Welcome back to our series on vector search benchmarking. In part 1, we dove into setting up a benchmarking project and explored how to implement vector search in PostgreSQL from the example code in GitHub. We saw how a hands-on project with students from Northeastern University provided a real-world testing ground for Retrieval-Augmented Generation (RAG) pipelines.
Now, we’re continuing our journey by exploring two more powerful open source technologies: ClickHouse and Apache Cassandra. Both handle vector data differently and understanding their methods is key to effective vector search benchmarking. Using the same student project as our guide, this post will examine the code for embedding, inserting, and retrieving data to see how these technologies stack up.
Let’s get started.
Vector search benchmarking with ClickHouse
ClickHouse is a column-oriented database management system known for its incredible speed in analytical queries. It’s no surprise that it has also embraced vector search. Let’s see how the student project team implemented and benchmarked the core components.
Step 1: Embedding and inserting data
scripts/vectorize_and_upload.py
This is the file that handles Step 1 of the pipeline for ClickHouse. Embeddings in this file (scripts/vectorize_and_upload.py) are used as vector representations of Guardian news articles for the purpose of storing them in a database and performing semantic search. Here’s how embeddings are handled step-by-step (the steps look similar to PostgreSQL).
First up, is the generation of embeddings. The same SentenceTransformer model used in part 1 (all-MiniLM-L6-v2) is loaded in the class constructor. In the method generate_embeddings(self, articles), for each article:
- The article’s title and body are concatenated into a text string.
- The model generates an embedding vector (
self.model.encode(text_for_embedding)), which is a numerical representation of the article’s semantic content. - The embedding is added to the article’s dictionary under the key
embedding.
Then the embeddings are stored in ClickHouse as follows.
- The database table
guardian_articlesis created with an embeddingArray(Float64) NOT NULLcolumn specifically to store these vectors. - In
upload_to_clickhouse_debug(self, articles_with_embeddings), the script inserts articles into ClickHouse, including the embedding vector as part of each row.
Step 2: Vector search and retrieval
services/clickhouse/clickhouse_dao.py
The steps to search are the same as for PostgreSQL in part 1. Here’s part of the related_articles method for ClickHouse:
def related_articles(self, query: str, limit: int = 5):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
"""Search for similar articles using vector similarity""" ... query_embedding = self.model.encode(query).tolist() search_query = f""" SELECT url, title, body, publication_date, cosineDistance(embedding, {query_embedding}) as distance FROM guardian_articles ORDER BY distance ASC LIMIT {limit} """ ... |
When searching for related articles, it encodes the query into an embedding, then performs a vector similarity search in ClickHouse using cosineDistance between stored embeddings and the query embedding, and results are ordered by similarity, returning the most relevant articles.
Vector search benchmarking with Apache Cassandra
Next, let’s turn our attention to Apache Cassandra. As a distributed NoSQL database, Cassandra is designed for high availability and scalability, making it an intriguing option for large-scale RAG applications.
Step 1: Embedding and inserting data
scripts/pull_docs_cassandra.py
As in the above examples, embeddings in this file are used to convert article text (body) into numerical vector representations for storage and later retrieval in Cassandra.
For each article, the code extracts the body and computes the embeddings:
|
1 2 |
embedding = model.encode(body) embedding_list = [float(x) for x in embedding] |
model.encode(body)converts the text to aNumPyarray of 384 floats.- The array is converted to a standard Python list of floats for Cassandra storage.
Next, the embedding is stored in the vector column of the articles table using a CQL INSERT:
|
1 2 3 4 5 6 |
insert_cql = SimpleStatement(""" INSERT INTO articles (url, title, body, publication_date, vector) VALUES (%s, %s, %s, %s, %s) IF NOT EXISTS; """) result = session.execute(insert_cql, (url, title, body, publication_date, embedding_list)) |
The schema for the table specifies: vector vector<float, 384>, meaning each article has a corresponding 384-dimensional embedding. The code also creates a custom index for the vector column:
|
1 2 3 4 |
session.execute(""" CREATE CUSTOM INDEX IF NOT EXISTS ann_index ON articles(vector) USING 'StorageAttachedIndex'; """) |
This enables efficient vector (ANN: Approximate Nearest Neighbor) search capabilities, allowing similarity queries on stored embeddings.
A key part of the setup is the schema and indexing. The Cassandra schema in services/cassandra/init/01-schema.cql defines the vector column.
Being a NoSQL database, Cassandra schemas are a bit different to normal SQL databases, so it’s worth taking a closer look. This Cassandra schema is designed to support Retrieval-Augmented Generation (RAG) architectures, which combine information retrieval with generative models to answer queries using both stored data and generative AI. Here’s how the schema supports RAG:
- Keyspace and table structure
- Keyspace (
vectorembeds): Analogous to a database, this isolates all RAG-related tables and data. - Table (
articles): Stores retrievable knowledge sources (e.g., articles) for use in generation.
- Keyspace (
- Table columns
url TEXT PRIMARY KEY: Uniquely identifies each article/document, useful for referencing and deduplication.title TEXTandbody TEXT: Store the actual content and metadata, which may be retrieved and passed to the generative model during RAG.publication_date TIMESTAMP: Enables filtering or ranking based on recency.vector VECTOR<FLOAT, 384>: Stores the embedding representation of the article. The new Cassandra vector data type is documented here.
- Indexing
- Sets up an Approximate Nearest Neighbor (ANN) index using Cassandra’s Storage Attached Index.
More information about Cassandra vector support is in the documentation.
Step 2: Vector search and retrieval
The retrieval logic in services/cassandra/cassandra_dao.py showcases the elegance of Cassandra’s vector search capabilities.
The code to create the query embeddings and perform the query is similar to the previous examples, but the CQL query to retrieve similar documents looks like this:
|
1 2 3 4 5 6 7 8 |
query_cql = """ SELECT url, title, body, publication_date FROM articles ORDER BY vector ANN OF ? LIMIT ? """ prepared = self.client.prepare(query_cql) rows = self.client.execute(prepared, (emb, limit)) |
What have we learned?
By exploring the code from this RAG benchmarking project we’ve seen distinct approaches to vector search. Here’s a summary of key takeaways:
- Critical steps in the process:
- Step 1: Embedding articles and inserting them into the vector databases.
- Step 2: Embedding queries and retrieving relevant articles from the database.
- Key design pattern:
- The DAO (Data Access Object) design pattern provides a clean, scalable way to support multiple databases.
- This approach could extend to other databases, such as OpenSearch, in the future.
- Additional insights:
- It’s possible to perform vector searches over the latest documents, pre-empting queries, and potentially speeding up the pipeline.
What’s next?
So far, we have only scratched the surface. The students built a complete benchmarking application with a GUI (using Steamlit), used multiple other interesting components (e.g. LangChain, LangGraph, FastAPI and uvicorn), Grafana and LangSmith for metrics, and Claude to use the retrieved articles to answer questions, and Docker support for the components. They also revealed some preliminary performance results! Here’s what the final system looked like (this and the previous blog focused on the bottom boxes only).
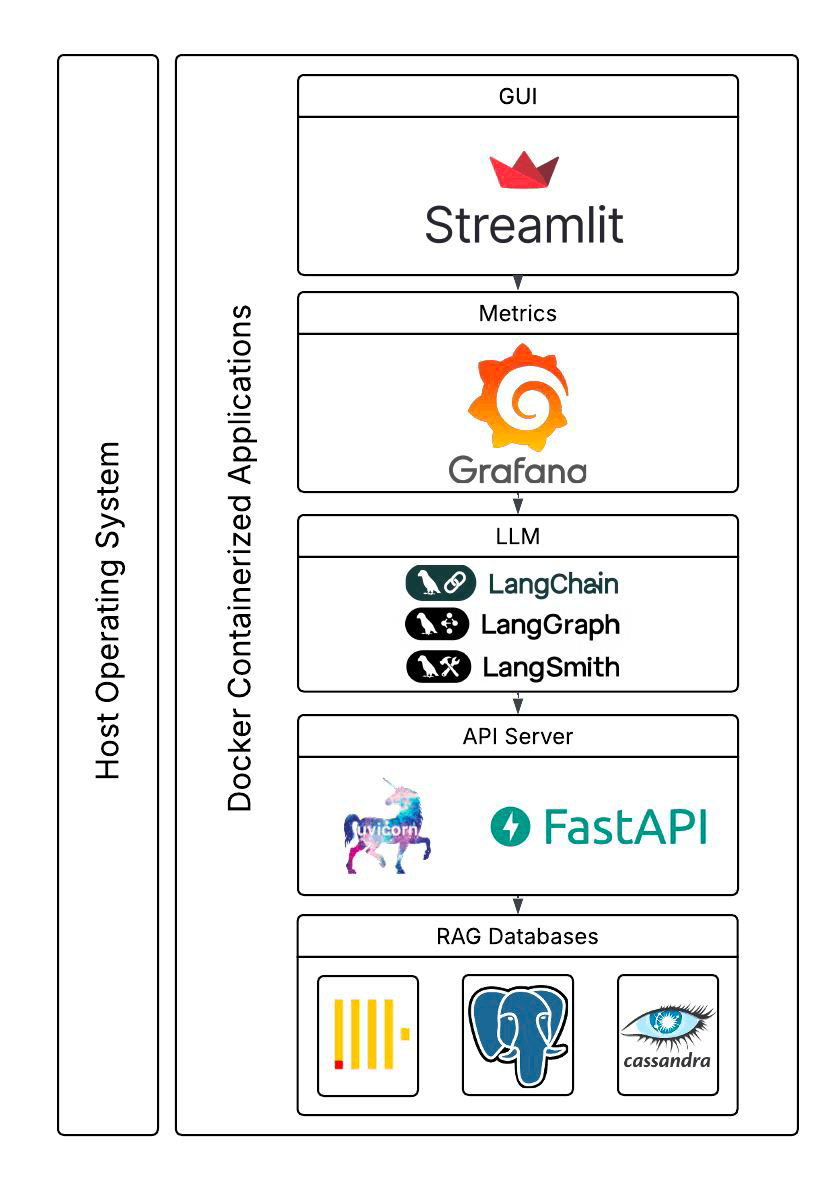
In a future article, we will examine the rest of the application code, look at the preliminary performance results the students uncovered, and discuss what they tell us about the trade-offs between these different databases.
Ready to learn more right now? We have a wealth of resources on vector search. You can explore our blogs on ClickHouse vector search and Apache Cassandra Vector Search (here, here, and here) to deepen your understanding.