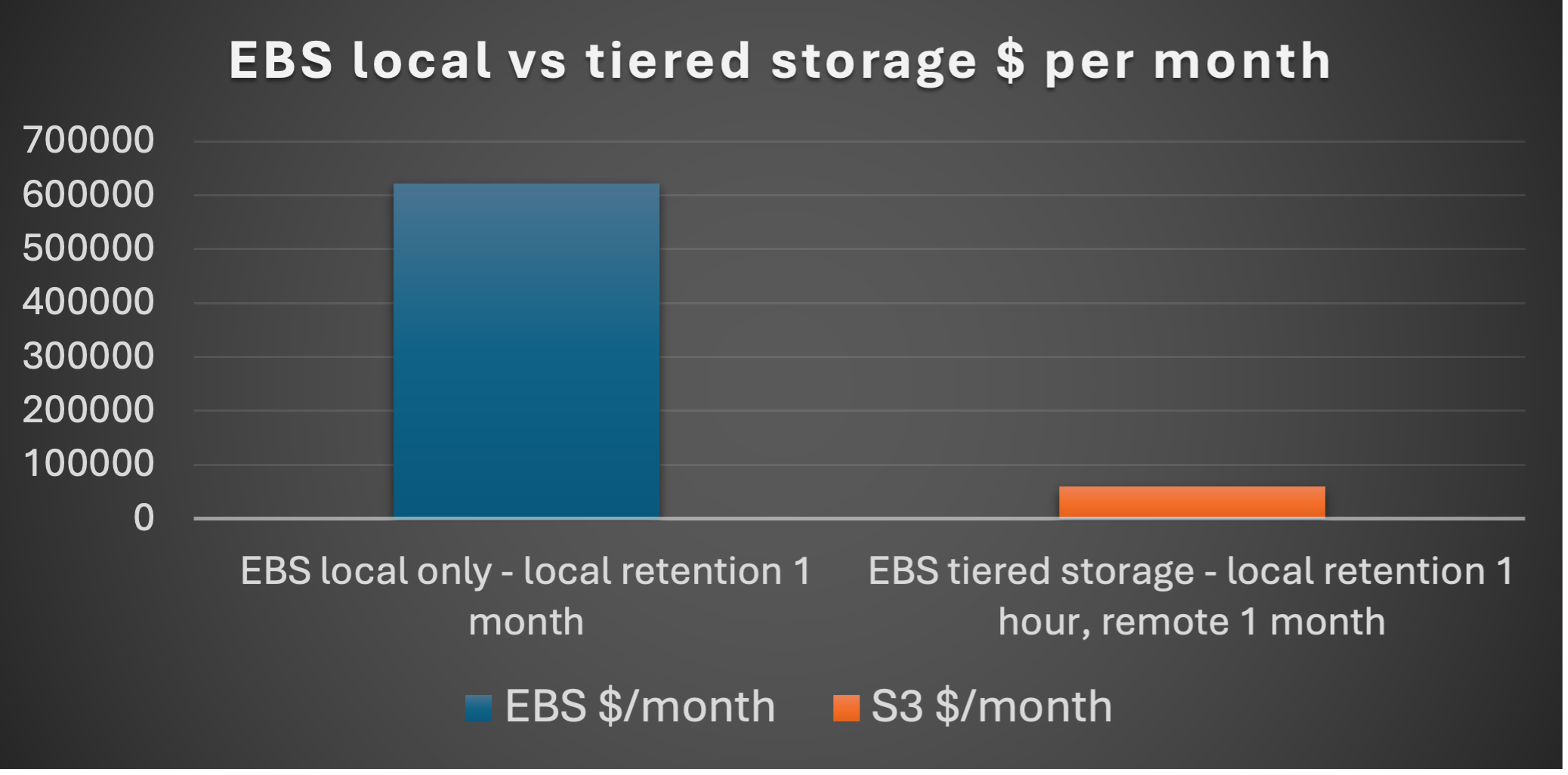
Using local-only storage for a month’s worth of records is likely unaffordable at $622,000/month! But using more remote storage is potentially more affordable at $60,000/month (about 10x cheaper).
Conclusions
From my past blogs, we noticed that turning Kafka Tiered Storage on will increase I/O and Network resources slightly. We previously computed the minimum I/O and network resources required for different workload scenarios, and the minimum number of brokers that would meet these requirements. But in practice, your existing cluster may have I/O and network resources to spare and not require resizing at all.
So, what are my conclusions here? Well, reducing local retention times (and therefore storage space as well), and increasing remote storage retention times and space, will likely save you money. Why? Because it will enable you to store more streaming data for less, opening up lots of potential Tiered Storage use cases.
Here are some of my final observations about Kafka Tiered Storage sizing:
- We built a simple “best-guess” (i.e., an in-depth Kafka architectural knowledge combined with benchmarking) Kafka sizing model of a Kafka cluster including Tiered Storage changes and cluster-level metrics (workloads)
- It hasn’t been formally validated (theoretically or practically) yet, so use it with discretion!
- In general (Tiered Storage disabled or enabled), EBS uses more network capacity than SSDs
- Tiered Storage enabled uses more I/O and/or network (maybe 10-30% more), but your current cluster may have sufficient I/O and network resources already
- Benchmarking and monitoring will tell you if it still works with the desired SLAs, or if you need to resize it
- Tiered Storage enables you to have way more storage remotely for less money (i.e. local only storage)
- Given that Tiered Storage allows you to scale processing and storage independently,
- it’s possible to scale your Kafka cluster elastically (bigger or more brokers for a short period of time) to enable higher throughput for consumer read processing for historic remote records
- (As long as the records were written with sufficient partitions originally, that is)
- it’s possible to scale your Kafka cluster elastically (bigger or more brokers for a short period of time) to enable higher throughput for consumer read processing for historic remote records
- Better models–and therefore better predictions–are possible in the future
- E.g. including CPU, topics, partitions, consumers, Tiered Storage configurations, and more!
***
And one final piece of cheese/storage trivia!
Q: How much space would you need to store 1.4 billion pounds of cheese (that’s about 635,000 metric tons)? (Well…maybe not exactly “cheese” as most people know it, but “government cheese”)
A: A 3.3 million square foot (306,580 square metres, 74 acres, or 56 American football fields) underground warehouse in Missouri that was used to even out supply and demand for cheese production and consumption in the US, starting with the Reagan era. That’s a lot of storage—and cheese!

Follow along in the How to size Apache Kafka clusters for Tiered Storage series
- Part 1: A Kafka performance model for SSDs, network and I/O
- Part 2: A Kafka performance model for SSDs/EBS, network, I/O and brokers
And check out my companion series, Why is Apache Kafka Tiered Storage more like a dam than a fountain?