Zero-downtime live migration is a gamechanger–especially for those that have come from planning IT migrations with outages in excruciating detail to ensure minimal possible impact to business.
In this blog, we will talk through a recent migration the Instaclustr Engineering team performed to move customer services from an internal, stand-alone ZooKeeper cluster to a self-hosted Managed ZooKeeper service.
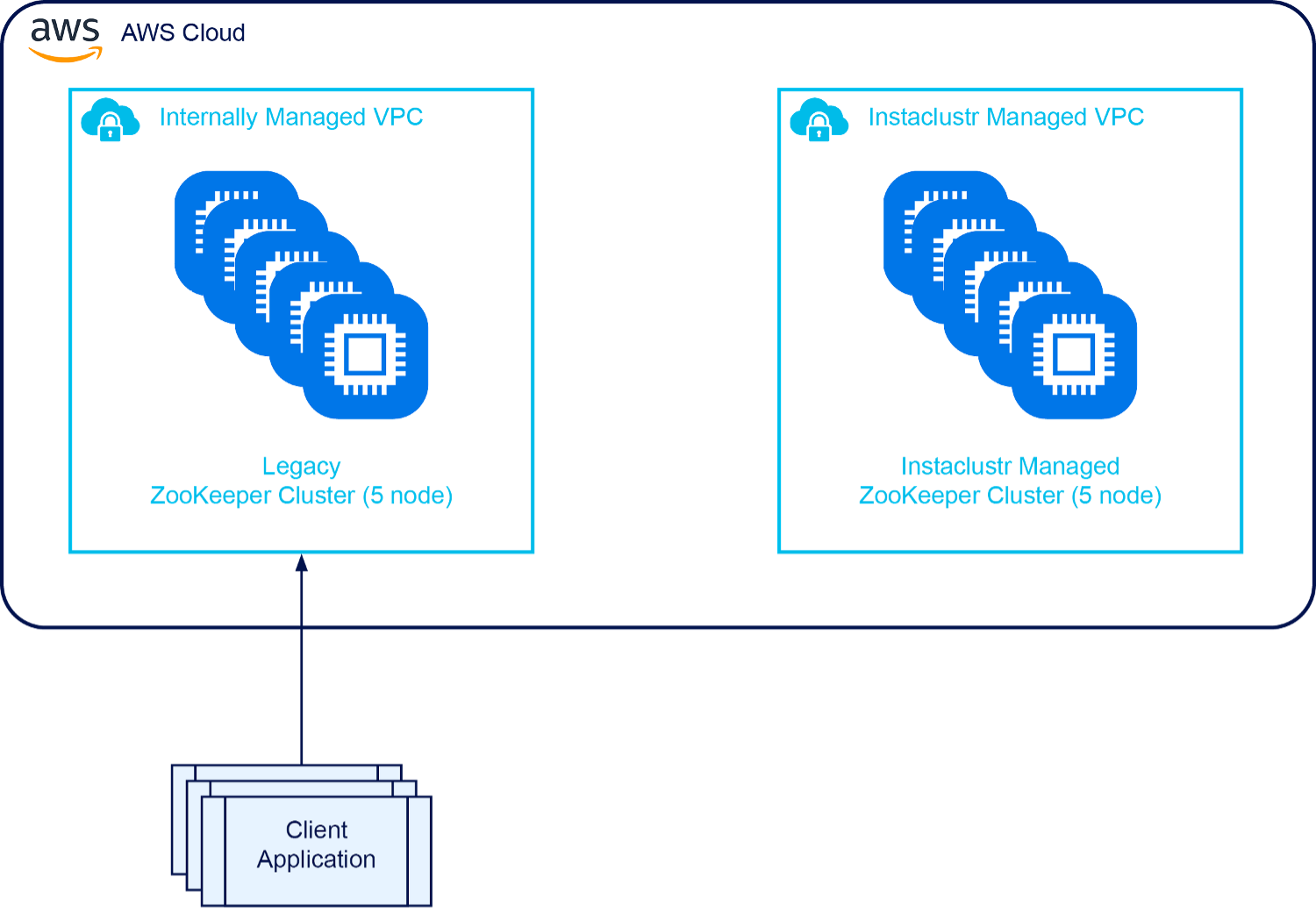
Instaclustr uses ZooKeeper for a few purposes internally within our platform, including the Managed Service customer offering plus some other ZooKeeper instances for operational purposes; one ZooKeeper cluster was used for leader election of the Managed Apache Spark™ addon to our Managed Cassandra® offering.
This was a great setup at origin, but ultimately we don’t want to be running a ZooKeeper cluster—we want to focus on building our Cassandra product. Plus, the ZooKeeper cluster came with a 24x7x365 monitoring requirement for our internal Engineering On-Call teams. While it didn’t break very often, when it did it would be a laborious task to figure out why, making ZooKeeper a tricky system for us to manage.
The Migration
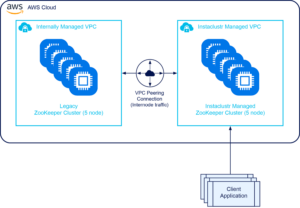
Here is a simplified illustration of the legacy setup:

In late 2022, we decided to move this ZooKeeper setup to the Instaclustr Managed Platform as a self-hosted managed service. Doing this meant we could leverage the skills of our TechOps SRE team to tune and improve our usage of ZooKeeper, as well as make use of all our internal tooling and processes that would help with running our ZooKeeper cluster day-to-day. Plus, shifting ownership removed the patching overhead from our team; I think fewer patching tasks is one advantage we can all relate to.
There were some strict requirements that were in place for the migration process:
- Unsurprisingly, we had to avoid complete outages for our customers. While an application restart was unavoidable, we needed the ability to cut clients over one by one with no major issues. Our customer clients were configured to have High Availability, so we performed a rolling restart through client clusters, ensuring only one node would go down at a time, while the remainder of the cluster continued to function.
- The migration was going to take a few months—from booking times with customers to the inevitable reschedules and delays (both external and internal)—so the setup needed to support a long-term migration approach.
- The migration had to be reversible—if something went wrong or we found an issue, we wanted the flexibility to rollback.
For the migration we decided to make use of the observers feature of ZooKeeper. In essence the new cluster would transitively migrate the data from the old cluster, while routing requests to the old cluster during the cutover period. This would mean from the client’s perspective nothing would change. The new cluster would simply listen to the old one during migration, then when we were ready we could split and reconfigure the new cluster to be its own cluster.
The migration activity followed these steps:
Step 1: Setup the new Managed ZooKeeper cluster
We used Instaclustr’s Terraform provider to create the Managed ZooKeeper cluster infrastructure.
Step 2: VPC peer the new cluster to the old cluster
Again, we used Instaclustr’s Terraform provider to peer the new cluster VPC with our legacy clusters VPC.
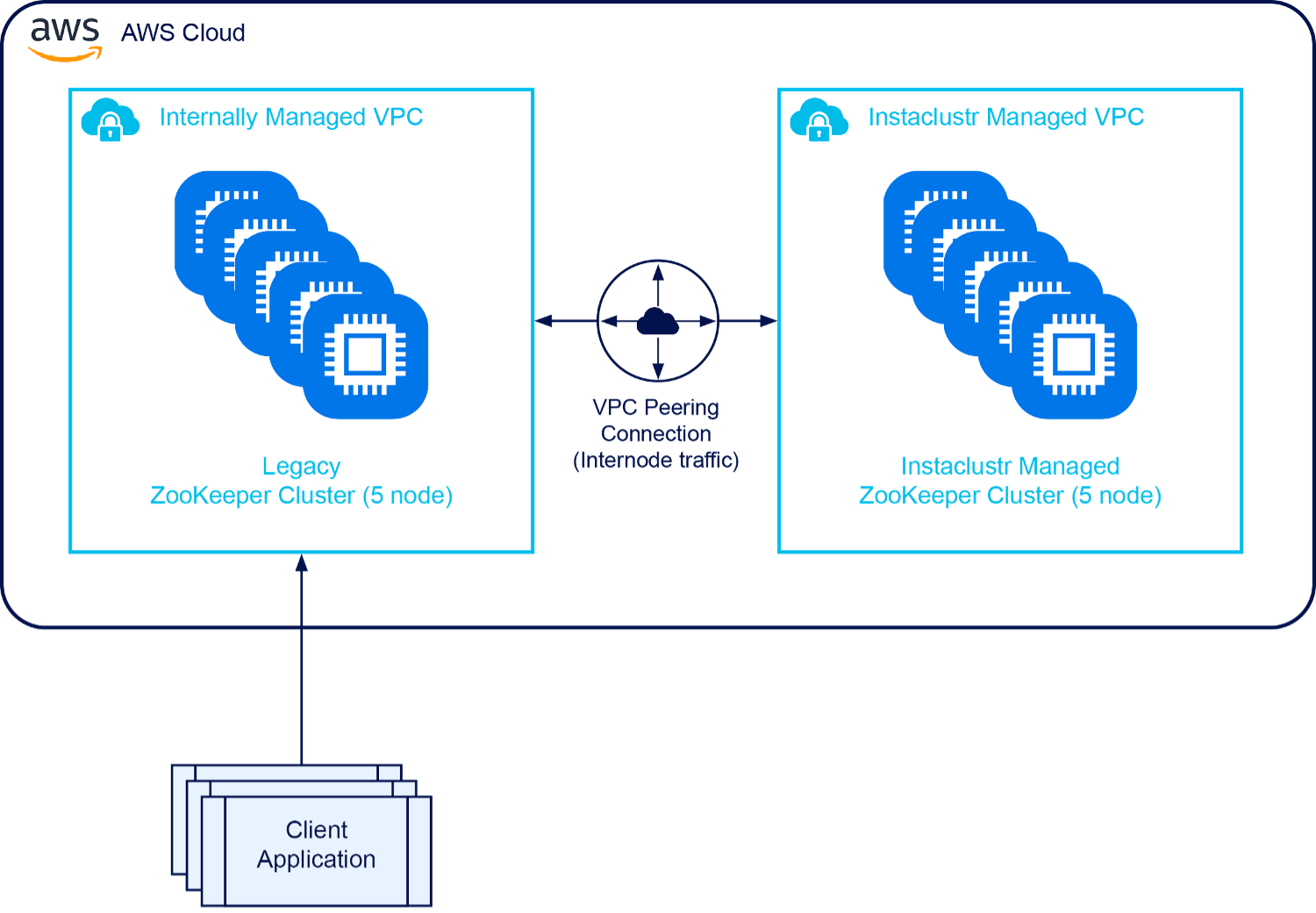
Step 3: Configure the new cluster as an observer of the old cluster
We needed our Instaclustr Kafka® team to do this as it required a complete restart of the new ZooKeeper cluster (which was fine because it wasn’t in use yet). At this point we can start the migration tasks with our Managed Spark customers.
Step 4: Roll out new config to all clients to cut them over one by one
We invested time for each customer on this migration step to ensure least possible impact. Each customer needed each client restarted with the updated configuration, one at a time.
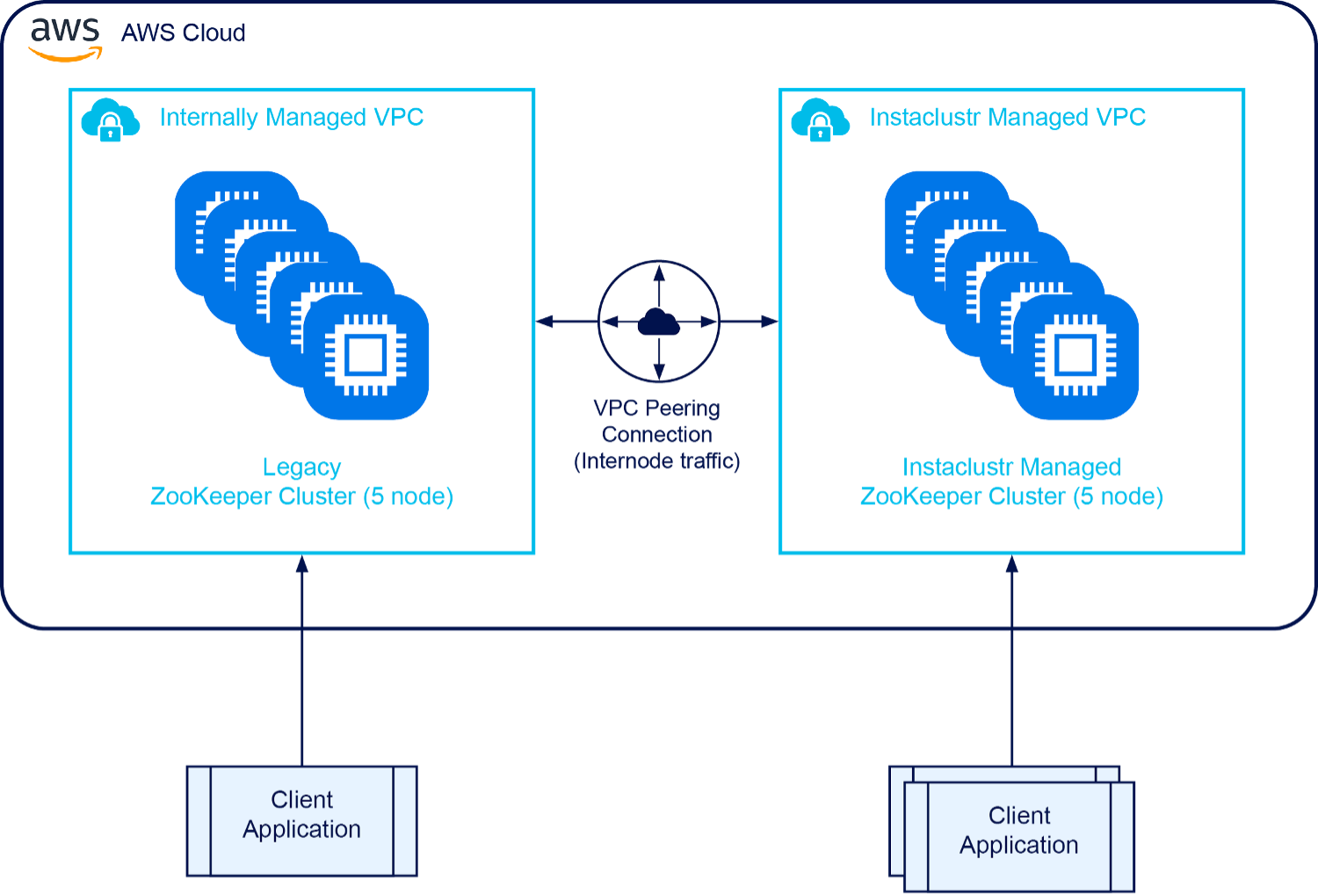
Step 5: Complete cutover of customer clients
We finally completed the cutover and reached the milestone of all customers running on the Managed ZooKeeper cluster. We could then proceed to the decommissioning work.
Step 6: Remove VPC peering connection and observer configuration
We removed the VPC peering connection and firewall rules that allowed the clusters to communicate. We then had the Kafka team update the new Managed ZooKeeper cluster configuration and restart the cluster. At this point we just needed to clean up.
Step 7: Decommission the old ZooKeeper cluster
We have snapshots of volumes in case we are in desperate need to restore later. I can’t express here how great it felt to push the button to turn off the legacy cluster!

3 Tips for Planning a Cluster Live Migration
This proved to be an interesting project and like any good project, we learned some key lessons. Here are 3 tips to consider when you are developing your own Cluster Live Migration Plan.
Do Your Clusters Have Custom Configurations?
Every client has a slightly different setup on our platform, so we cut over each customer one by one. We released the update to non-production systems first and let it soak over a week or two. Once we were confident with the change, we then cut production systems later (depending on scheduling and appropriate customer windows).
You Want a Smooth Transition When Merging and Splitting Clusters!
We coupled the cluster split with some other tasks like removing observer configuration and updating other configuration. These tasks required an outage of approximately 3 minutes to the new ZooKeeper cluster.
For our use case we were using ZooKeeper for Disaster Recovery (DR) purposes, so a 3-minute outage to this was deemed okay to proceed, noting other mechanisms in place to monitor and respond to any issues. Services that required DR during that time would auto recover as the cluster starts up again. This would not be suitable for an environment where you have a dependency on always having a ZooKeeper running all the time.
Don’t Forget to Decommission Legacy Infrastructure
The customer experience is key to a successful migration. Sometimes that means legacy infrastructure can sit around (costing money and adding to your security footprint) until there is a spare moment to blow it away. This can be extra tricky when there are delays during migration and less time to do the needful. For us it was great to switch off the legacy infrastructure (so it didn’t sit around), but it’s an important step in a solid migration plan—also it feels good to destroy infrastructure!
The decision to move off a ZooKeeper cluster to a self-hosted managed service on the Instaclustr Managed Platform was a good one for us.
Interested in learning how to do a similar migration for your organization? Reach out to Instaclustr Support and let’s get started on figuring out the best way forward for your data.