In a previous blog, I introduced a new (early access) Apache Kafka 4.0 feature: share groups, also known as queues for Kafka. In this blog, we’ll take a look at the top two use cases for Kafka Queues: scaling throughput during load peak times and reducing latency for slow consumers. Read on to learn how this feature can optimize your Kafka architecture.
Top use cases for queues in Kafka
In the earlier blog, I mentioned that KIP-932 was developed with two main use cases in mind:
- Scaling consumers for peaks: If the producer rate increases (but potentially only temporarily), but you already have the maximum permitted consumers (the number of partitions), and you need more consumers (than partitions) to ensure the throughput doesn’t drop.
- Scaling for slow consumers: If the time to process records is high, this slows down consumers, increases latency and lag, and reduces throughput. A larger (than the number of partitions) pool of consumers to handle separate messages can help achieve the target throughput and latency.
In both cases, the problem with the default consumer group is that consumers are limited to the number of partitions – you can’t increase consumers > partitions to cope with increased load (use case 1), or increased latency (use case 2).
But now, with queues for Kafka, you can – if you don’t care as much about record order. With queues for Kafka, full ordering over partitions is no longer guaranteed, only partial ordering over partition batches (potentially only size 1 – i.e. no ordering at all). Let’s look at these two use cases in more detail with the help of some performance modeling.
Use case 1 – Scaling consumers for load peaks
The following graph shows how throughput increases with increasing consumers. We use Little’s Law (Concurrency = Throughput x Time), rearranged to compute Throughput=Concurrency/Time. Concurrency is the number of Kafka Consumers (which are single threaded), and Time is the processing latency for each record. For this example, we assume a 10ms processing latency, and 100 partitions.
For the default consumer group (orange line), we can increase the number of consumers up to a maximum of the number of partitions, increasing the throughput from 100 Msgs/s to a limit of 10,000 Msgs/s – that is, we can process up to 10,000 Msgs/s without falling behind. If the message production rate briefly increases above 10,000 Msgs/s, to say 20,000 Msgs/s, what can we do? With the default consumer group, we can’t easily increase the number of consumers, resulting in an increasing processing lag and end-to-end message latency until the rate of production drops below 10,000 Msgs/s, and the consumers can eventually catch up (which will take some time).
However, using the new share group (green line), the number of consumers can be increased above the number of partitions (100, purple line), increasing the throughput and keeping up with the increased producer message rate. Once the load spike reduces back to normal, the number of consumers can be reduced again.

Use case 2 – Scaling for slow consumers
For this use case, the scenario is that records take longer to process. This can be because:
- There just may be more complex/expensive processing inside the consumer, often caused by algorithmic overhead or interacting with slower 3rd party systems.
- 3rd party systems have slowed down, taking longer than normal to process each record.
There are two potential goals for this use case:
- A. Maintaining throughput for slow consumers
- B. Reducing end-to-end latency for slow consumers
We’ll look at each in turn.
Use case 2A – Maintaining throughput for slow consumers
The goal for this case is the same as the goal for use case 1 (maintaining throughput), but the cause is due to an increase in consumer processing latency. However, the solution is the same: increasing the number of consumers.
Let’s demonstrate this by assuming the consumer latency increases 10x from 10ms to 100ms (either “by design” or due to intermittently slow backend systems). With the default consumer group (orange line), the throughput is limited to an even slower 1,000 Msgs/s. But the potential throughput with the new share group is only limited by the cluster resources and as many consumers as you can run, for example, 20,000 Msgs/s (green line) with 2,000 consumers.

Use case 2B – Reducing end-to-end latency for slow consumers
So far, my explanation of how Kafka Queues work in this and the previous blog has been simplified. In reality, there are two queues in Kafka that contribute to the total end-to-end processing latency (the total time from record production to completion of record processing, per record – for many applications, you need to minimize this and keep it consistently low):
- topic-partitions
Records are written to the topic-partitions “queues” (not real queues, but records are held in segments in order of arrival), where they wait to be processed by consumer(s) – assuming there are some (there don’t have to be, and consumers can be disconnected and come and go, potentially adding to the latency). - consumer batches
Consumers typically read multiple records at a time (per poll, the default is 500) from the topic-partitions. Because Kafka consumers are single-threaded, record processing is serialized – i.e. one at a time in order. This means that the end-to-end latency of the last record processed in each batch is higher than the first.
Batching is done primarily to optimise for throughput rather than latency (as polling itself has an overhead and takes time, making it inefficient to poll once per record). Consumers can, however, receive fewer records at a time, or even only one, depending on settings, or how many records are waiting to be processed in the topic-partitions. Here’s the complete picture.

The combination of two queue systems is getting complicated, and is tricky to model accurately with Little’s Law (but could be modelled with other techniques such as queue networks, discrete event simulation, etc). However, the important observation is that with 500 records, the end-to-end latency of the last record processed by the consumer will be worse than the end-to-end-latency of the first record processed, as it’s just the sum of the latencies of all the 500 records. The average (typically not a very useful metric for performance engineering, but easy to compute for this case), is the sum of the first and last latency/2. And, if the processing time increases significantly (e.g. due to slow consumers), then the end-to-end latency will increase dramatically.
What’s the solution? The solution offered by share groups allows for many more consumers than partitions. So, you can, in theory at least, set the batch size smaller, even as small as 1, and have as many consumers as you need to achieve the target throughput and end-to-end-latency.
This could be useful for some use cases, just remember that you will have no ordering for the extreme edge case of a batch size = 1, as each record will be acquired randomly across all the topic-partitions.
The following graph shows the max (red line) and average (blue line) end-to-end latencies for increasing batch sizes, from 1 to 500, for a 100ms (x10 latency of use case 1) constant per-record processing latency scenario. This clearly shows the impact of slow processing on the average and max end-to-end processing latencies with increasing batch sizes – with the default 500 batch size, the default consumer group has unacceptably high latencies in the 10s of seconds. However, with share groups, and a batch size of 1, the latency is reduced to the minimum possible, just the constant 100ms value.
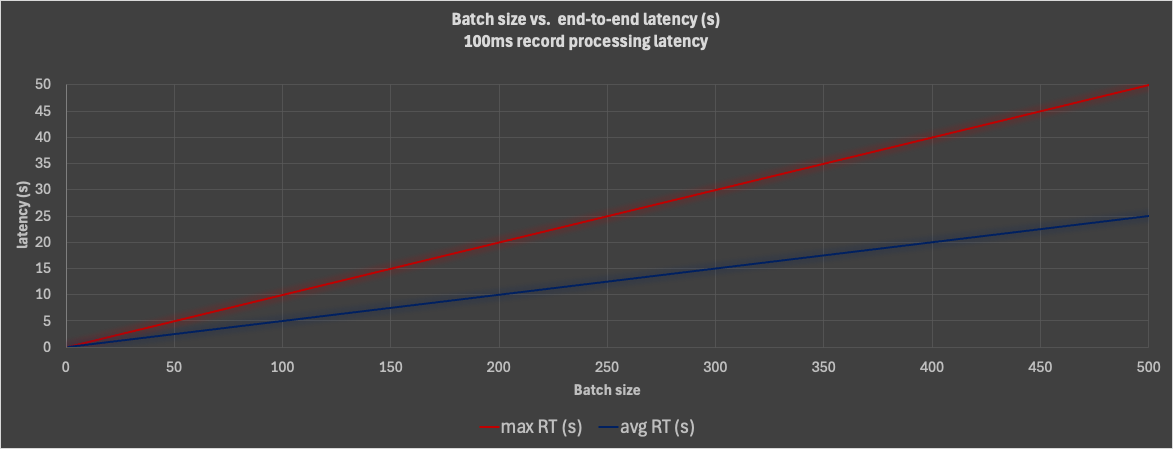
As with use case 2A, you will need at least 20,000 consumers running (with sufficient cluster and consumer sources, including threads) to achieve the target throughput, probably more – as we noted that with a batch size of 1, the system is optimised for latency, not for throughput. But the sky is the (theoretical) limit for the number of share group consumers! And this use case demonstrates that KIP-932 really is Queues for Kafka as each consumer is processing a single message at a time in true “queue processing” fashion. Kafka Queues have arrived!
Realistic applications of queues for Kafka
These Kafka queue use cases were motivated by the KIP-932 documentation and are more abstract than concrete. Let’s have a look at some more realistic Kafka queue use cases from my previous demonstration applications.
Kafka Kongo
“Kongo” (part 1) was an IoT logistics simulation with Kafka, for real-time logistics rules tracking and checking (safe transportation rules for goods on trucks, and environmental factors for goods stored in warehouses). The environmental rules checking component is a potential use case for queues for Kafka – environmental checking is single event-based without regard to event order.
Another component (written using Kafka Streams) to prevent truck overloading is a negative example, as you have to know what’s on the truck already (order matters). However, this suggests a useful heuristic – the use of Kafka Streams may be a sign that queues for Kafka may not be a good fit.
Anomalia Machina
Anomalia Machina (part 1) was a massively scalable anomaly detection application built with Cassandra, Kafka and many more open source technologies.
It took each incoming record and ran an anomaly detection algorithm over the previous 50 records with the same key, using Cassandra to persist the historic data.
On first inspection, this looks like a non-example for queues for Kafka as the records are order dependent. However, it could work with queues for Kafka in theory, as the event order was really handled by Cassandra over record timestamps (a query returned the last 50 events for a key ordered by time). It’s not that uncommon for downstream systems to handle record ordering in Kafka systems (E.g. downstream systems may handle eventual consistency, so are not as sensitive to event ordering, and Kafka Streams and Debezium need to handle out-of-order records as a matter of course).
Anomalia Machina is also a good example of:
- Slow consumers (Use case 2 – A and B). I used a “trick” to optimise the speed of the Kafka consumer polling loop by using two independent thread pools – one for the polling, and another for the anomaly checking (which was slow), and
- Kafka buffering – the ability of Kafka to absorb producer load spikes without losing messages. So that’s a good fit with Use case 1!
Kafka Tiered Storage
In a recent series on Kafka tiered storage (final part here) we took a look at the new Kafka architecture, which enables streaming more data for less by using cloud native storage for storing older records. I think this is a new and interesting queues for Kafka use case! Why? Segments are written to remote storage with the number of partitions they were written with. Reading them back again, the read throughput is limited by the number of consumers <= the number of partitions – even though, in theory at least, the read throughput of the cloud storage and a temporarily resized Kafka cluster could be way more. To read them back at a higher scale, Kafka share groups is a potential option as the number of consumers, and therefore read concurrency and throughput, isn’t dependent on the number of partitions available anymore!
Why queues for Kafka matter
In conclusion, Apache Kafka 4.0’s introduction of share groups brings a game-changing capability, enabling queues for Kafka to tackle challenges like load peaks, slow consumers, and latency-sensitive tasks. By allowing the use of more consumers than partitions, queues for Kafka offer unmatched flexibility and scalability, making it easier than ever to optimize throughput and minimize latency in diverse scenarios.
Interested in exploring queues for Kafka yourself? You can try them on the Instaclustr Managed Platform by spinning up a free, 30-day, no obligation Apache Kafka 4.0 trial cluster, and then creating a support ticket to enable KIP-932, and test the feature in a controlled environment. But remember, it’s currently only for testing and not meant for production use at this time.