The workflow management ecosystem is heating up in popularity, and developers are starting to ask themselves which solution is the best for them.
In this article we will take a high-level look at two of these technologies: Apache Airflow and Cadence, and we’ll explore what makes them tick and perhaps find out which one might be right for you.
What Is Apache Airflow?
Apache Airflow is a workflow management solution that grew out of Airbnb. The creators of Airflow were managing more complex and diverse workflows and looked around the market to find solutions that would help simplify their lives, and when nothing appropriate was found, they built one themselves.
From the outset, Airflow has been an open source project and in 2016 entered Apache Incubator and over time has finally evolved into what it is today: a mature, widely used workflow management solution.
Apache Airflow allows users to develop a workflow definition, a DAG – Directed Acyclic Graph, which are written as Python configuration files.
Airflow is written in Python.
What Is Cadence?
Cadence is a fault-oblivious stateful code platform and workflow engine, and has similar origins to Apache Airflow. It grew out of the Uber engineering team to help service the enormous growth that company has experienced over the years.
Cadence is completely open source, and the Cadence team at Uber announced long term support for Cadence in the coming years, and the developer community is growing.
Cadence workflows are developed as imperative code using the Cadence client SDK, which supports Java and Go natively, and Python and Ruby via third party projects.
Cadence is written in Go.
Instaclustr offers a Managed Cadence service, which takes the hassle out of setting up and maintaining a cluster.
Airflow Architecture
An Apache Airflow cluster can be configured in multiple different ways, but large scale deployments are most commonly deployed as a collection of running applications
1. Apache Airflow
Airflow itself has multiple component services
a. Scheduler service – Responsible for polling the meta store for registered DAGs and queueing them for execution if required
b. Web Server – A HTTP user interface giving users the ability to interact with their workflows.
c. Executor server – Perform the work defined in the DAGs, execute the logic and return the results.
2. Metastore
A SQL database that stores the DAG files. Postgres, MySQL & SQLite supported.
3. Queuing service
Airflow uses the Celery asynchronous task queue as a distributed executor, and it requires a back end be configured. RabbitMQ and Redis are supported.
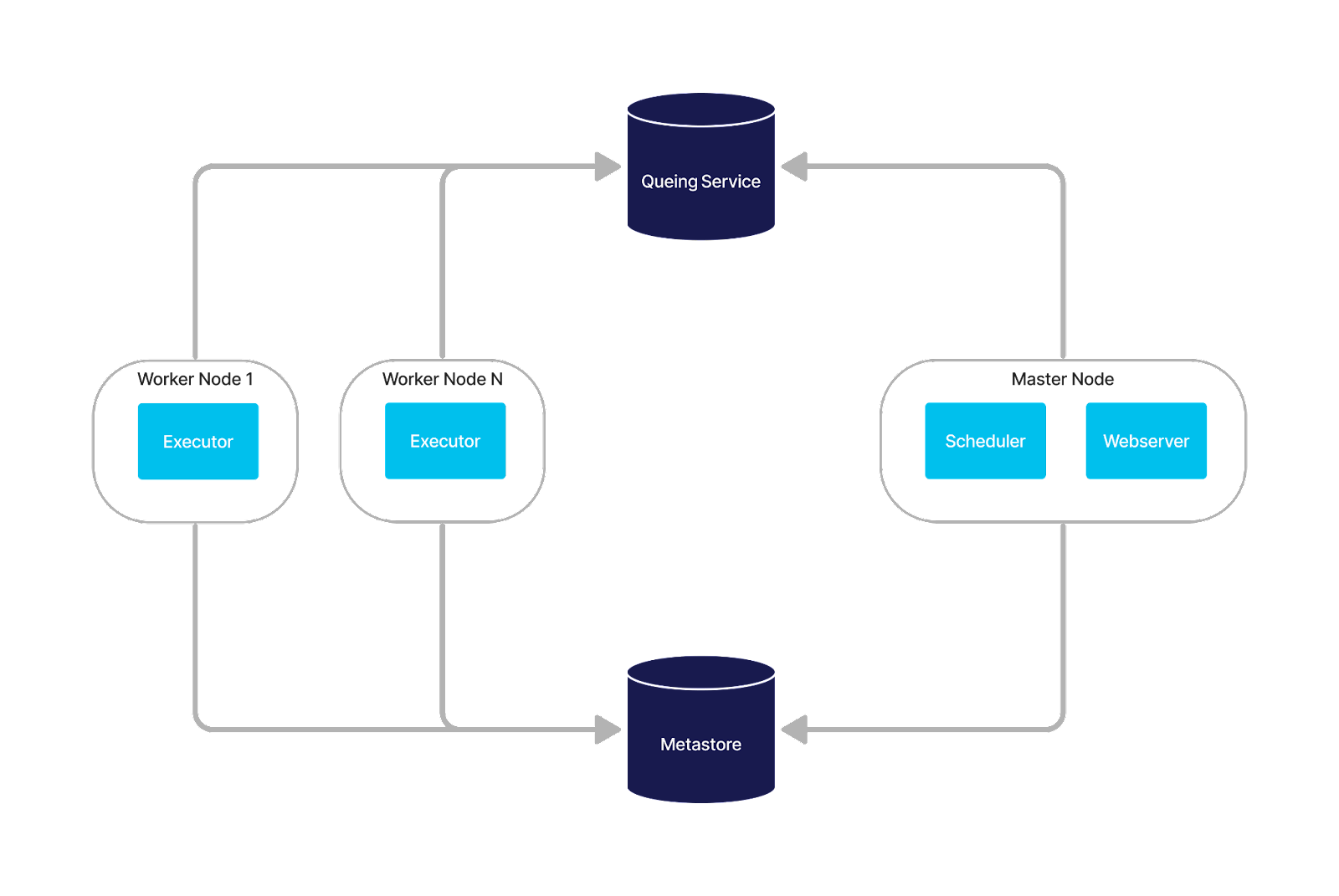
Control Flow
Airflow workflow definitions, or DAGs, are expressed as a collection of tasks. The tasks are configured with explicit dependencies, and can be set up to execute in parallel or obey a strict order.
DAGs are submitted to Airflow and stored in the metastore.
It is the job of the scheduler to check all the known DAGs, and schedule the workflow tasks that are due to be executed.
The task is queued, and the subscribed executor workers execute whatever task they are assigned. The executors run the Python code in the task, and return the result.
User Interface
Airflow offers a user interface, where a user can view DAG definitions, visualise the workflow tasks, see running workflows and get a detailed view of particular workflows.
Airflow Use Cases
Airflow is commonly implemented as a data pipelining service. Use cases include ETL jobs (Extract, Transform, Load) and data consolidation jobs that run on a periodic schedule.
Airflow is a popular tool in machine learning where it is used to build and validate training data for AI models.
Airflow Pros and Cons
Airflow is a widely used and mature application, with a healthy third party provider support ecosystem.
As it’s written in Python, users have access to any of the libraries they need to implement their workflow logic.
Airflow doesn’t inherently handle failures and retries, they need to be handled by the code written into the DAG file, this can add a lot of boilerplate code to workflow definitions and make them difficult to maintain.
Airflow DAGs must be written in Python which may limit the appeal for some environments.
Clusters require multiple applications and infrastructure running altogether, which could make it difficult to set up, configure and manage.
Cadence Architecture
Cadence has an architecture in a similar vein to Airflow, it requires various different applications working in unison to complete the whole picture.
Cadence also has a split in responsibilities between what the user supplies to facilitate workflows and what the Cadence cluster runs itself.
Cadence cluster
A cluster environment comprises the following applications
1. Cadence application
Cadence servers are comprised of a few different services
a. Front end – A stateless service that users interact with. Users submit jobs, query via the CLI or use Cadence Web to view workflow details.
b. Matching – Pairs the activities that workflows need to execute with the workers that can complete the work
c. History – Orchestrates the execution and current state of active workflows in the Cadence system
d. Internal Worker – Organizes internal workflows and activities used by Cadence itself to manage the application.
2. Persistence database
Where all the information about Cadence and workflows are stored. Cadence is implemented with pluggable back ends, including support for NoSql databases: Apache Cassandra and Scylla, or SQL databases: Postgres and MySQL.
3. Optionally: Apache Kafka & OpenSearch
Cadence supports a feature known as Advanced Visibility, which allows you to attach searchable information to your workflows and make them available using simple search semantics.
To facilitate this, Cadence requires Apache Kafka and OpenSearch clusters to orchestrate and store this information.
Client application
In addition to the Cadence cluster and supporting applications, Cadence workflows and activities are executed on Cadence workers.
These can be Workflow workers or Activity workers (or both), and are run as separate applications which are then registered with the Cadence application.
A worker registers with Cadence the workflows and activities it is built to execute. When a Cadence workflow is started, the matching service will be told which activity needs to be executed, and will find a registered worker that can perform this activity.
The code is executed remotely on the worker, and the result returned to the Cadence cluster where it is stored.
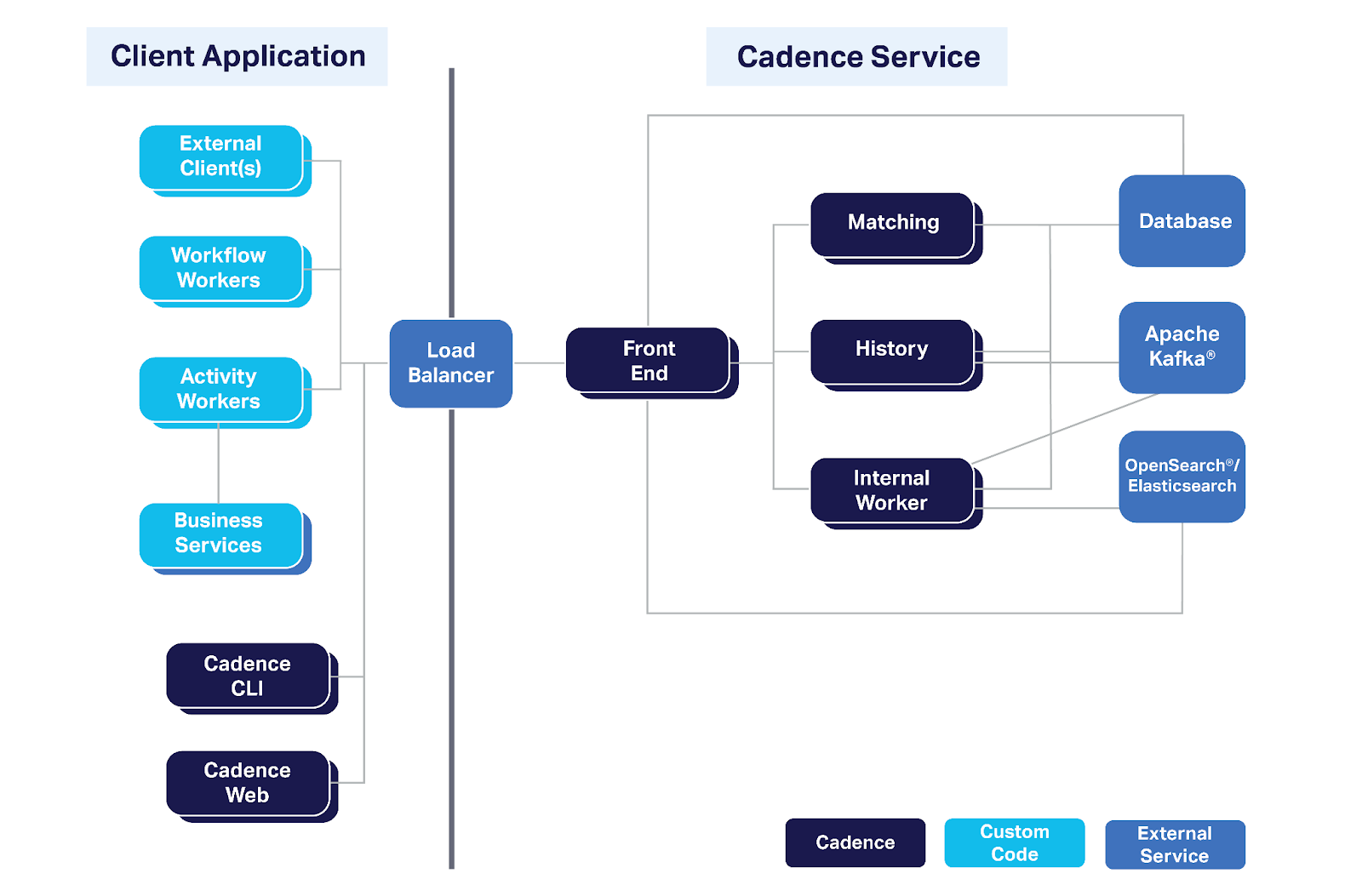 Ref: cadenceworfklow.io – Cadence topology
Ref: cadenceworfklow.io – Cadence topology
Control Flow
A Cadence workflow definition is a software class, written in any of the supported languages, consisting of an interface and an implementation. A workflow implementation comprises one or many activities and the logic that is required to complete the workflow.
An activity is an encapsulated function that returns a value. It is the building block that Cadence uses to ensure the workflow itself is fault tolerant and recoverable.
The result from an activity is binary, either it succeeds, and the result stored and workflow progresses, or it fails. Failed activities are normally retried, so they should be somewhat idempotent, depending on your requirements.
Workflows and Activities are implemented by workers and workers are registered with Cadence. When a workflow is started, workflows and activities are executed by the workers registered, at each completed step, their results are sent back to Cadence and stored in the database.
Cadence supplies a gRPC interface to the front end service, and natively supports Java and Go client SDKs. In other languages, such as Python and Ruby, support is provided by third party contributors which are in various stages of development.
User Interface
Cadence has two user interfaces, the Cadence Command Line Interface (CLI) and Cadence Web.
The CLI can be used to start new workflows, query the current state of workflows, register new domains and configure various settings in the cluster.
Cadence Web gives a web interface to domains, running workflows and, if configured, the ability to search using custom fields with Advanced Visibility.
Workflows can be interrogated, viewing what steps they are on, and the result of activity calls. You can view error logs, detailed workflow call stacks and cancel running workflows.
Uber Cadence Use Cases
Due to the modular nature of Cadence with the various client SDKs and the worker paradigm it uses, Cadence is able to support a wide range of use cases.
It is the ideal tool when you are orchestrating calls to diverse, and potentially unreliable, APIs and third party systems,
Activities can encapsulate essentially any type of work, and workflows can organize their activities in whatever fashion they need. This makes Cadence able to express workflows from the very simple to the very complex, workflows can even start child workflows.
The client SDK allows users to set retry logic, exponential backoff and timeouts for each activity, giving developers precise control over the way their code executes.
All of these workflows execute in a durable, fault tolerant manner and they can be run ad-hoc or scheduled with a distributed cron job.
Documented use cases are drone deliveries, multi-tenant task processing, fleet OS upgrades and event driven processing, just to name a few.
Cadence Pros and Cons
Cadence allows developers to express workflows in any of the supported languages and write simple to understand, code-first solutions in almost any fashion they choose.
The stateless nature of the Cadence services makes it easy to scale your cluster as your usage grows, and the pluggability of the dependent applications give a lot of flexibility to infrastructure teams.
The worker paradigm adds additional infrastructure into the equation, but it also allows users to control access that an individual worker may require to external services instead of requiring the workers to have blanket access to everything.
Setting up a Cadence cluster and its dependencies, especially when using Advanced Visibility, can take a lot of work.
Instaclustr created our Managed Cadence offering to solve this problem, which allows developers to focus on creating their next great workflow, not setting up servers. Get started today.
Which is right for your application?
The support that exists in the market for Apache Airflow is largely centered around data migration, ETL and batch processing in data pipelines.
If you are looking for automation tools to solve these kinds of problems, and are happy writing them in Python, Airflow could be the right solution for you.
Cadence is a bit more diverse, due to how the worker code is expressed and the native error handling and execution guarantees that client SDK provides. It lends itself to solving problems that may span a wide range of services and APIs you may be running in your application.
It has native support for long running sleeps, signaling workflows from external systems, polling, batch jobs, chron jobs and many other features. It is more appropriate for environments where developer first, code first solutions are desired and prioritized.
If you have a microservice architecture and are orchestrating a diverse set of API calls as part of your application, Cadence is a great option for leveraging that platform and building better solutions.