What is an open source vector database platform?
An open source vector database platform refers to a managed vector database solution built on top of one or more open source components, such as Instaclustr, Zilliz Cloud, or Qdrant Cloud. These solutions are based on general purpose open source databases such as PostgreSQL or specialized open source vector databases like Milvus.
These platforms leverage open source infrastructure for data storage, indexing, or query processing. For example, some platforms use PostgreSQL extensions to add vector search capabilities, while others embed open source key-value stores for efficient storage and retrieval of vector embeddings.
By building on proven open source systems, these platforms can offer scalability, stability, and extensibility while focusing their proprietary code on higher-level features like API layers, hybrid search, and performance optimizations tailored to vector workloads.
Key features of vector database platforms
Vector indexing and search
Vector database platforms provide indexing techniques optimized for similarity search in high-dimensional spaces. These include approximate nearest neighbor (ANN) algorithms like HNSW, IVF, and PQ, which speed up retrieval by trading off some accuracy for performance. Platforms built on open source databases often implement these indexing methods as extensions or embedded libraries.
Search capabilities typically support cosine similarity, dot product, or Euclidean distance, allowing efficient comparison of vector embeddings. These features enable use cases such as semantic search, recommendation systems, and image or audio matching, where traditional keyword search is insufficient.
Integration with open source storage engines
Open source vector database platforms rely on underlying storage engines such as PostgreSQL, RocksDB, or SQLite to handle data persistence and low-level operations. By using these mature and well-tested engines, platforms gain reliability and compatibility with existing tooling.
Some platforms integrate at the extension level (e.g., using PostgreSQL’s extension framework), while others embed engines like RocksDB directly for high-performance key-value storage. These integrations allow developers to benefit from familiar infrastructure while adopting vector capabilities.
Hybrid search support
Hybrid search combines traditional structured or full-text queries with vector similarity search. Open source vector database platforms often support hybrid queries natively or via layered extensions, enabling users to filter by metadata (e.g., SQL WHERE clauses) before or after applying vector similarity ranking.
This is especially useful in applications like e-commerce search or document retrieval, where relevance depends on both textual and semantic signals. The ability to perform hybrid search over open source backends ensures flexibility in use cases while maintaining performance.
Scalability and performance tuning
By leveraging open source databases, these platforms inherit built-in scalability features like replication, sharding, and connection pooling. They may also provide tuning options tailored to vector workloads—such as adjusting index parameters, controlling memory usage, or batching vector insertions and queries.
For example, PostgreSQL-based platforms can use parallel query execution and custom memory settings, while RocksDB-based systems can optimize compaction strategies for fast ingestion. These capabilities allow developers to scale with growing data sizes and real-time performance demands.
Extensibility and ecosystem compatibility
Platforms built on open source engines are often easier to integrate with broader data ecosystems. PostgreSQL-based vector databases, for instance, can interoperate with BI tools, ORMs, and SQL-based data pipelines. They also benefit from plugin ecosystems, allowing extensions for new data types, operators, or index methods.
This extensibility makes it easier to embed vector search in existing applications without overhauling the tech stack. Moreover, using open formats and APIs promotes compatibility across data processing and machine learning tools.
Related content: Read our guide to vector database open source
Notable open-source vector database platforms
1. NetApp Instaclustr
![]()
Instaclustr provides a powerful, fully managed platform designed to simplify the complexities of deploying, managing, and scaling vector databases for modern applications. Instaclustr harnesses the full potential of vector data by offering production-ready and secure open source vector solutions like Cassandra, PostgreSQL (with the pgvector), and OpenSearch. Instaclustr handles the operational heavy lifting—from provisioning and security to monitoring and scaling—allowing teams to focus on building innovative AI-powered features, such as semantic search, recommendation engines, and generative AI.
Core vector database capabilities
- Fully Managed Infrastructure: End-to-end management, proactive monitoring, and expert support for vector database environments.
- High Availability and Reliability: Guaranteed uptime SLAs and fault-tolerant architectures that keep mission-critical AI applications running smoothly.
- Seamless Scalability: Scales database clusters up or down with a few clicks to handle fluctuating data volumes and intense query workloads.
- Open Source Commitment: Leverage pure open source data technologies that prevent vendor lock-in and foster complete technological flexibility.
- Enterprise-Grade Security: Protects valuable data with robust security features, including data encryption, private network isolation, and strict role-based access controls.
- AI and ML Readiness: Deploy in optimized environments specifically designed to handle the heavy lifting of high-dimensional vector data and complex similarity searches.

2. Zilliz Cloud
![]()
Zilliz Cloud is a managed vector database platform built on the open source Milvus project. It provides hosted infrastructure for vector storage and similarity search, abstracting cluster management while retaining compatibility with the Milvus ecosystem. The platform focuses on supporting AI-driven applications that rely on large-scale embedding storage and retrieval.
Key features include:
- Built on Milvus: Uses the open source Milvus vector database as its core engine for indexing and similarity search.
- Managed cloud deployment: Provides hosted infrastructure, removing the need to operate and scale clusters manually.
- Vector storage limits in free tier: Supports collections with up to one million 768-dimensional vectors in its entry-level offering.
- Built-in embedding pipeline: Includes integrated text embedding capabilities for generating and storing vectors.
- Integration with AI tooling: Works with frameworks and services such as Hugging Face, LlamaIndex, and OpenAI.
- Multi-language API support: Offers SDKs and access via Python, Node.js, and REST APIs.
Source: Zilliz
{kind=link}
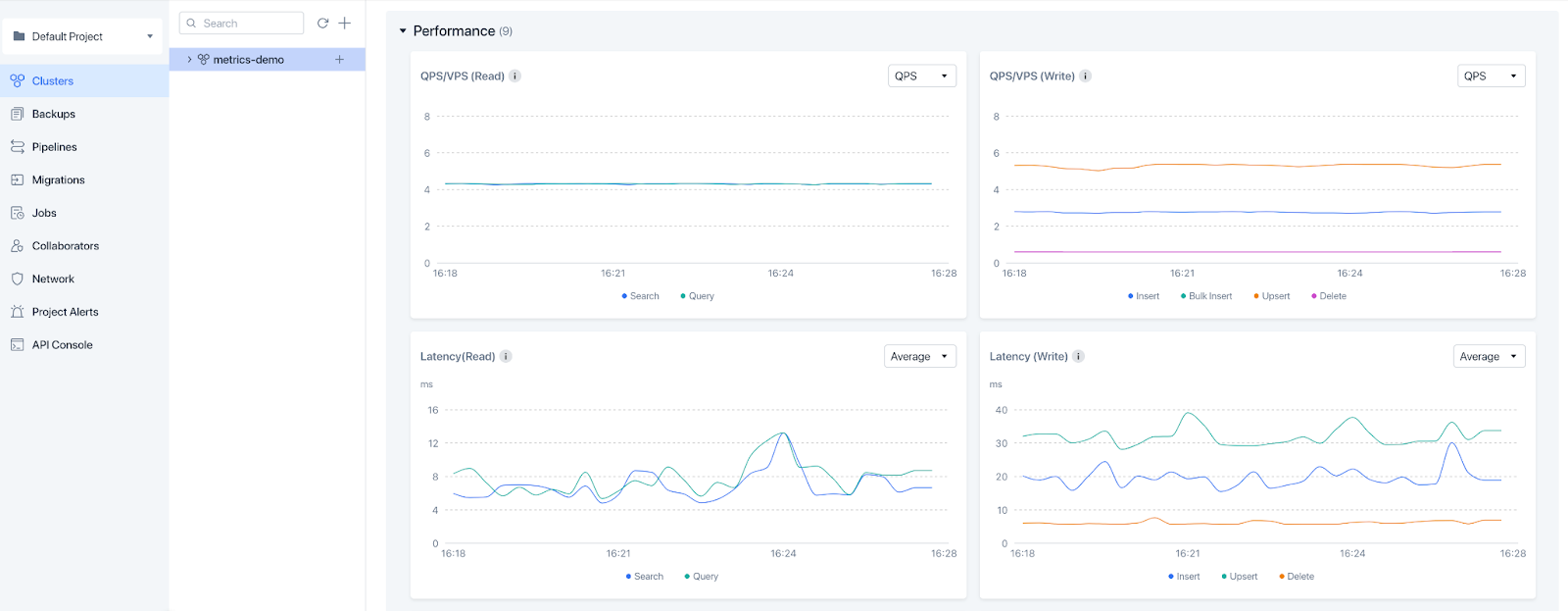
3. Qdrant Cloud
![]()
Qdrant Cloud is the fully managed deployment option for the open source Qdrant vector database. It provides scalable vector search infrastructure with operational features designed for production environments. The service is available across major cloud providers and supports automated cluster management.
Key features include:
- Multi-cloud availability: Deployable on AWS, Google Cloud, and Azure across global regions.
- Rapid cluster provisioning: Enables quick deployment of managed clusters through a cloud console interface.
- Efficient resource management: Includes built-in compression options and disk offloading to reduce memory usage.
- Zero-downtime upgrades: Supports uninterrupted scaling and updates during model or infrastructure changes.
- Automated backups: Provides configurable, continuous backups for data protection and restoration.
- Flexible deployment models: Offers managed cloud, hybrid cloud, and fully on-premise enterprise options.
Source: Qdrant
{kind=link}
4. Weaviate Cloud
![]()
Weaviate Cloud (WCD) is the managed hosting environment for the open source Weaviate database. It delivers the same vector, keyword, and hybrid search capabilities as the core Weaviate project while handling infrastructure, scaling, and operational management. The platform is intended to simplify deployment of AI-driven applications without requiring direct cluster administration.
Key features include:
- Built on Weaviate database: Shares the same open source core, supporting vector, keyword, and hybrid search.
- Fully managed clusters: Handles hosting, scaling, and operational maintenance in the cloud.
- Shared and dedicated deployment models: Offers shared SaaS infrastructure or isolated dedicated instances.
- Automatic scalability: Adjusts capacity based on vector memory and workload requirements in shared environments.
- Compliance-ready options: Dedicated deployments reference enhanced security standards such as SOC II and HIPAA.
- Cluster management tools: Provides UI-based cluster creation, monitoring, status tracking, and updates.
Source: Weaviate
{kind=link}
Considerations for choosing open source vector database platforms
Here are some of the main points that organizations should consider when evaluating vector database platforms.
Scalability and performance
The platform must maintain low-latency search and efficient indexing as the number and dimensionality of vectors increase. Distributed architectures, sharding capabilities, and optimized indexing algorithms (such as HNSW, IVF, or PQ) can greatly impact a platform’s ability to handle billions of vectors with acceptable response times.
Performance metrics like throughput, query latency, and index update speed should align with application needs and expected growth. Some platforms are designed for horizontal scaling across nodes or clusters, enabling organizations to expand resources as workloads grow. It is important to benchmark solutions with real or representative data to ensure the database meets operational requirements under expected loads.
Ease of integration
Integration capabilities are vital for adoption and system extensibility. A good vector database should offer mature APIs (REST, gRPC, or language-specific SDKs), comprehensive documentation, and support for popular programming languages. Integration with upstream and downstream tools (such as machine learning pipelines, ETL systems, and stream processors) simplifies the process of embedding the database into existing workflows.
Pre-built connectors, extensive language bindings, and support for machine learning frameworks (for both ingestion and querying) help reduce development time and operational friction. Community-supported third-party integrations or plug-ins can further accelerate adoption.
Operational complexity
Operational complexity encompasses deployment, configuration, scaling, monitoring, and troubleshooting. Some open source vector databases offer managed services to offload much of this burden, while others require deep technical knowledge to fully customize and optimize deployments.
Simpler deployment processes (dockerized containers, Kubernetes Helm charts, automated install scripts) can accelerate setup, whereas complex networking and tuning requirements may lengthen time to production. Long-term operations require effective monitoring, logging, and alerting capabilities to promptly catch issues and maintain performance. Recovery procedures, backup strategies, and automation tools are other aspects to consider.
Cost and resource trade-offs
Open source software reduces licensing costs but there are still infrastructure and human resource costs to consider. Platforms with efficient resource utilization (CPU, memory, disk) and support for commodity hardware can help minimize operational expenses as datasets grow. Some solutions offer features that reduce storage footprint, like vector quantization or tiered storage, providing trade-offs between accuracy, speed, and cost.
Human resource costs can be significant, especially if deep expertise is needed to deploy, integrate, and maintain the system. Managed cloud offerings or vendor support can help mitigate this but may introduce new costs. Sustainable long-term adoption requires understanding these trade-offs and evaluating the total cost of ownership, not just software price.
Community and ecosystem
An active community and rich ecosystem are valuable when choosing an open source vector database. Strong communities contribute bug fixes, documentation, integrations, and plug-ins, accelerating the platform’s improvement and adoption rate. Robust ecosystems often signal sustained project health, lower risk of abandonment, and ongoing innovation, which benefit users through frequent feature releases and security patches.
The availability of community resources, knowledge bases, forums, and vendor support directly affects how quickly teams can troubleshoot issues or onboard new users. Platforms with extensive partner integrations or rich third-party tooling are easier to adopt and extend within complex data and AI pipelines.
Conclusion
Open source vector database platforms combine proven storage engines with specialized indexing and search capabilities for AI workloads. Managed offerings reduce operational overhead while preserving compatibility with open ecosystems. When selecting a platform, organizations should evaluate scalability, integration requirements, operational complexity, and total cost of ownership to ensure the solution aligns with long-term data and AI strategies.