Apache Cassandra® is moving towards an AI-driven future–especially now with vector search in Cassandra 5.0.
Cassandra’s high availability and ability to scale with large amounts of data have made it the obvious choice for many of these types of applications.
In the constantly evolving world of data analysis, we have seen significant transformations over time. The capabilities needed now are those which support a new data type (vectors) that has accelerated in popularity with the growing adoption of Generative AI and large language models. But what does this mean?
Data analysis past, present and future
Traditionally, data analysis was about looking back and understanding trends and patterns. Big data analytics and predictive ML applications emerged as powerful tools for processing and analyzing vast amounts of data to make informed predictions and optimize decision-making.
Today, real-time analytics has become the norm. Organizations require timely insights to respond swiftly to changing market conditions, customer demands, and emerging trends.
Tomorrow’s world will be shaped by the emergence of generative AI. Generative AI is a transformative approach that goes way beyond traditional analytics. Instead, it leverages machine learning models trained on diverse datasets to produce something entirely new while retaining similar characteristics and patterns learned from the training data.
By training machine learning models on vast and varied datasets, businesses can unlock the power of generative AI. These models understand the underlying patterns, structures, and meaning in the data, enabling them to generate novel and innovative outputs. Whether it’s generating lifelike images, composing original music, or even creating entirely new virtual worlds, generative AI pushes the boundaries of what is possible.
Broadly speaking, these generative AI models store the ingested data in numerical representation, known as vectors (we’ll dive deeper later). Vectors capture the essential features and characteristics of the data, allowing the models to understand and generate outputs that align with those learned patterns.
With vector search capabilities in Apache Cassandra® 5.0, we enable the storage of these vectors and efficient searching and retrieval of them based on their similarity to the query vector. ‘Vector similarity search’ opens a whole new world of possibilities and lies at the core of generative AI.
The ability to create novel and innovative outputs that were never explicitly present in the training data has significant implications across many creative, exploratory, and problem-solving uses. Organizations can now unlock the full potential of their data by performing complex similarity-based searches at scale which is key to supporting AI workloads such as recommendation systems, image, text, or voice matching applications, fraud detection, and much more.
What is vector search?
Vectors are essentially just a giant list of numbers across as many or as few dimensions as you want… but really they are just a list (or array) of numbers!
Embeddings, by comparison, are a numerical representation of something else, like a picture, song, topic, book; they capture the semantic meaning behind each vector and encode those semantic understandings as a vector.
Take, for example, the words “couch”, “sofa”, and “chair”. All 3 words are individual vectors, and while their semantic relationships are similar—they are pieces of furniture after all—but “couch” and “sofa” are more closely related to each other than to “chair”.
These semantic relationships are encoded as embeddings—dense numerical vectors that represent the semantic meaning of each word. As such, the embeddings for “couch” and “sofa” will be geometrically closer to each other than to the embedding for “chair.” “Couch”, “sofa”, and “chair” will all be closer than, say, to the word “erosion”.
Take a look at Figure 1 below to see that relationship:
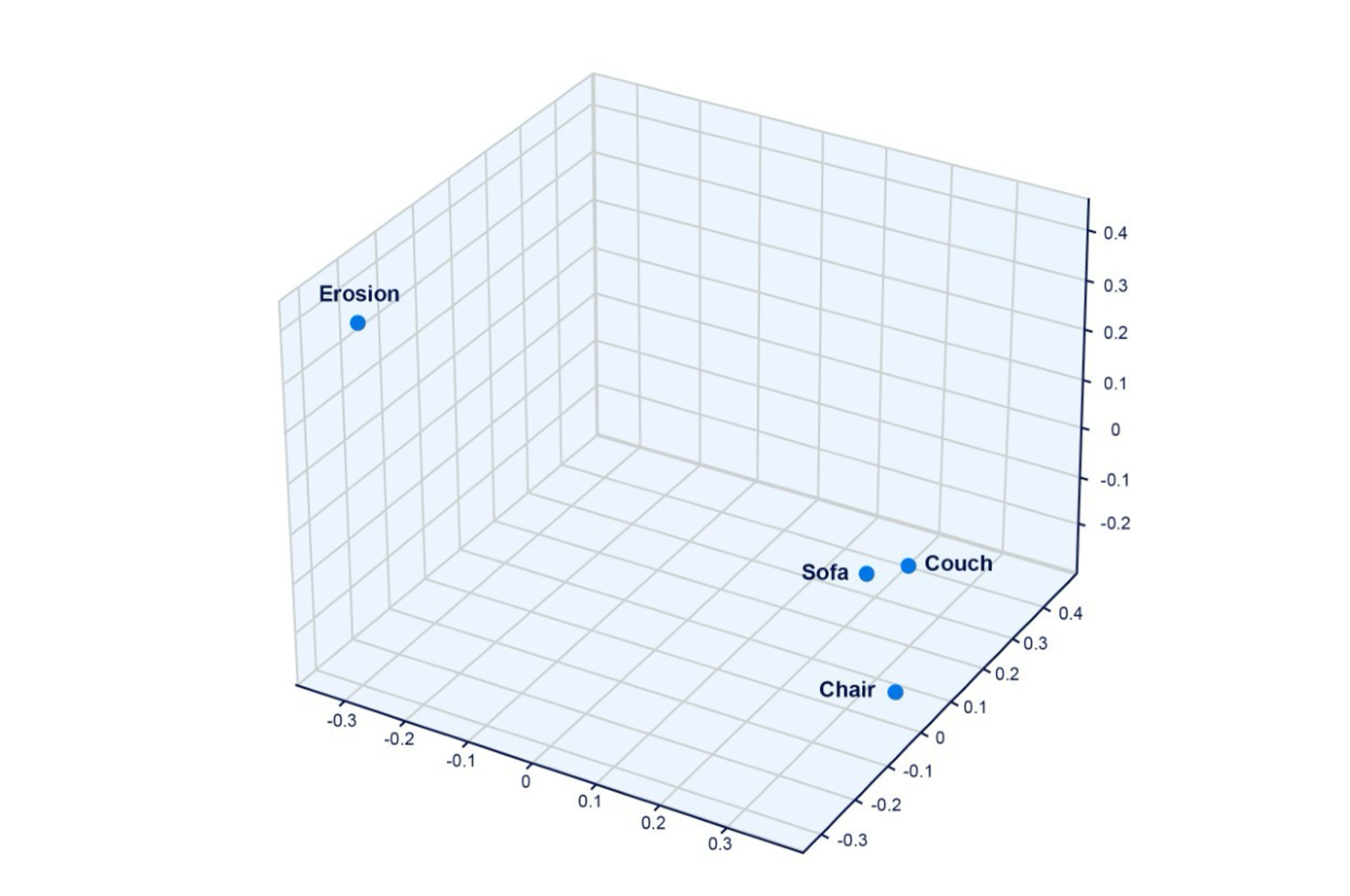
Figure 1: While “Sofa”, “Couch”, and “Chair” are all related, “Sofa” and “Couch” are semantically closer to each other than “Chair” (i.e., they are both designed for multiple people, while a chair is meant for just one).
“Erosion”, on the other hand, shares practically no resemblance to the other vectors, which is why it is geometrically much further away.
When computers search for things, they typically rely on exact matching, text matching, or open searching/object matching. Vector search, on the other hand, works by using these embeddings to search for semantics as opposed to terms, allowing you to get a much closer match in unstructured datasets based on the meaning of the word.
Under the hood we can generate embeddings for our search term, and then using some vector math, find other embeddings that are geometrically close to our search term. This will return results that are semantically related to our search. For example, if we search for “sofa”, then “couch” followed by “chair” will be returned.
How does vector search work with Large Language Models (LLMs)?
Now that we’ve established an understanding of vectors, embeddings, and vector searching, let’s explore the intersection of vector searching and Large Language Models (LLMs), a trending topic within the world of sophisticated AI models.
With Retrieval Augmented Generation (RAG), we use the vectors to look up related text or data from an external source as part of our query, as part of the query we also retrieve the original human readable text. We then feed the original text alongside the original prompt into the LLM for generated text output, allowing the LLM to use the additional provided context while generating the response.
(PGVector does a very similar thing with PostgreSQL; check out our blog where we talk all about it).
By utilizing this approach, we can take known information, query it in a natural language way, and receive relevant responses. Essentially, we input questions, prompts, and data sources into a model and generate informative responses based on that data.
The combination of Vector Search and LLMs opens up exciting possibilities for more efficient and contextually rich GenAI applications powered by Cassandra.
What does this mean for vector search in Cassandra 5.0?
Well, with the additions of CEP-7 (Storage Attached Index, SAI) and CEP-30 (Approximate Nearest Neighbor, ANN Vector Search via SAI + Lucene) to the Cassandra 5.0 release, we can now store vectors and create indexes on them to perform similarity searches. This feature alone broadens the scope of possible Cassandra use cases.
We utilize ANN (or “Approximate Nearest Neighbor”) as the fast and approximate search as opposed to k-NN (or “k-Nearest Neighbor”), which is a slow and exact algorithm of large, high-dimensional data; speed and performance are the priorities.
Just about any application could utilize a vector search feature. Thus, in an existing data model, you would simply add a column of ‘vectors’ (Vectors are 32-bit floats, a new CQL data type that also takes a dimension input parameter). You would then create a vector search index to enable similarity searches on columns containing vectors.
Searching complexity scales linearly with vector dimensions, so it is important to keep in mind vector dimensions and normalization. Ideally, we want normalized vectors (as opposed to vectors of all different sizes) when we look for similarity as it will lead to faster and more ‘correct’ results. With that, we can now filter our data by vector.
Let’s walk through an example CQLSH session to demonstrate the creation, insertion, querying, and the new syntax that comes along with this feature.
1. Create your keyspace
|
1 |
CREATE KEYSPACE catalog WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 3} |
2. Create your table or add a column to an existing table with the vector type (ALTER TABLE)
|
1 2 3 4 |
CREATE TABLE IF NOT EXISTS catalog.products ( product_id text PRIMARY KEY, product_vector VECTOR<float, 3> ); |
*Vector dimension of 3 chosen for simplicity, the dimensions of your vector will be dependent on the vectorization method*
3. Create your custom index with SAI on the vector column to enable ANN search
|
1 |
CREATE CUSTOM INDEX ann_index_for_similar_products ON products(product_vector) USING ‘StorageAttachedIndex’; |
*Your custom index (ann_index_for_similar_products in this case) can be created with your choice of similarity functions: default cosine, dot product, or Euclidean similarity functions. See here*
4. Load vector data using CQL insert
|
1 2 3 4 5 6 |
INSERT INTO catalog.products (product_id, product_vector) VALUES (‘SKU1’, [8, 2.3, 58]); INSERT INTO catalog.products (product_id, product_vector) VALUES (‘SKU3’, [1.2, 3.4, 5.6]); INSERT INTO catalog.products (product_id, product_vector) VALUES (‘SKU5’, [23, 18, 3.9]); |
5. Query the data to perform a similarity search using the new CQL operator
|
1 |
SELECT * FROM catalog.products WHERE product_vector ANN OF [3.4, 7.8, 9.1] limit 1; |
Result:
|
1 2 3 |
product_id | product_vector ---+--------------------------------------------------------- SKU5 | [23, 18, 3.9] |
How can you use vector search?
E-Commerce (for Content Recommendation)
We can start to think about simple e-commerce use cases like when a customer adds a product or service to their cart. You can now have a vector stored with that product, query the ANN algorithm (aka pull your next nearest neighbor(s)/most similar datapoint(s)), and display to that customer ‘similar’ products in ‘real-time.’
The above example data model allows you to store and retrieve products based on their unique product_id. You can also perform queries or analysis based on the vector embeddings, such as finding similar products or generating personalized recommendations. The vector column can store the vector representation of the product, which can be generated using techniques like Word2Vec, Doc2Vec, or other vectorization methods.
In a practical application, you might populate this table with actual product data, including the unique identifier, name, category, and the corresponding vector embeddings for each product. The vector embeddings can be generated elsewhere using machine learning models and then inserted into a C* table.
Content Generation (LLM or Data Augmentation)
What about the real-time, generative AI applications that many companies (old and new) are focusing on today and in the near future?
Well, Cassandra can serve the persistence of vectors for such applications. With this storage, we now have persisted data that can add supplemental context to an LLM query. This is the ‘RAG’ referred to earlier in this piece and enables uses like AI chatbots.
We can think of the ever-popular ChatGPT that tends to hallucinate on anything beyond 2021—its last knowledge update. With VSS on Cassandra, it is possible to augment such an LLM with stored vectors.
Think of the various PDF plugins behind ChatGPT. We can feed the model PDFs, which, at a high level, it then vectorizes and stores in Cassandra (there are more intermediary steps to this) and is then ready to be queried in a natural language way.
Here is a list of just a subset of possible industries/use-cases that can extract the value of a such a feature-add to the Open Source Cassandra project:
- Cybersecurity (Anomaly Detection)
- Ex. Financial Fraud Detection
- Language Processing (Language Translation)
- Digital Marketing (Natural Language Generation)
- Document Management (Document Clustering)
- Data Integration (Entity Matching or Deduplication)
- Image Recognition (Image Similarity Search)
- Ex. Healthcare (Medical Imaging)
- Voice Assistants (Voice and Speech Recognition)
- Customer Support (AI Chatbots)
- Pharmaceutical (Drug Discovery)
Cassandra 5.0 is now available on the Instaclustr Managed Platform. Try out vector search in Cassandra 5.0 and spin up your first cluster for free!