A visual guide to Apache Kafka® Diskless Topics: Finding Zen in the cloud
I’ve been tracking the progress of Apache Kafka “Diskless Topics” for a while now. It’s a topic that sparks curiosity—mostly because the name itself sounds like an oxymoron. How can a topic be diskless? Where does the data go?
With the recent voting on KIP-1150, I decided it was time to dive deep into the architectural changes. There are several related Kafka Improvement Proposals (KIPs) floating around, but KIP-1150 is dependent on KIP-1163 and KIP-1164, and the designs are still in flux. Consider this blog post a “theory” in the true scientific sense: a best-guess model based on current evidence that will almost certainly evolve.
So, let’s explore what Diskless Topics might look like, using a visual approach and a few “Zen” metaphors to make sense of this new paradigm.
Why Kafka is becoming more “Zen”
In previous explorations of Kafka’s Tiered Storage, I used water metaphors. I compared it to pumped hydro storage: active segments stay in the “upper reservoir” (local disk) until they are closed, at which point they are copied down to the “lower reservoir” (remote object storage). If you need to read old data, it gets pumped back up.
Diskless Topics take this water metaphor and refine it into something simpler, more elegant, and distinctly Zen.
Think of a traditional Japanese deer scarer, or shishi-odoshi. You’ve seen them in gardens or movies—a bamboo tube pivoted in the middle. Water trickles into the open end, and for a while, nothing happens. The water accumulates. Eventually, the weight shifts the center of gravity, the tube rotates down and dumps the water out. Then, the empty tube clacks back against a rock, ready to start the cycle again.

Deer scarer from the Cowra Japanese Garden https://en.wikipedia.org/wiki/Cowra_Japanese_Garden_and_Cultural_Centre
(source: Paul Brebner)
This is exactly how Diskless Topics work.
In this new model, the active segment doesn’t sit on a local disk waiting to be copied anywhere. Instead, records are batched in the broker’s memory (the bamboo tube). Once a threshold is reached—either time or size—the batch is written directly to remote object storage (the water is dumped). The remote storage becomes the single source of truth. The local copy? It’s just a cache. It can be discarded without impact because the durability is now handled by the cloud object store.
The problem with default Kafka: Those expensive orange arrows
To understand why we need this Zen approach, we have to look at the costs associated with the default Kafka architecture.
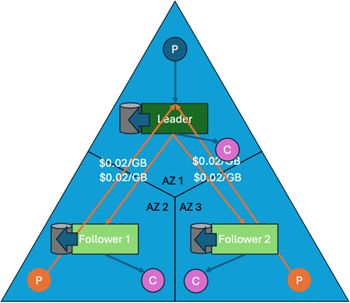
In a standard setup, you have brokers spread across different Availability Zones (AZs) for reliability. If you have a replication factor of 3, every time a producer writes a record to a leader in AZ1, that leader must replicate the data to followers in AZ2 and AZ3.
In cloud environments like AWS, moving data between zones costs money—roughly 2 cents per GB. On architectural diagrams, I draw these as orange arrows. And if you are running a high-throughput cluster, those orange arrows can add up to a significant portion of your monthly bill.
Diskless topics aim to erase those arrows.
Removing replication costs
The first major win with Diskless Topics is the elimination of cross-AZ replication traffic.
Since brokers write directly to object storage, we don’t need to copy data from broker to broker to ensure durability. Cloud object storage is already designed to be highly durable across zones. Once the “deer scarer” dumps its batch into S3 (or equivalent), the data is safe.
So, has the concept of leaders and followers vanished? Not entirely. We still have partition leaders and followers, but their relationship changes. Followers no longer fetch data from the leader for durability. Instead, they fetch data from the remote object storage to populate their local caches. This allows them to serve consumer reads efficiently.
Crucially, because followers read from the shared remote storage, we cut out the broker-to-broker traffic entirely for replication.
Removing producer costs
But wait, there’s more. We still have another set of orange arrows: the producers.
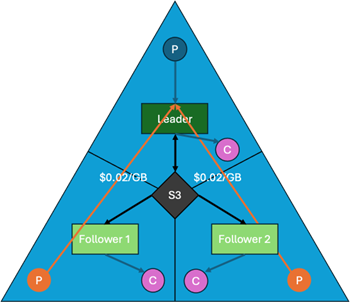
In standard Kafka, a producer must write to the partition leader. If the producer is in AZ1 and the leader is in AZ2, you are paying cross-AZ transfer fees. Diskless Topics solve this with a radical change: Any broker can write to any topic partition.
Yes, you read that right. A producer can send data to the broker closest to it (in the same AZ), and that broker can handle the write to object storage. This means we can effectively eliminate cross-AZ producer traffic as well.
The result? A diagram with no orange arrows. We’ve removed the cross-AZ data traffic for both replication and production.
The complication: The Diskless Coordinator
If this sounds too good to be true, you’re right to be skeptical. Now that every broker has an independent “deer scarer”, our Zen garden is a very noisy place – good for scaring deer, but not for Zen meditation. How can we reclaim our Zen? Can we synchronise our multiple “deer scarers”? In Kafka, if multiple brokers can write to the same partition simultaneously, how do we maintain ordering? Who decides which record comes first?
Enter the Diskless Coordinator.
If the single leader replica is no longer responsible for writes, we need a new way to sequence records. The Diskless Coordinator is a new component responsible for maintaining the metadata and ordering of records. It acts as the global “brain” that keeps all the individual “deer scarers” (brokers) in sync. This coordinator is a distributed system in itself, backed by a special internal topic. It creates a “single source of truth” for the metadata of all objects written to remote storage.
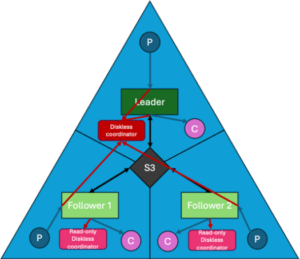
Diskless topics: diskless coordinators handle meta-data for writes, reads and deletes (red arrows).
This is the trade-off. We save massive amounts of money on data transfer costs, but we introduce a new, fairly complex architectural component to manage the state. There will be some metadata traffic between brokers and the coordinator, but this is negligible compared to the volume of actual data payload we used to replicate.
Conclusion: A new era for Kafka?
Diskless Topics represent a significant shift toward a truly cloud-native architecture for Apache Kafka. By leveraging the inherent durability of object storage, we can strip away the redundancy that was previously managed at the application layer.
Here is the quick summary of the trade-offs:
- Pros: Massive reduction in cross-AZ data transfer costs; simplified storage management.
- Cons: Higher latency for writes (since we write to object storage); increased architectural complexity with the Diskless Coordinator.
This proposal is still in the refinement and voting phase. It’s an exciting direction that acknowledges the reality of modern cloud economics. While we probably won’t see production-ready implementations until later in 2026, it’s clear that Kafka is evolving to become more efficient, more scalable, and yes—a little more Zen.
Further reading
The extended version of this blog, with a dive into the original KIPS for diskless, can be found here:
https://www.linkedin.com/feed/update/urn:li:activity:7432275720783060992/
For those who want to dig into the technical details, I highly recommend checking out KIP-1150 on the Apache Kafka wiki, including details contained in KIP-1163 and KIP-1164.