Introduction
In the current excitement around Generative AI (GenAI) and Large Language Models (LLMs), the quest for the perfect vector database has become a focal point for many companies!
Indeed, vector storage and vector search are both crucial for many GenAI applications – but are dedicated vector databases truly essential for scaling and optimizing GenAI? When does investing in these technologies begin to pay off?
Last August, my colleague published an insightful article shining a light on this very phenomenon that suggested part of the answer: what if on the lookout for the latest and greatest in vector database technology, companies are overlooking existing and versatile databases they already trust and use at scale for their critical data workloads? (Think Apache Cassandra 5.0®, OpenSearch® and PostgreSQL®).
The conclusion resonated deeply with me, and it serves as a cornerstone for the discussion in this article:
“The solution to tailored LLM responses isn’t investing in some expensive proprietary vector database and then trying to dodge the very real risks of vendor lock-in or a bad fit. At least it doesn’t have to be.
“Recognizing that available open-source vector databases are among the top options out there for AI development — including some you may already be familiar with or even have on hand — should be a very welcome revelation.”
This perspective is particularly relevant as we explore how ClickHouse can be leveraged for vector search.
The work required to put together this article was driven by the need to highlight open source, multi-purpose, and cost-effective solutions that can empower businesses to harness the full potential of their data without falling into the trap of unnecessary expenditures and dependencies (if not vendor lock in and up skilling investments).
Some background context
Before you jump into the rest of this blog, I recommend that you read through this article. It showcases the paramount role of open source in modern data infrastructure, but with a particular focus on vector databases.
You may have noticed something missing: ClickHouse®!
So, what actually is it?
ClickHouse is an open source, high-performance, columnar-oriented database management system (DBMS) designed for Online Analytical Processing (OLAP) of large datasets. It’s the latest addition to Instaclustr’s managed open source frameworks and databases to help our customers build their advanced data and AI workloads. Our engineering team is ensuring we are aligned with its latest releases, as well as providing the latest features and improvements to our users.
Our engineering team is ensuring we are aligned with its latest releases, as well as providing the latest features and improvements to our users.
Now that ClickHouse is available on the Instaclustr Managed Platform, it’s time to showcase its amazing capabilities in the vector search space.
Why ClickHouse for vector search?
It’s simple, really: ClickHouse offers several key advantages that make it great for vector search, like:
- High Performance: Its columnar storage and efficient compression make ClickHouse ideal for efficient storage and fast queries, enabling rapid data retrieval and analysis.
- Scalability and Distributed Architecture: Designed for distribution across multiple nodes, ClickHouse can handle petabytes of data and leverage all available CPU cores and disks.
- Compatibility: ClickHouse integrates perfectly with other systems like Apache Kafka® and Apache Spark™, making it easy to incorporate into existing data pipelines and workflows. Additional compatibility with AI frameworks like LangChain and Hugging Face allows integrations within a broader AI ecosystem.
- Open Source: Free to use with a strong community and active development.
These points highlight how compelling ClickHouse can be for handling large-scale analytical workloads (and here’s a blog I wrote that explains even more benefits).
ClickHouse has expanded its capabilities to support vector operations, enabling it to handle AI and GenAI tasks such as vector and semantic search without requiring additional infrastructure.
This new functionality allows users to store and query vectors directly within ClickHouse, leveraging its high-performance architecture to perform complex vector-based operations efficiently.
What can we do with this? Endless opportunities!
Vector search applications are widely used in various domains. For instance, they are essential for real-time Retrieval Augmented Generation (RAG), where integrating vector databases helps retrieve relevant information to enhance LLM outputs. They also improve contextual understanding by enriching generative responses with relevant data stored in the database.
Additionally, they enable cross-modal capabilities, allowing for comparison of multiple data types (e.g., text, images, video). This magic happens thanks to representations (embeddings) that capture the underlying similarities between two pieces of content, going beyond their superficial attributes.
Imagine comparing items based on their deep, intrinsic features rather than just their looks—it’s like judging a book by its content, not its cover! This is a game-changer since we can achieve more nuanced and accurate similarity assessments.
For example: the images accompanying this blog were generated by Microsoft Designer. By entering a phrase, the model generates these images, likely using a vector database to achieve this.
Here what pops up when you enter “Vector Search database” or” Vector similarity”:

A “vector search” image generate by Microsoft Designer (Source: Microsoft Designer)
Now, the possibilities are endless and only limited by your imagination. You could create a recommendation system for music based on the books you’re reading, the work you’re doing (like coding or writing futuristic blogs), or even your mood or the weather.
Yes, your playlist could change from Singing in the Rain to Here Comes the Sun (that was an easy one). However, you will still need to create embeddings for all the raw data (books, songs, etc.)
Now, let’s bring the key concepts together using a wildly popular website: Wikipedia. By using Wikipedia, we can develop search systems that fetch relevant information based on user query. I’ll show you how to use Instaclustr Managed ClickHouse for vector embedding storage and perform vector search, and explore KNN and some other best practices for optimizations.
Using Instaclustr for ClickHouse to store vectors: a real-life example
With its distributed architecture, ClickHouse can efficiently handle datasets containing millions (or even billions) of embeddings. Instaclustr Managed ClickHouse comes fully equipped and optimized to ensure that the storage and retrieval of high-dimensional vectors are both scalable and performant.
Generating vector embeddings involves using models to convert raw data into numerical vectors that capture the essence of the data. This process is not a built-in function of ClickHouse (although some specialized vector databases offer it as a built-in feature). The widely adopted approach is to preprocess the data and compute embeddings externally using various frameworks.
Options for generating embeddings include using external APIs, which are chargeable services. Additionally, you can rely on seamless integrations with frameworks like Hugging Face and LangChain that allow you to run a model of your choice and create a complete pipeline for embedding generation.
The recommended approach, if you prefer to keep your data private or avoid relying on external services, is using open source models and frameworks. Be mindful that this process requires some expertise and substantial cost, especially if you plan to scale up significantly.
The dataset
Thanks to the vibrant ecosystem and communities with a sharing spirit, companies like Cohere have created millions of Wikipedia article embeddings (which made this blog possible) in different languages and made them available (and free to use) in Hugging Face datasets. Using their Multilingual embedding model, Cohere have embedded millions of Wikipedia articles in many languages. The articles are broken down into passages, and an embedding vector is calculated for each passage.
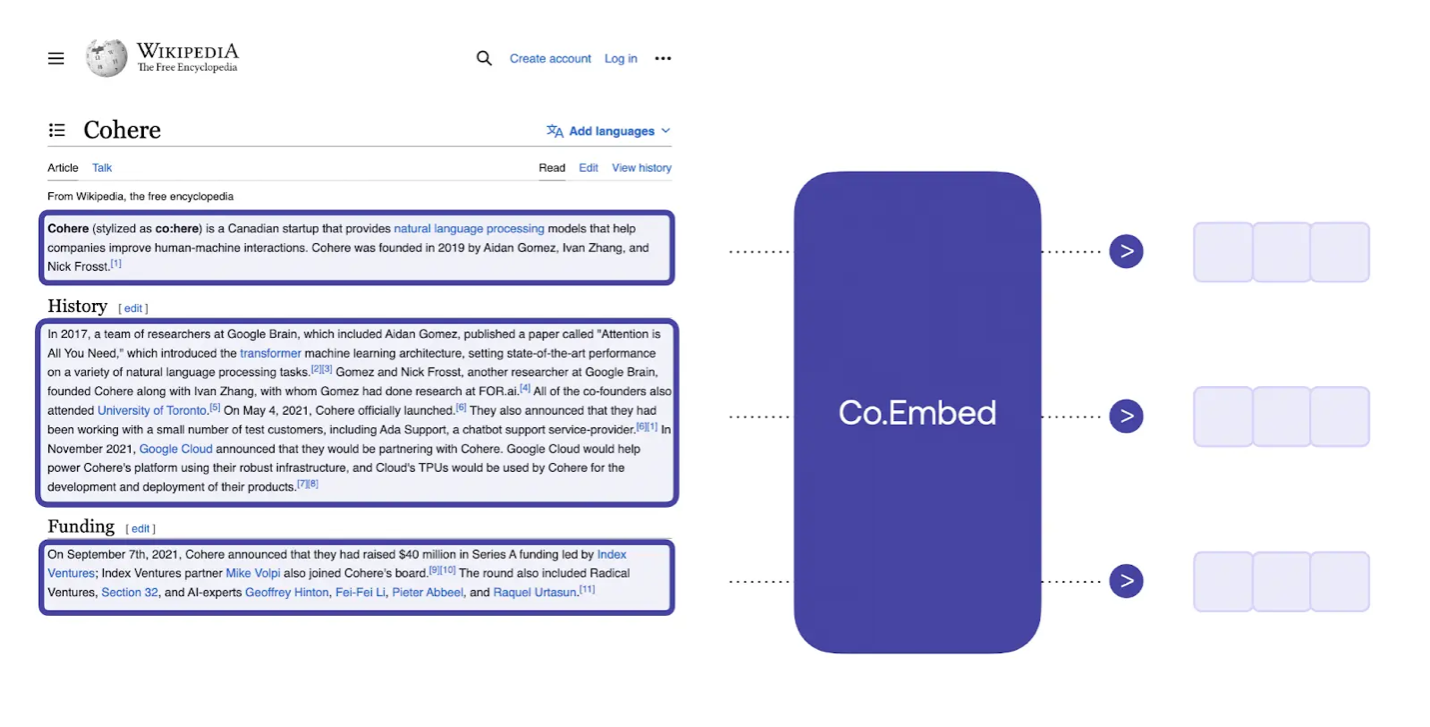
Source: The Embedding Archives: Millions of Wikipedia Article Embeddings in Many Languages
Let’s also take a moment to celebrate the incredible role of Hugging Face as the go-to platform for sharing models and datasets. Providing access to thousands of models and datasets, we are excited to highlight that Hugging Face relies on NetApp storage technology to efficiently serve this vast repository of models and datasets, ensuring high performance and reliability.
In the following, we will use the encoded Wikipedia (simple English) stored in this Hugging Face dataset containing both the text, embedding vector, and additional metadata values. Creating a simple yet powerful example of how vectors can be stored and utilized to perform a vector search using Instaclustr’s ClickHouse managed service.
First steps
Before we jump in, if you are new to Instaclustr and want to get hands-on and follow the rest of this blog, please refer to this tutorial to create a free trial account in a few clicks. You can then create a ClickHouse managed cluster under the free trial period. The provisioning may take up to 10 minutes, depending on the AWS region.
I will use DBeaver Community as my companion (as it has been for years now for database development) for all the SQL queries and results you will find below. You can connect DBeaver to your Instaclustr managed ClickHouse by following the guide.
Before creating the table and inserting the data, I spent some time analyzing the data. You can start by familiarizing yourself with the full description of the columns using the Dataset viewer in Hugging Face (screenshot below):
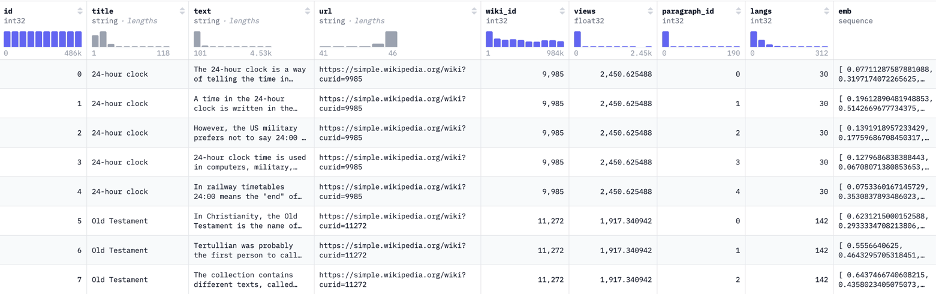
From Cohere’s blog: The emb column contains the embedding of that passage of text (with the title of the article appended to its beginning). This is an array of 768 floats (the embedding dimension of Cohere’s multilingual-22-12 embedding model).1
Jump into your SQL editor and use DESCRIBE to identify the columns and infer their type. ClickHouse’s ability to infer data types is usually sufficient and doesn’t require additional manual effort.
Additionally, you can use the SELECT command to inspect a few lines of the data. This allows you to understand the structure and content of the data, ensuring that the inferred types align with your expectations.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- Describes the content of the parquet file DESCRIBE url('https://huggingface.co/datasets/Cohere/wikipedia-22-12-simple embeddings/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet', 'Parquet') SETTINGS enable_url_encoding = 0, max_http_get_redirects = 1; -- Select few lines to get the data in the parquet files SELECT * FROM url('https://huggingface.co/datasets/Cohere/wikipedia-22-12-simple embeddings/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet', 'Parquet') LIMIT 2 FORMAT Vertical SETTINGS enable_url_encoding = 0, max_http_get_redirects = 1; |
In ClickHouse, the enable_url_encoding setting is used to control whether URL encoding is applied to the URLs used in functions like the url table function. This setting can be important when dealing with URLs that contain special characters or spaces that need to be properly encoded to be valid in HTTP requests.
The max_http_get_redirects setting is used to specify the maximum number of HTTP redirects that the server will follow when making an HTTP GET request. This setting is particularly relevant when ClickHouse is configured to fetch data from external sources over HTTP, such as when using the url table function or the remote table engine. You can set these parameters in your session for all the rest of the remote queries.
The result from the above queries will return the following:


Based on the inferred data type result, we can proceed to create our source table. While starting with a MergeTree table engine is a solid choice, using the id column as an index is somewhat arbitrary (we will discuss some optimizations to consider later on).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE wiki_emb ( `id` UInt32, `title` String, `text` String, `url` String, `wiki_id` UInt32, `views` UInt32, `paragraph_id` UInt32, `langs` UInt32, `emb`Array(Float32) ) ENGINE = MergeTree ORDER BY id; |
Inserting data
We will use the url function to read the Parquet files and insert their data into the wiki_emb table. Considering that you are using the Instalcustr managed service for ClickHouse, this will be done in parallel.
Since the size of the data remains small (1.63 Gb) and using the free trial Instaclustr managed ClickHouse service we can do a bulk insert using the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SET max_http_get_redirects = 1 SET enable_url_encoding = 0 INSERT INTO wiki_emb SELECT * FROM ( SELECT * FROM url('https://huggingface.co/datasets/Cohere/wikipedia-22-12 simple-embeddings/resolve/refs%2Fconvert%2Fparquet/default/train/0000.parquet', 'Parquet') UNION ALL SELECT * FROM url('https://huggingface.co/datasets/Cohere/wikipedia-22-12 simple-embeddings/resolve/refs%2Fconvert%2Fparquet/default/train/0001.parquet', 'Parquet') UNION ALL SELECT * FROM url('https://huggingface.co/datasets/Cohere/wikipedia-22-12 simple-embeddings/resolve/refs%2Fconvert%2Fparquet/default/train/0002.parquet', 'Parquet') UNION ALL SELECT * FROM url('https://huggingface.co/datasets/Cohere/wikipedia-22-12 simple-embeddings/resolve/refs%2Fconvert%2Fparquet/default/train/0003.parquet', 'Parquet') ) AS data_sources; |
We have created the table and inserted the data from the Parquet file containing the embeddings and the additional metadata. We have kept things simple so far by using some basic default choices. This approach allows us to establish a functional baseline, which we can then refine and optimize as we gain more insights into our data and performance requirements.
Next, let’s discuss some optimization considerations to enhance the previous 2 steps. If we want to scale significantly, the Cohere/wikipedia-2023-11-embed-multilingual-v3 containing the full dump from 2023-11-01 from Wikipedia in all 300+ languages is 536 Gb. We would need terabytes of embedded data to build a full-scale search engine using all the extra media content included in Wikipedia.
Optimizing performance for vector storage and insertions
Besides the usual – indexing, partitioning (when necessary), and materialized views —that depend on the potential applications we want to build on top of these embeddings, there are two points I want to emphasize, one for each part of the two previous steps: storage and insertions.
Storage optimization with compression: the compression of floating-point numbers remains an active and evolving area of research due to the unique challenges these data types present. Their variability and lack of repetitive patterns make them less amenable to traditional compression algorithms.
Therefore, don’t expect to gain significant compression ratios using the default codecs such as LZ4 and Delta. These codecs are particularly effective for columns with repetitive or similar values, such as categorical data or time series.
However, slightly better compression ratios for arrays of floating-point numbers can be achieved using ZSTD. You can specify the use of ZSTD compression for columns storing floating-point numbers to achieve better compression ratios.
|
1 |
ALTER TABLE wiki_emb MODIFY COLUMN emb Array(Float32) CODEC(ZSTD); |
Another potential approach commonly used in the AI field is Quantization. While we may not fully test and implement this technique here, we can benefit from its principles.
Quantization involves representing the vectors with lower-precision data types, such as 16-bit floats instead of the usual 32-bit floating points. This can significantly reduce the storage requirements while maintaining an acceptable level of precision for many applications.
Batch Inserts and Data management: With ClickHouse, you should ALWAYS use batch inserts to load your data. This reduces the overhead associated with multiple insert operations.
Another Good practice is including a file_name column in our schema that contains the name of the original remote Parquet file from which data is inserted. Allowing us to keep track of the specific file’s success during insertion into ClickHouse. Additionally, if an error occurs during data insertion (network connectivity is a major cause) you can quickly identify which file was not inserted and address it accordingly.
Using Instaclustr for ClickHouse to search and retrieve similar vectors

Source: Microsoft Designer
In this section, we’ll break down the process of obtaining an embedding and making a ClickHouse request to determine the distance from the query phrase to the closest match. When a user inputs a search phrase like “Who is Linus Torvalds,” we need to convert this phrase into a vector to compare it with the Wikipedia embeddings and find the best match.
Please keep in mind that this blog was built to showcase the vector search capabilities of ClickHouse. By breaking down the process into small sets of basic SQL queries and Python scripts, the goal is to make the concepts accessible and easy to follow.
All the manual work, such as copying and pasting a 768-long embedding, is not only unnecessary, but also not recommended outside of this blog! Instead, using a framework like Langchain, we can streamline the workflow. We can integrate various components seamlessly, creating a pipeline that ties everything together. Such a pipeline handles everything from taking a query as input to embedding generation, vector search, and result retrieval.
Steps to generate embeddings
To generate embeddings using Cohere’s multilingual-22-12 embedding model, you need to follow these steps; this example assumes you are using Python and the Cohere API.
You will need first to get an API key from Cohere. Sign up at Cohere’s website and get your API key from the dashboard. The Cohere API calls made using trial keys are free of charge, rate-limited, and cannot be used for commercial purposes (this blog is intended for informational purposes only)
Here’s a sample code snippet that demonstrates how to do this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# Install the Cohere Python SDK # pip install cohere import cohere # Initialize the Cohere client with your API key api_key = 'your-api-key-here' co = cohere.Client(api_key) # Define the text you want to generate embeddings for text = " Who created Unix " # Replace with your query # Generate the embeddings using the multilingual-22-12 model response = co.embed( texts=[text], model='multilingual-22-12' ) # Extract the embedding from the response embedding = response.embeddings[0] # Print the embedding print(embedding) # Verify the length of the embedding print(f'Length of embedding: {len(embedding)}') Output: [0.12451172, 0.20385742, -0.22717285, 0.39697266, -0.04095459 … 0.42578125, 0.23034668, 0.39160156, 0.116760254, 0.046661377, 0.1430664] Length of embedding: 768 |
Querying for vector search

Source: Microsoft Designer
Now comes the exciting part: utilizing these vectors to find the most relevant to a given search text. What we need to do is to go through all the stored vectors and compare how far each of them is from our search query. ClickHouse will calculate the distance and sort them by the distance and return top results with the minimal value for the distance.
Native vector functions
ClickHouse has introduced different functions allowing to calculate similarity metrics between vectors directly in SQL queries. The most useful, in our context, are cosineDistance and L2Distance.
Using the cosineDistance, we get better results.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT title, url, paragraph_id, text, cosineDistance(emb, [Paste the embeddings]) AS distance FROM wiki_emb ORDER BY distance ASC LIMIT 5 FORMAT Vertical; |
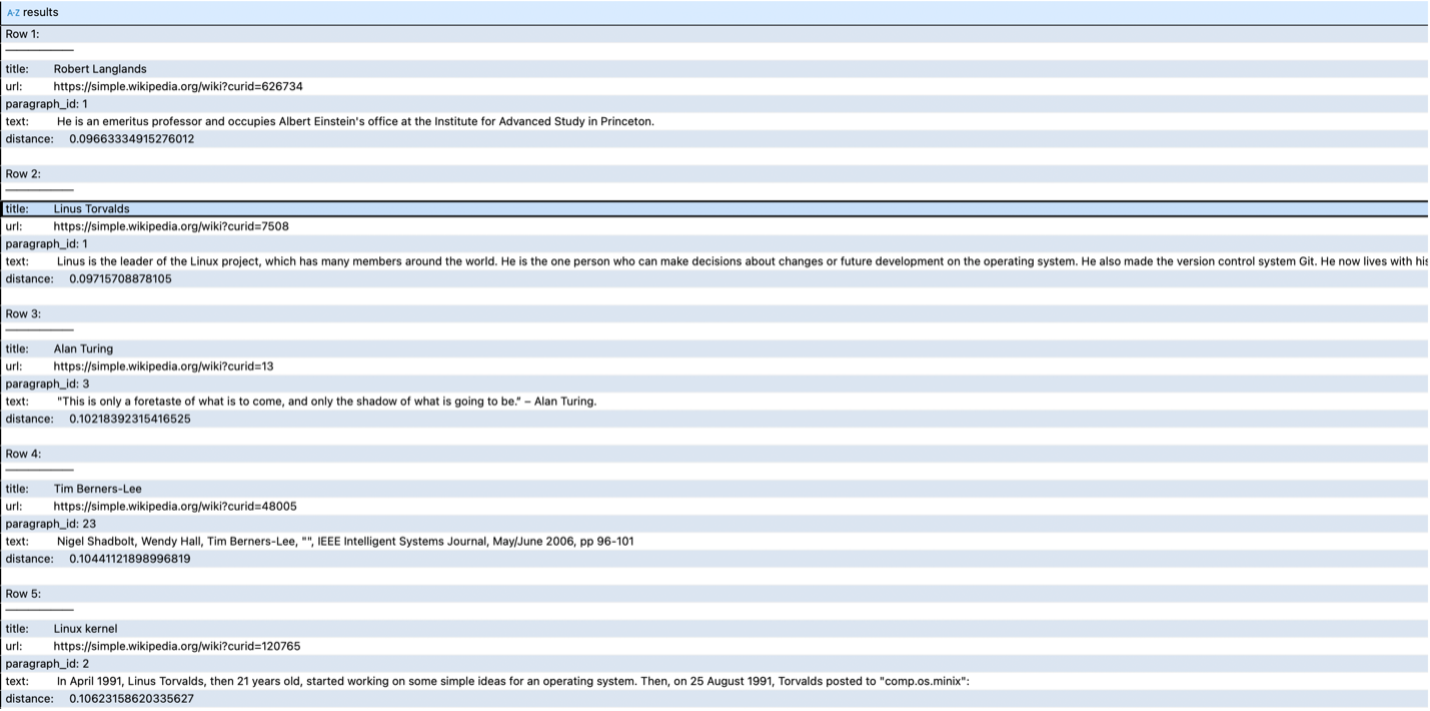
Not bad as a first result! With 8 GB of RAM and 4 CPUs, and without any extra tuning or optimization, it took less than a second (0.633 sec) to get the top 5 similar vectors in a table with 485,859 rows. It’s always good to start small and create some baseline metrics.
Now, you might be wondering: if we had a table with 4 billion rows, would it take 10,000 times longer to get the same result?
Spoiler alert: No, it wouldn’t!
ClickHouse is designed to handle massive datasets with impressive efficiency. You can try it out and see for yourself.
Advantages of using ClickHouse for vector search
Let’s recap some of the benefits of ClickHouse for vector search. Some of these benefits will become even more apparent as we advance in this series:
ClickHouse is a good fit for vector search when you need to combine vector matching with metadata filtering or aggregation, particularly for very large vector datasets that require parallel processing across multiple CPU cores.
If you choose to use (or are already using) ClickHouse for analytics workloads, expanding it to include vector search eliminates the need to deploy and manage additional services, simplifying your tech stack capabilities (making it the Swiss Army knife for real-time analytics and AI). To summarize:
- Leverage existing infrastructure for new workloads.
- Combine semantic search results with standard SQL analytics in a single query.
- Highly configurable, allowing you to tailor performance optimizations (e.g., compression, indexing) to your use case.
- Full control over your data and freedom to customize without vendor lock-in.

Source: Microsoft Designer
Conclusion
ClickHouse offers a performant and cost-effective option that covers most vector storage needs. With its vibrant community and evolving ecosystem, ClickHouse’s vector search capabilities are likely to expand even more, further solidifying its position as a multi-purpose platform for both traditional OLAP and AI-driven workloads.
At NetApp, we address one of the major challenges with ClickHouse: the complexity in setup and maintenance. We ensure optimal performance, configuration, monitoring, and tuning with a dedicated team of experts to manage it all and help you get the best from it. This allows you to focus on deriving value from your business without getting burdened by the technical intricacies of managing a ClickHouse deployment.
So, if you want to experience Instaclustr for ClickHouse yourself, sign up for a free trial and get started today or reach out to [email protected] and discuss your use case.
==
1 From The Embedding Archives: Millions of Wikipedia Article Embeddings in Many Languages by Nils Reimers and Jay Alamaar