Look! Up in the sky!
It’s an in-memory key-value store!
It’s a database!
It’s Redis!

Faster than a speeding database!
More powerful than an in-memory key-value store!
Able to leap tall performance barriers at a single bound!
“Yes, it’s Redis—strange visitor from another planet who came to Earth with powers and abilities far beyond those of mortal technologies. Redis—defender of multiple data types, low latency, and high throughput!”
In May 2020 Instaclustr announced a preview release of a managed Redis offering, with a free trial available. Just like the crowd in the above picture who were confused about what they saw, and had problems identifying an unfamiliar fast flying object (which turned out to be Superman), all the fantastic claims about Redis may be initially surprising and hard to accept as well. In this blog I try to answer the questions of what is Redis (really), and how fast does a Redis cluster go!
1. Web Animation: Why You May Need Low Latency
In previous jobs I’ve helped people understand and solve lots of demanding application performance problems (using a combination of monitoring and modeling). I recall one particular customer (a car manufacturer) needed help to reduce the lag in their web-based car configuration application (which allowed customers to create custom builds of their cars and animate them interactively in 3D online).
This type of application needs to deliver consistently high frame rates of at least 60 frames per second (fps) to ensure a smooth interactive user experience. One of the tools we used to gather client-side timing was Google Chrome’s developer mode to record performance for example interactions by a user with the car configurator. This is a very useful tool and records frame rates and operation times including Loading, Scripting, Rendering, Painting, System, etc. Loading is the time for server side events. Here’s a screen shot showing the tool in action on the Maserati car configurator (not the original customer).
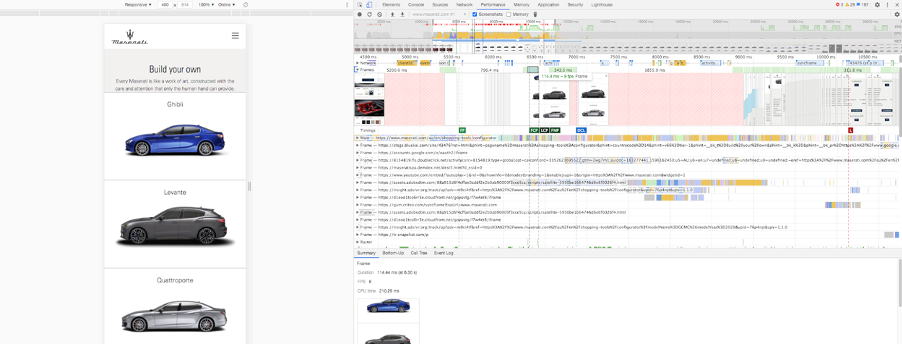
For a smooth frame rate of 60fps, the maximum total time budget (on average) per frame is just 16.7ms. Assuming half of the time is spent on Scripting, Rendering, and Painting etc, this leaves just 8ms for any loading (server side calls including network time, so it’s important for the server to be in the same region as the user). So, time is tight and it’s very easy to go way over this time budget, resulting in frame rate fluctuations such as stuttering, tearing, and janking (which is a new word for me!).
To help keep load times as low as possible an in-memory database can help. Enter Redis!
2. What Really Is Redis?
It took me sometime to work out what Redis really isn’t, and is!
The Redis documentation says what it is not:
“Redis is not a plain key-value store…”
And what it is:
“It is actually a data structures server, supporting different kinds of values.”
So, Redis is a fast in-memory key-value store, where keys are always strings, but the value goes beyond a simple key/value store, it can actually be a number of different data types, with different operations supported on each data type. It’s also distributed (using the cluster mode and supports replication). And it’s got two types of disk persistence (which makes it more like a database), and a caching mode. See the FAQ for more details.
I decided to try Redis out, but first I needed to provision an Instaclustr managed Redis cluster. Here are the instructions on creating a Redis cluster, which only takes a few minutes. The minimum size cluster supported has 3 read/write nodes (which support both read and write operations, and are traditionally called “master” nodes). Redis uses the concept of “slots” to enable keys to be spread over the available nodes. Having more nodes enables the cluster to have higher throughput and more RAM. But if (when!) one of the nodes suffers a catastrophic failure, then the data on that node will be lost (unless you have turned on disk persistence for a “warm restart”).
Securing your data even beyond this is where replica nodes come in. On Instaclustr Redis clusters you can have 0 or more replica nodes. These are just the total number of replica nodes and are distributed among the read/write nodes. It’s best to only have a number of replicas that is a multiple of the read/write nodes, for example, 3, 6, etc. (3 replicas give a replication factor of 2, 6 replicas give a replication factor of 3). If a read/write node fails, then a replica node takes over, so the period of unavailability of the data will be short. For my experiments, I created a cluster with 3 read/write nodes and 3 replica nodes, a total of 6 nodes. The ratio of read/write to replica (read only) nodes will also impact throughput, as all nodes support reads, but only the read/write nodes support writes (although the replicas are written to as well). So, it’s likely that my 6 node cluster will have a higher read than write rate (confirmed below).
You can use the Redis-CLI program to test out Redis, and our customized connection documentation in the console explains how to connect to a cluster once it’s provisioned and running. Just remember that it’s a Redis cluster, so you can’t write to a replica node, and you can only perform multi-key operations if the keys map to the same hash slot (there is a trick to do this using hashtags). There may also be other limitations to watch out for.
Let’s have a closer look at some of the Redis data types and operations using a trivial example. During the COVID-19 lockdown my daily activities have been rather repetitious—something like this:
For day = 1 to n do:
- Wake up
- Drink Coffee
- Eat
- Walk the dog
- Work
- Eat
- Drink Coffee
- Work
- Walk the dog
- Eat
- Play
- Sleep
Your routine may differ (and if you were like me, during the lockdown it was sometimes difficult to cleanly separate work and play). Let’s see how to keep track of my daily schedule using Redis.
3. Redis Strings

Redis Keys are Ideal for Keeping Track of Lots of Strings
For the (simple string) key-value data type Redis allows you to set, get, delete, and increment arbitrary string <key, value> pairs. You can only have 1 value at a time for each key (i.e. set is destructive assignment). You can also delete keys. For example:
> set myday work
OK
> get myday
"work"
> set myday play
OK
> get myday
"play"
> del myday
(integer) 1
> get myday
(nil)
> set myday work
OK
> get myday
"work"Oddly, Redis doesn’t seem to have any concept of scoping and namespaces. All the keys are just in one big keyspace! However, there are 16 numbered databases. and you can use “convention” to mimic namespaces (sort of). For example, name all your keys “namespace/key” or similar. You can then use pattern matching to delete or find (DEL, KEYS) keys in the convention based namespace (oddly the docs don’t say DEL works with patterns, but it works for me). Some Redis clients (you will need a Redis client to actually use Redis for any real programming problem) also help with this. This is the list of key operations, and the strings operations.
Atomic Increment on Strings
Redis can also pretend that string values are numbers, and use them for counting:
> set lockdowndays 149
OK
> get lockdowndays
"149"
> incr lockdowndays
(integer) 150
> get lockdowndays
"150"Note that Redis really supports arbitrary data types as keys and values, not just strings, via the use of clients that support serialization/deserialization to/from strings and other data types and objects.
4. Redis Lists
“He’s got ’em on the list—he’s got ’em on the list;
And they’ll none of ’em be missed—they’ll none of ’em be missed”
[I’ve Got a Little List, Gilbert and Sullivan]
In Redis you can also have lists as the value, which overcomes the problem of having more than one value for a key, as you can have an ordered list with multiple values (so “they’ll none of ‘em be missed”). Lists support most typical list operations that you can think of. You and you can push and pop elements off the left and right (the newest element in on the “right” of the list, and oldest on the “left”, so you can use lists to model either queues or stacks using rpush/rpop or lpush/lpop).
Here’s my daily lockdown schedule. First I need to get up.
> rpush myschedule "get up"
(integer) 1
> get myschedule
(error) WRONGTYPE Operation against a key holding the wrong kind of value
> type myschedule
"list"As you can see, I got an error when I tried to “get” myschedule, as “get” is not an operation supported by lists! You can discover the type of a key using the “type” command. Let’s add some more activities, after each rpush operation Redis responds with the number of elements in the list.
> rpush myschedule "drink coffee"
(integer) 2
> rpush myschedule "eat"
(integer) 3
> rpush myschedule "walk dog"
(integer) 4
> rpush myschedule "work"
(integer) 5
> rpush myschedule "eat"
(integer) 6
> rpush myschedule "drink coffee"
(integer) 7
> rpush myschedule "work"
(integer) 8
> rpush myschedule "walk dog"
(integer) 9
> rpush myschedule "eat"
(integer) 10
> rpush myschedule "play"
(integer) 11
> rpush myschedule "sleep"
(integer) 12
> lrange myschedule 0 12
1) "get up"
2) "drink coffee"
3) "eat"
4) "walk dog"
5) "work"
6) "eat"
7) "drink coffee"
8) "work"
9) "walk dog"
10) "eat"
11) "play"
12) "sleep"
> lrange myschedule 0 -1
1) "get up"
2) "drink coffee"
3) "eat"
4) "walk dog"
5) "work"
6) "eat"
7) "drink coffee"
8) "work"
9) "walk dog"
10) "eat"
11) "play"
12) "sleep"You can use a range of 0 to -1 (the last element) instead of 0 to the list size to get all the elements. And to step through all the activities in order (destructively) we can use the lpop command.
> lpop myschedule
"get up"
> lpop myschedule
"drink coffee"
> lpop myschedule
"eat"
> lpop myschedule
"walk dog"
> lpop myschedule
"work"
> lpop myschedule
"eat"
> lpop myschedule
"drink coffee"
> lpop myschedule
"work"
> lpop myschedule
"walk dog"
> lpop myschedule
"eat"
> lpop myschedule
"play"
> lpop myschedule
"sleep"
> lpop myschedule
(nil)As you can see, this really is an ordered list: there’s an order, and some values occur multiple times. What happens when you can’t remember what keys you have created? You can use the “keys” command to list all the keys (which could be a lot, but you can also use patterns to find keys within a “namespace” defined using a convention, e.g. “schedules/myday”, etc.):
> keys *
1) "lockdowndays"
2) "myday"Where has myschedule key gone? Redis automatically deletes a key if it has no values, as it automatically creates a key if it doesn’t exist.
And here’s a simple stack example (where we want to pop the elements in the reverse order of pushing them):
5. Redis Hashes
Things get a bit more complicated with Redis hashes, allowing a value to be a hash map, which allows you to have multiple <key, value> pairs as the value of a key, supported by a full set of hash operations. In this example we’ll use a time string as the key and the activity as the value:
> hset myschedule 7am "get up"
(integer) 1
> hset myschedule 8am "drink coffee"
(integer) 1
> hset myschedule 9am "eat"
(integer) 1
> hset myschedule 10am "walk dog"
(integer) 1
> hset myschedule 11am "work"
(integer) 1
> hset myschedule 1pm "eat"
(integer) 1
> hset myschedule 2pm "drink coffee"
(integer) 1
> hset myschedule 3pm "work"
(integer) 1
> hset myschedule 7pm "walk dog"
(integer) 1
> hset myschedule 8pm "eat"
(integer) 1
> hset myschedule 9pm "play"
(integer) 1
> hset myschedule 11pm "sleep"
(integer) 1
> hkeys myschedule
1) "7am"
2) "8am"
3) "9am"
4) "10am"
5) "11am"
6) "1pm"
7) "2pm"
8) "3pm"
9) "7pm"
10) "8pm"
11) "9pm"
12) "11pm"
> hget myschedule 1pm
"eat"
Note that the elements are accidentally in order (as hashes are really unordered), and that you can only have one value for each hash key. For example, replacing the 1pm activity (“eat”) with “play”:
> hset myschedule 1pm "play"
(integer) 0
> hget myschedule 1pm
"play"
6. Redis Sets

A Complete Set of Canopic Jars (Wikimedia)
Redis has unordered sets. Here’s the set of set operations. Being a set each value can only occur once. Adding all of the daily activities to the myactivities set results in a set with only the 7 unique activities in it as follows:
> sadd myactivities "get up"
(integer) 1
> sadd myactivities "drink coffee"
(integer) 1
> sadd myactivities "eat"
(integer) 1
> sadd myactivities "walk dog"
(integer) 1
> sadd myactivities "work"
(integer) 1
> sadd myactivities "eat"
(integer) 0
> sadd myactivities "drink coffee"
(integer) 0
> sadd myactivities "work"
(integer) 0
> sadd myactivities "walk dog"
(integer) 0
> sadd myactivities "eat"
(integer) 0
> sadd myactivities "play"
(integer) 1
> sadd myactivities "sleep"
(integer) 1
> smembers myactivities
1) "eat"
2) "work"
3) "drink coffee"
4) "walk dog"
5) "get up"
6) "sleep"
7) "play"
Notice that the order is random, as this is an unordered set. You can also check if something is a member of the set (1 is true, 0 is false):
> sismember myactivities work
(integer) 1
> sismember myactivities read
(integer) 0
Sets support all the expected set operations including union, intersection, and difference. In this example we’ll create a copy of the myactivities set to represent weekend activities (using the sunionstore command to union the myactivities set with itself and make a copy, weekendactivities), and then delete “work” and add “gardening”:
> sunionstore weekendactivities myactivities myactivities
7
> smembers weekendactivities
1) "eat"
2) "work"
3) "drink coffee"
4) "walk dog"
5) "get up"
6) "play"
7) "sleep"
> srem weekendactivities work
1
> smembers weekendactivities
1) "eat"
2) "drink coffee"
3) "walk dog"
4) "get up"
5) "play"
6) "sleep"
> sadd weekendactivities gardening
(integer) 1
> smembers weekendactivities
1) "eat"
2) "drink coffee"
3) "walk dog"
4) "gardening"
5) "get up"
6) "play"
7) "sleep"
> sunion myactivities weekendactivities
1) "drink coffee"
2) "walk dog"
3) "gardening"
4) "get up"
5) "play"
6) "sleep"
7) "eat"
8) "work"
> sinter myactivities weekendactivities
1) "eat"
2) "drink coffee"
3) "walk dog"
4) "get up"
5) "sleep"
6) "play"
> sdiff myactivities weekendactivities
1) "work"
> sdiff weekendactivities myactivities
1) "gardening"The last 4 operations show that the union of the two sets is indeed all of my weekly activities (including work and gardening), the intersection is everything excluding work and gardening (as they don’t occur in both sets), and the difference (depending on which set is first) is “work” or “gardening” (i.e. which elements of the 1st set do not appear in the 2nd set). Note that there’s no limit to the number of sets for the set operations.
How well does set intersection work on larger sets? Probably not super fast given that the docs say:
Time complexity: O(N*M) worst case where N is the cardinality of the smallest set and M is the number of sets.
Union and Diff will be faster as they are O(N). Also I suspect that because Redis is single threaded, a command that takes a long time will block other commands from running. Let’s try and see.
But first, how to create two large sets? I used a couple of Lua scripts (which are fast as they run directly on a Redis node) as follows:
File set1.lua:
for i = 0, 10000000, 1 do
redis.call("sadd", "{a}a", i)
end
return "Created set1"
File set2.lua:
for i = 10000000, 20000000, 1 do
redis.call("sadd", "{a}b", i)
end
return “Created set2"
Lua scripts are run using the redis-cli as follows:
redis-cli -a “password” -h “host” --eval set1.lua
redis-cli -a “password” -h “host” --eval set2.luaBecause multi-key commands can only be run on a single node, and I was using a Redis cluster, I used the hash tags trick. Only the string between the “{}” is hashed to obtain the slot, so both sets are forced to be on the same slot.
Once the scripts have created the sets I used redis-cli as follows:
> scard {a}a
(integer) 10000001
> scard {a}b
(integer) 10000001
> sinter {a}a {a}b
1) "10000000"
(112.33s)Each set has 10 million (and 1) elements, and it took 112 seconds to find the intersection, a single element, so use with caution! Of course, smaller sets (and if one set is smaller than the other) are faster, for example, “sinter” between sets with 1 million elements only takes 800ms.
7. Redis Sorted Sets
Animals Species Sorted by Body and Brain Weights (Wikipedia)
Typically sets are unordered, but Redis has sorted sets, where every value in the set has a score (a floating point number), and order is computed as follows:
- If A and B are two elements with a different score, then A > B if A.score is > B.score.
- If A and B have exactly the same score, then A > B if the A string is lexicographically greater than the B string. A and B strings can’t be equal since sorted sets only have unique elements.
All the sorted sets commands are here. You use the zadd command to add elements to a sorted set with a score as follows. In this example I computed the total number of times each activity occurs in a normal 7 day week and use that as the score, so we can determine which activities are most common:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
> zadd rankactivities 7 "get up" (integer) 1 > zadd rankactivities 14 "drink coffee" (integer) 1 > zadd rankactivities 21 "eat" (integer) 1 > zadd rankactivities 14 "walk dog" (integer) 1 > zadd rankactivities 10 "work" (integer) 1 > zadd rankactivities 2 "gardening" (integer) 1 > zadd rankactivities 7 "play" (integer) 1 > zadd rankactivities 7 "sleep" (integer) 1 |
And the zrange command returns the elements in reverse score order (i.e. lowest score first):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
> zrange rankactivities 0 -1 1) "gardening" 2) "get up" 3) "play" 4) "sleep" 5) "work" 6) "drink coffee" 7) "walk dog" 8) "eat" > zrange rankactivities 0 -1 withscores 1) "gardening" 2) 2.0 3) "get up" 4) 7.0 5) "play" 6) 7.0 7) "sleep" 8) 7.0 9) "work" 10) 10.0 11) "drink coffee" 12) 14.0 13) "walk dog" 14) 14.0 15) "eat" 16) 21.0 > zrevrange rankactivities 0 -1 1) "eat" 2) "walk dog" 3) "drink coffee" 4) "work" 5) "sleep" 6) "play" 7) "get up" 8) "gardening" |
Remembering that this is a sorted set, if we assume it’s now a holiday we can replace the scores for play and work and get a new rank (you can also increment the scores with the zincrby command):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
> zadd rankactivities 100 "play" (integer) 0 > zadd rankactivities 0 "work" (integer) 0 > zrevrange rankactivities 0 -1 1) "play" 2) "eat" 3) "walk dog" 4) "drink coffee" 5) "sleep" 6) "get up" 7) "gardening" 8) "work" |
Note that we have to use the zrevrange command to get the rank in a sensible order, if we want the highest scored elements to be returned first.
To achieve the same results we could increment each activity by 1 every time they appear in a work day as follows (and repeat for every work day and weekend day for 7 days):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
> del rankactivities (integer) 1 > zincrby rankactivities 1 "get up" 1.0 > zincrby rankactivities 1 "drink coffee" 1.0 > zincrby rankactivities 1 "eat" 1.0 > zincrby rankactivities 1 "walk dog" 1.0 > zincrby rankactivities 1 "work" 1.0 > zincrby rankactivities 1 "eat" 2.0 > zincrby rankactivities 1 "drink coffee" 2.0 > zincrby rankactivities 1 "work" 2.0 > zincrby rankactivities 1 "walk dog" 2.0 > zincrby rankactivities 1 "eat" 3.0 > zincrby rankactivities 1 "play" 1.0 > zincrby rankactivities 1 "sleep" 1.0 > zrevrange rankactivities 0 -1 withscores 1) "eat" 2) 3.0 3) "work" 4) 2.0 5) "walk dog" 6) 2.0 7) "drink coffee" 8) 2.0 9) "sleep" 10) 1.0 11) "play" 12) 1.0 13) "get up" 14) 1.0 |
8. Redis HyperLogLogs
A Hyper-what-what?! HyperLogLogs were invented to solve a problem I didn’t even know existed – counting! Surely counting is easy, 1, 2, 3, etc.?

Approximate Counting in Hide and Seek: “one, two, skip a few, ninety-nine, one hundred”
Well, yes and no. Evidently it’s difficult to determine the cardinality of very large sets unless you remember all the elements. With similar operations to sets, HyperLogLogs are a probabilistic way of estimating the cardinality of sets with high cardinality. They are different to sets in that they don’t actually store the values, but estimate them using “black magic” (there’s a whole family of papers and estimation algorithms stretching back to the 1980’s). Unlike Sets, there are only 3 operations on them, as you can’t get the elements back (as they are not stored). This examples shows how we can count the number of distinct activities in a day:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
> pfadd countactivities "get up" > pfadd countactivities "drink coffee" > pfadd countactivities "eat" > pfadd countactivities "walk dog" > pfadd countactivities "work" > pfadd countactivities "eat" > pfadd countactivities "drink coffee" > pfadd countactivities "work" > pfadd countactivities "walk dog" > pfadd countactivities "eat" > pfadd countactivities "play" > pfadd countactivities "sleep" > pfcount countactivities (integer) 7 |
This time we got lucky, as pfcount only returns the approximate cardinality (typically <= 2% error). Is it useful? Yes, for when you need to count lots of things (and can’t afford the memory to keep track of each one) but don’t care what they were after counting them. For example, there are plenty of examples in the web and social media such as estimating the number of likes for a post, distinct visitors to a web page, etc. This is one of the simplest explanations I’ve found and uses the simplification of coin tossing—you can estimate the number of count tosses purely by keeping track of the maximum number of heads in a row! Clever!
9. What Else Can Redis Do?
This isn’t an exhaustive list of Redis data types or operations, you can also use Redis for streaming and PubSub applications, bitmaps (which are actually just bit operations on strings, fast and good for saving space), and geospatial operations.
What can you do with all these different data types? Well, I thought of some typical use cases, and sure enough, Redis can do them (with a bit of hacking perhaps). For example, time series data (using sorted sets), queries, and indexing (out of the box Redis only supports primary key indexing, but you can add compound indexing using lists and sets).
So to revisit the initial quote it seems to me that Redis can also be viewed as a tool to build many different custom types of data server, which makes it more like a (distributed) programming language, than a traditional database.
10. How Fast Is Redis?
I was curious to see approximately how fast a Redis cluster was, so I used the default Redis benchmark, redis-benchmark. The Redis benchmark requires some tuning to get sensible results. For example, you can (and should) change the defaults for the number of requests (-n), number of clients (-c), number of requests in the pipeline (-P), and the keyspace (-k). Other options include the data size (-d), throughput or response times (-q), and which tests to run (-t). I focused on sets and gets.
The first observation is that with only a few clients running, the latency is low. All operations (including PING) had 98% < 1ms latency, at 2,000 operations per second throughput. So, it’s pretty obvious that the network is the main contributor to round trip latency, rather than the actual operations (which are logically very fast being in-memory).
10.1. Redis Pipeline Tuning
In order to increase the load I also wanted to better understand the impact of clients and pipeline values. Clients are just the number of threads, but what is Redis pipelining exactly? Due to the overhead of the network round trip time (RTT), and the use of request-response TCP protocol, by default each operation is sent to the server, processed, and the answer sent back, meaning that the RTT will dominate the latency. To speed things up Redis allows multiple operations to be in flight at once.
Running a single process of the benchmark, connected to one node only, and generating a get load only, here are the results of systematically trying permutations of clients and pipelines from 1 to 10,000 (the maximum clients I could achieve was 1,000 due to “too many sockets” open errors). The first graph shows clients/pipelines vs gets/s throughput and clearly shows a increasing trend up to a maximum of 1,000 pipelines (but decreasing with more), with a maximum throughput of around 1 Million get/s with 1,000 pipelines for 10, 100, and 1000 clients (but noting that 1,000 pipelines may be impractical for a real application):
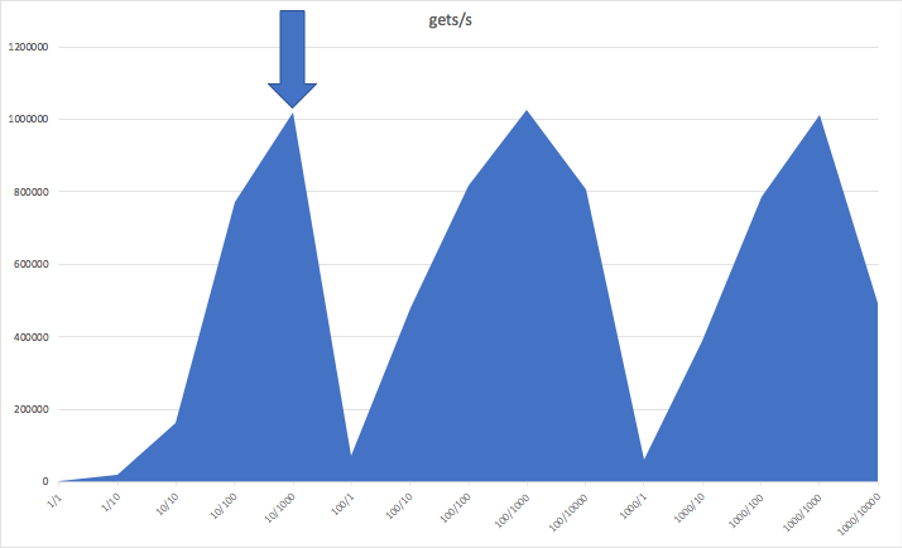
But how about latency? This next graph clearly shows a trend of increasing latency with pipelines, but the peak increases with increasing clients. The optimal configuration is 10 clients with 1000 pipelines giving 1 Million get/s with a 98% latency <= 8ms (corresponding to the first peak in each sawtooth in each graph).
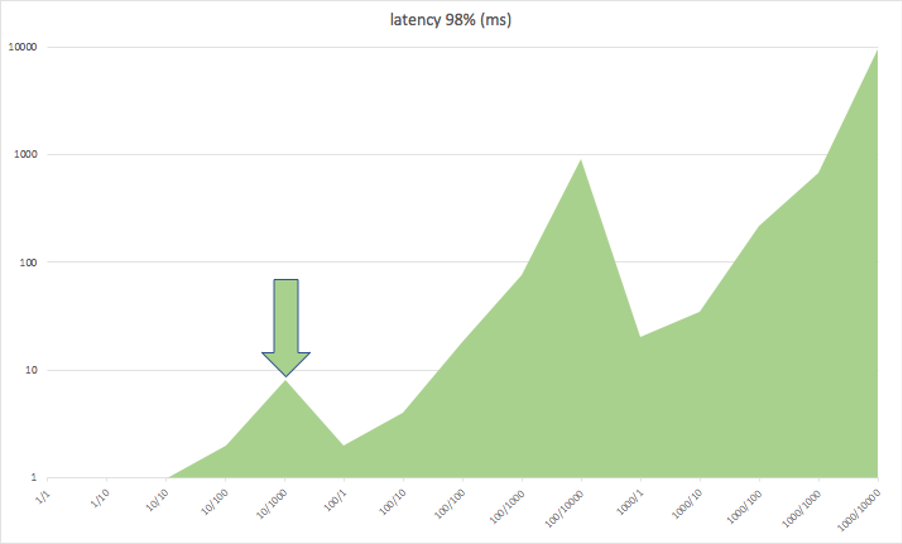
The following graphs show more extensive results for throughput and latency for 10 clients with increasing pipelines. The latency is under 15ms until 10,000 pipelines, and then rapidly rises. On the other hand, there’s only around 20% increase in throughput above 1,000 pipelines, so it’s better to keep the pipelines lower to ensure low latency.
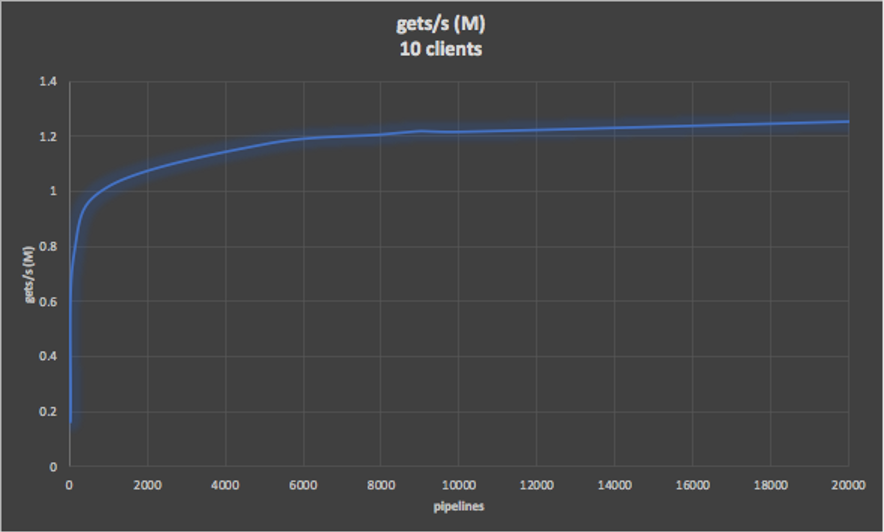
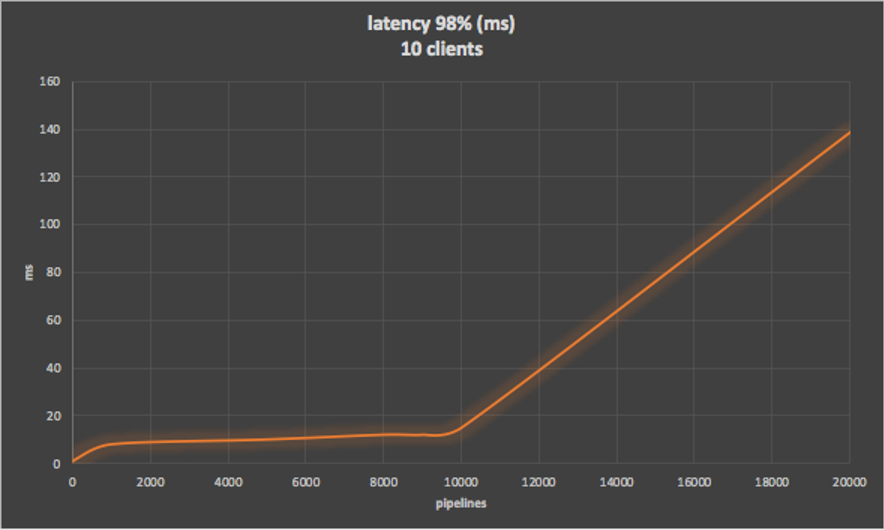
10.2. Redis Cluster Throughput and Latency
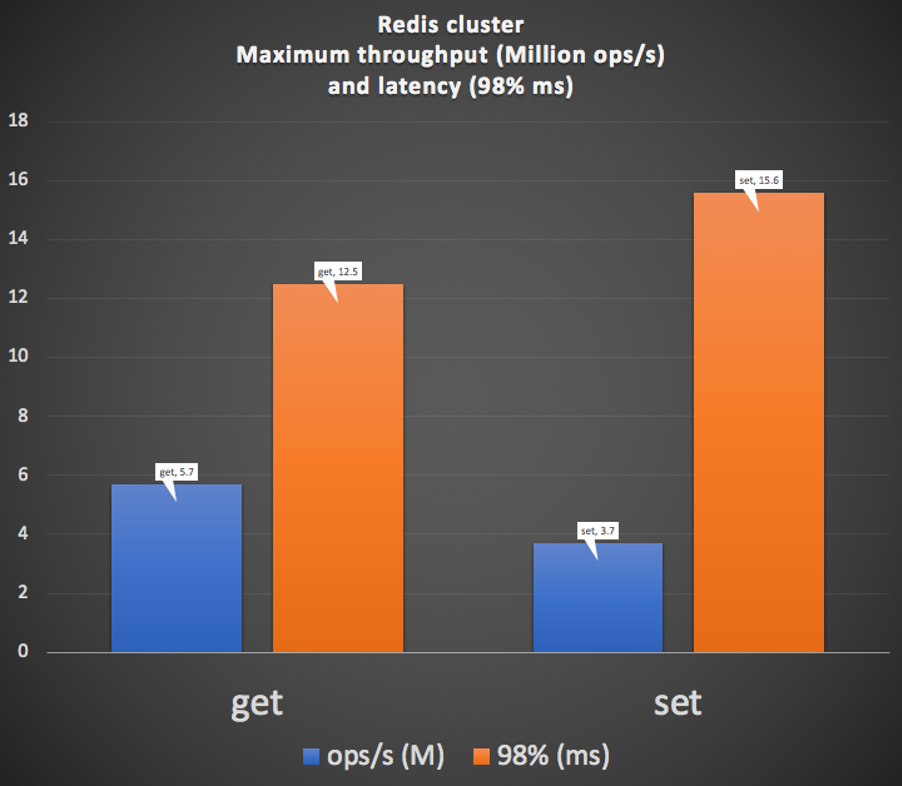
I now scaled up the benchmark to see what the maximum capacity of the six node Redis cluster was. Running six independent benchmark processes with 10 clients and a pipeline of 1,000 each resulted in a maximum throughput for the Redis cluster of 5.7M gets/s, and 3.7M sets/s, and a 98% latency of 12.5ms for gets and 15.6ms for sets, as shown in this graph. Given that the cluster has 3 “master” nodes (read and write nodes) and 3 replicas (read only), the higher get rate makes sense (i.e. all nodes support reads, and master and replica nodes are used for each write). All cluster nodes were around 70% CPU utilization for these results.
I tried t3a.2xlarge and r5.2xlarge (8 core) EC2 instances to run the benchmark (< 20% CPU utilisation), and I tried two different instance sizes for the Redis cluster, t3.small and r5.large instances (2 cores), with comparable results (although in a longer test, the t3 would probably run out of CPU credits). Redis is single threaded on each node, so the only reason to use Redis instances with more than 2 cores is to increase the available RAM, but this can also be achieved by increasing the number of nodes in the cluster.
During the course of this blog I realized that to actually use Redis you need to know three things
- What can Redis do? (hopefully, we covered enough of the basics of this in the blog to get started)
- How Redis clustering and the managed Redis service works (e.g. see Redis documentation), and
- Finally how Redis clients for specific programming languages work.
So, in the next Redis blog, we’ll take a look at some Java Redis clients and try out client-side caching.
Interested in Managed Redis?