What is Kafka KRaft?
Kafka KRaft is a mode of operation for Apache Kafka that removes the dependency on Apache ZooKeepe™r for managing distributed state. Traditionally, Kafka relied on ZooKeeper for metadata management and controller election. The introduction of KRaft mode represents a significant architectural shift by integrating these responsibilities directly into the Kafka brokers.
This improves system efficiency, reduces complexity, and aligns Kafka closer with cloud-native architectures. By eliminating the need for ZooKeeper, KRaft mode simplifies the deployment and management of Kafka clusters. The improvement reduces operational overhead and minimizes resource usage, enabling easier scaling.
KRaft mode’s integration into the Kafka broker itself promotes improved performance. This mode’s design encourages developers to consider it for new deployments where high availability and simplified architecture are priorities.
This is part of a series of articles about Apache Spark
What is Docker?
Docker is a platform that automates the deployment, scaling, and management of applications using containerization. Containers package application code along with its dependencies, leading to consistency across different development and production environments.
Docker simplifies application deployment by allowing developers to build once and run anywhere, minimizing issues across varying systems configurations. The lightweight nature of Docker containers contributes to their rapid start-up times and efficient resource utilization. This makes Docker an appropriate solution for both microservices and monolithic applications.
Benefits of running Kafka KRaft with Docker
Running Kafka KRaft with Docker combines the advantages of Kafka’s simplified architecture with the flexibility of containerization:
- Simplified deployment: Docker enables quick and consistent deployment of Kafka KRaft by packaging all dependencies into a container. This eliminates manual setup and configuration issues.
- Efficient resource utilization: Containers are lightweight compared to virtual machines, allowing multiple Kafka brokers to run efficiently on the same hardware without unnecessary overhead.
- Scalability and flexibility: With Docker, scaling Kafka KRaft clusters is easier. New brokers can be spun up quickly, and the infrastructure can adapt dynamically to workload changes.
- Portability: Docker ensures that Kafka KRaft runs consistently across different environments, whether on local machines, on-premises servers, or cloud platforms.
- Improved isolation: Each Kafka KRaft container operates independently, reducing conflicts with other applications and simplifying dependency management.
- Faster recovery and rollbacks: If a Kafka node fails, a new one can be deployed rapidly using Docker. Containerized deployments also allow easy rollback to previous stable versions if needed.
By combining Kafka KRaft with Docker, organizations gain a scalable and resilient solution for running Kafka without the complexities of ZooKeeper.
Tips from the expert

Andrew Mills
Senior Solution Architect
Andrew Mills is an industry leader with extensive experience in open source data solutions and a proven track record in integrating and managing Apache Kafka and other event-driven architectures.
In my experience, here are tips that can help you better run Kafka in KRaft mode using Docker:
- Manually generate the KRaft Cluster ID for multi-broker setups: When setting up a multi-node Kafka cluster in KRaft mode, generate a consistent
CLUSTER_IDbefore launching the containers:KAFKA_CLUSTER_ID="$(kafka-storage random-uuid)". Use this ID across all brokers to ensure proper cluster initialization. - Use separate volumes for logs and metadata: Kafka stores both data and metadata in the same directory by default. For better performance and recovery, separate them:
123volumes:- kafka-data:/var/lib/kafka/data- kafka-metadata:/var/lib/kafka/metadata
This helps prevent data corruption in case of failures.
- Limit Kafka’s memory usage inside Docker: Constrain Kafka’s heap size and JVM settings to prevent it from consuming too many resources:
12environment:- KAFKA_HEAP_OPTS="-Xmx2G -Xms2G”
This ensures smooth operation, especially in resource-limited environments.
- Optimize KRaft quorum voters for production deployments: A single-node KRaft setup is fine for testing, but in production, always define a quorum of at least three controllers:
12environment:- KAFKA_CONTROLLER_QUORUM_VOTERS="1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093”
This prevents split-brain scenarios and ensures high availability.
- Automate rolling updates for Kafka containers: If upgrading Kafka versions in a KRaft cluster, use Docker’s rolling update mechanism to avoid downtime:
docker-compose up -d --no-deps --scale kafka=3. Restart brokers one at a time to prevent leader election failures.
Tutorial: Setting up Kafka in KRaft mode using Docker
This tutorial will guide you through setting up Apache Kafka in KRaft mode using Docker.
Prerequisites
Before starting, ensure you have Docker and Docker Compose installed on your machine.
Step 1: Create the Docker Compose file
Create a new directory for your Kafka setup and navigate to it in your terminal. Then, create a docker-compose.yml file and add the following configuration:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
version: '3.8' services: kafka: image: confluentinc/cp-kafka:latest hostname: kafka container_name: kafka ports: - "9092:9092" - "9093:9093" environment: KAFKA_KRAFT_MODE: "true" # Enables KRaft mode. KAFKA_PROCESS_ROLES: controller,broker # Kafka acts as both controller and broker. KAFKA_NODE_ID: 1 # Unique ID for the Kafka instance. KAFKA_CONTROLLER_QUORUM_VOTERS: "1@localhost:9093" # Controller quorum. KAFKA_LISTENERS: PLAINTEXT://localhost:9092,CONTROLLER://localhost:9093 KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092 KAFKA_LOG_DIRS: /var/lib/kafka/data # Log storage location. KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true" # Enables automatic topic creation. KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 # Single replica for simplicity. KAFKA_LOG_RETENTION_HOURS: 168 # Log retention period (7 days). KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 # No rebalance delay. CLUSTER_ID: "Mk3OEYBSD34fcwNTJENDM2Qk" # Unique Kafka cluster ID. volumes: - /var/run/docker.sock:/var/run/docker.sock - ./data:/var/lib/kafka/data # Maps logs to local storage. |
Explanation of the configuration:
KAFKA_KRAFT_MODE: "true"enables KRaft mode, removing the need for ZooKeeper.KAFKA_PROCESS_ROLES: controller,brokerallows Kafka to handle both roles.KAFKA_CONTROLLER_QUORUM_VOTERSsets the voting members for leader election.KAFKA_ADVERTISED_LISTENERSensures external services can connect.KAFKA_LOG_DIRSspecifies where Kafka stores logs.volumesmap the Kafka logs to a local directory, preserving data between restarts.
Step 2: Start Kafka
Once the file is ready, open a terminal, navigate to the directory containing docker-compose.yml, and run:
|
1 |
docker-compose up |
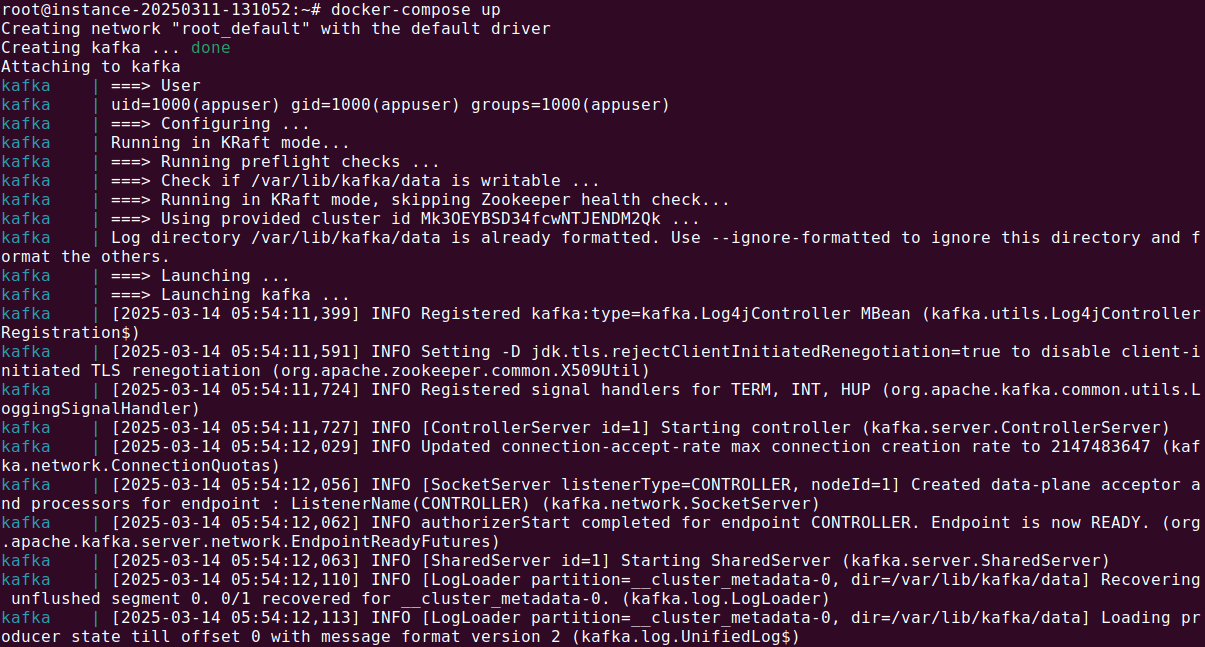
If you encounter any permission related issue for the data folder, please run following commands:
|
1 2 |
sudo chown -R 1000:1000 ./data chmod -R 755 ./data |

This command starts Kafka in KRaft mode, pulling necessary images and configuring the broker.
Testing Kafka: Sending and receiving messages
Step 1: Access the Kafka container
To interact with Kafka, enter the running container:
|
1 |
docker exec -it kafka bash |
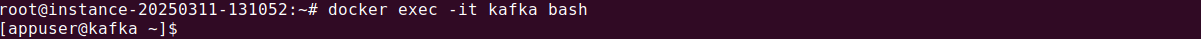
Step 2: Create a Kafka topic
Kafka stores messages in topics. Create a topic named test-topic:
|
1 |
/usr/bin/kafka-topics --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1 |

Step 3: Produce messages
Send messages to Kafka using a producer:
|
1 |
/usr/bin/kafka-console-producer --broker-list localhost:9092 --topic test-topic |
Type messages and press Enter after each:
|
1 2 |
> Hello Kafka! > This message is a test. |

Step 4: Consume messages
Read messages from the topic:
|
1 |
/usr/bin/kafka-console-consumer --bootstrap-server localhost:9092 --topic test-topic --from-beginning |
You should see:
|
1 2 |
Hello Kafka! This message is a test. |

Step 5: List all topics
To check all existing topics:
|
1 |
/usr/bin/kafka-topics --list --bootstrap-server localhost:9092 |
Step 6: Check Kafka logs (optional)
View logs for debugging:
|
1 |
docker logs kafka |
5 Best practices for running Kafka KRaft with Docker
Here are some useful practices to consider when using Kafka KRaft in a containerized environment.
1. Configure environment variables appropriately
Setting the right environment variables is crucial for Kafka KRaft’s stability and performance.
- Cluster ID and Node ID: Assign a unique
CLUSTER_IDfor the Kafka instance and specify aKAFKA_NODE_IDfor each broker to prevent conflicts. - Listener configuration: Define
KAFKA_LISTENERSandKAFKA_ADVERTISED_LISTENERSto ensure Kafka can accept connections both internally and externally. For example:12KAFKA_LISTENERS: PLAINTEXT://localhost:9092,CONTROLLER://localhost:9093KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092 - Controller quorum: In a multi-broker setup, correctly configure
KAFKA_CONTROLLER_QUORUM_VOTERS. If running three brokers, this might look like:1KAFKA_CONTROLLER_QUORUM_VOTERS: "1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093" - Log and topic settings: Adjust
KAFKA_LOG_RETENTION_HOURSto control log retention and setKAFKA_AUTO_CREATE_TOPICS_ENABLEto false in production to prevent unintended topic creation.
Configuring these variables correctly ensures stable cluster operation, proper leader election, and smooth communication between Kafka components.
2. Use official Docker images
Using the official Docker images from Apache Kafka or Confluent ensures security, reliability, and compatibility with the latest features and patches.
Why official images?
- They are maintained by the Kafka community and regularly updated.
- They include necessary dependencies, reducing setup complexity.
- They minimize security vulnerabilities compared to third-party images.
Example of using an official image:
In docker-compose.yml, reference the Confluent Kafka image:
|
1 2 3 |
services: kafka: image: confluentinc/cp-kafka:latest |
Alternatively, for the official Apache Kafka image:
|
1 2 3 |
services: kafka: image: apache/kafka:latest |

Avoid custom builds unless necessary:
If modifications are needed, consider using a Dockerfile that extends the official image rather than building from scratch:
|
1 2 3 |
FROM confluentinc/cp-kafka:latest RUN mkdir -p /opt/custom-config COPY server.properties /opt/custom-config/ |
Using official images ensures compatibility with Kafka’s evolving architecture, including KRaft mode improvements.
3. Persist data using volumes
Kafka relies on persistent storage for logs, metadata, and offsets. Without proper persistence, data can be lost when a container restarts.
Why use volumes?
- Containers are ephemeral, meaning data inside them is lost when they stop or restart.
- Persisting data allows Kafka brokers to recover from crashes without data loss.
- Ensures logs and offsets remain intact across reboots.
How to configure persistent storage in Docker:
In docker-compose.yml, map Kafka’s log directories to a persistent volume:
|
1 2 3 4 5 6 |
services: kafka: volumes: - kafka-data:/var/lib/kafka/data volumes: Kafka-data: |
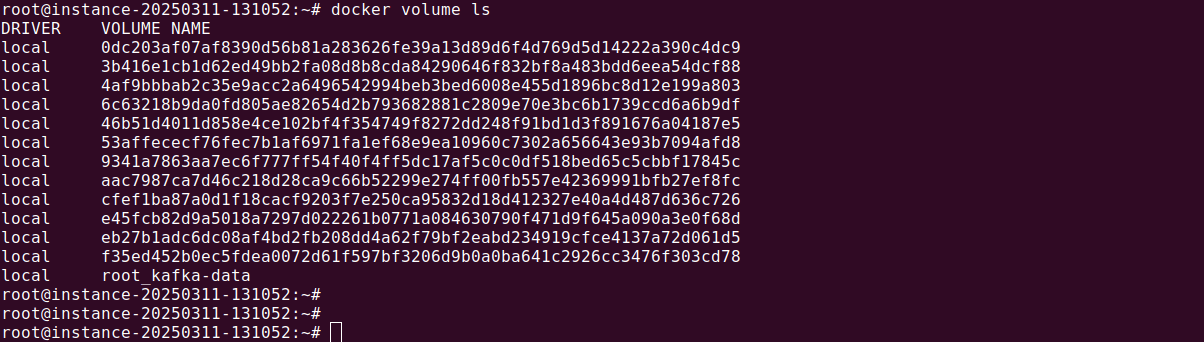
You can run docker volume ls command to verify if volume has been configured:
|
1 |
docker volume ls |
This stores Kafka data outside the container in a named volume. Alternatively, bind-mount a local directory:
|
1 2 3 4 |
services: kafka: volumes: - ./kafka-logs:/var/lib/kafka/data |
This approach is useful for debugging since logs can be inspected outside the container.
Ensure data integrity:
- Place logs on SSDs for better performance.
- Configure log segment and retention settings to balance storage needs.
- In Kubernetes, use Persistent Volumes (PVs) for stateful Kafka deployments.
Persisting data is essential for maintaining a stable and fault-tolerant Kafka cluster.
4. Monitor health with health checks
Monitoring Kafka’s health ensures timely detection of failures and quick recovery. Docker provides built-in mechanisms to check container status.
Why use health checks?
- Prevents Kafka from running in a faulty state.
- Enables automatic restarts on failure.
- Helps in load balancer and orchestration decisions.
Adding a health check in docker-compose.yml:
Define a health check that verifies if Kafka is responding:
|
1 2 3 4 5 6 7 |
services: kafka: healthcheck: test: ["CMD", "kafka-topics", "--list", "--bootstrap-server", "localhost:9092"] interval: 30s retries: 5 timeout: 10s |
This checks if Kafka can list topics every 30 seconds and retries up to 5 times before marking the container as unhealthy.
Using Docker commands to inspect Kafka’s health:
|
1 |
docker inspect --format ‘{{.State.Health.Status}}’ kafka |

Monitoring logs for issues:
Use docker logs to check for startup errors or failures:
|
1 |
docker logs kafka --tail 50 |
If running Kafka in Kubernetes, use liveness and readiness probes to detect issues and restart pods if necessary. Regular health monitoring prevents downtime and ensures smooth Kafka operation.
5. Scale with multiple brokers
Kafka is designed for distributed deployments, and scaling with multiple brokers improves resilience, performance, and fault tolerance.
Why scale Kafka?
- Distributes load across multiple brokers.
- Provides redundancy to prevent data loss in case of failures.
- Improves parallel processing of messages.
How to deploy multiple brokers in Docker Compose”
Modify docker-compose.yml to add more Kafka brokers:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
services: kafka-1: image: confluentinc/cp-kafka:latest container_name: kafka-1 environment: KAFKA_NODE_ID: 1 KAFKA_CONTROLLER_QUORUM_VOTERS: "1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093" KAFKA_LISTENERS: PLAINTEXT://localhost:9092,CONTROLLER://localhost:9093 ports: - "9092:9092" kafka-2: image: confluentinc/cp-kafka:latest container_name: kafka-2 environment: KAFKA_NODE_ID: 2 KAFKA_CONTROLLER_QUORUM_VOTERS: "1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093" KAFKA_LISTENERS: PLAINTEXT://localhost:9094,CONTROLLER://localhost:9095 ports: - "9094:9094" |

Best practices for scaling:
- Ensure each broker has a unique
KAFKA_NODE_ID. - Adjust replication factors
(KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR)to match the number of brokers. - Use Docker networking to enable communication between brokers.
- Load-balance producers and consumers across brokers for better performance.
Exploring Instaclustr for Apache Kafka with KRaft on Docker
Instaclustr for Apache Kafka is a fully managed Kafka service designed to streamline the deployment, maintenance, and scaling of Kafka clusters, optimized for modern, real-time data streaming needs. By leveraging Instaclustr’s expertise, businesses gain the ability to focus on building and managing their data-powered applications without the overhead of infrastructure management complexities. This service ensures high availability, reliability, and performance, supporting enterprises in harnessing the full power of Apache Kafka.
Learn more in our detailed guide to apache spark streaming
One standout feature of Instaclustr’s Kafka offering is its innovative use of KRaft (Kafka Raft) on Docker. KRaft, which is Kafka’s built-in consensus protocol replacing the traditional use of Apache ZooKeeper, simplifies the architecture and enhances reliability.
Instaclustr leverages KRaft to create a cleaner, more efficient cluster management system. By eliminating ZooKeeper, the platform benefits from reduced operational complexity and the ability to achieve unified metadata management while maintaining the robust fault tolerance Kafka is known for.
When paired with Docker, KRaft unlocks even greater agility. Docker’s containerization enables developers to quickly spin up Kafka clusters with KRaft, making it easier to test, deploy, and manage applications in a consistent environment. This combination ensures that clients enjoy seamless scalability and flexibility while maintaining superior data processing capabilities.
Instaclustr optimizes the orchestration and configuration of Dockerized KRaft-based Kafka deployments, ensuring an efficient setup for enterprises to kick off their data streaming projects with confidence.
Whether you’re looking to simplify your Kafka adoption, implement real-time analytics, or integrate event-driven architectures, Instaclustr’s fully managed platform delivers an incredibly robust solution, allowing you to harness Kafka’s potential with cutting-edge tools like KRaft and Docker.