As we’ve seen with Paul’s drone delivery network, Cadence® can orchestrate a huge number of simultaneous running workflows.
For most systems, it is a common task that we generate reports to measure the impact that particular system has for the business, for example an end-of-month sales report or billing query.
What is often less simple is getting a view of in-flight, or recently completed, workflows or processes themselves. The information you are interested in when managing a fleet of in-flight operations can be quite different from that of an end-of-month report.
Unfortunately, we often sideline this data visibility because it is the responsibility of an operations team to keep track of the work, and they are left to build tools themselves to extract the information they need to keep everything running smoothly.
Cadence to the rescue again!
Cadence Advanced Visibility
Cadence aims to solve this problem with a feature known as Advanced Visibility. So what is it?
In essence, it allows you to add metadata—key-value pairs—to a running workflow instance and expose it as searchable attributes which can be queried using tools like the Cadence CLI or Cadence Web.
This enables you to find and track a workflow, using fields that you tagged the workflow with.
Want to find all order workflows related to a specific customer? Add the customer field.
Want to find all the video encoding workflows related to a specific event? Add the event field.
Let’s jump in and look at how this works in more detail.
Cluster Configuration
Before we get started with Advance Visibility there is a bit of configuration that needs to be done at the following levels
- Cassandra®, OpenSearch®, and Kafka® Clusters
- All of these clusters are required for Cadence with Advanced Visibility. Each of them have their own configuration, setup, maintenance and runtime requirements.
- Cadence
- Once the clusters mentioned above are up and running we need to configure Cadence to connect to these services so we can use Advanced Visibility.
- Firewall, Authorization, Keyspace, Index, and Topics
- We need to configure the firewall rules between the clusters, keyspaces, and indexes in Cassandra and OpenSearch and create a topic in Kafka with the right partitioning and replication factor (RF), usernames, and passwords for access to these systems.
That’s where Instaclustr can help. We have developed a streamlined creation process on our web console, which allows you to create a Cadence cluster, with Advanced Visibility, by simply clicking a few buttons.
All the necessary dependencies are created and configured automatically and after a few minutes you have a running cluster in your account to start building workflows with.
Instaclustr Fleet OS Upgrades
In order to illustrate the benefits of Advanced Visibility, we have developed the following use case—Instaclustr’s fleet operating system (OS) upgrades.
Instaclustr manages a fleet of over 8000 nodes, and that number is growing every day. These nodes run a variety of different applications from Apache Cassandra to RedisTM, and we update the underlying operating system on a quarterly basis to ensure our customers have the most up-to-date and secure platforms running their business critical applications.
In addition to the various applications, our managed service clusters and nodes can run with different SLA agreements, run any number of nodes and node sizes, on different cloud platforms, in different regions and even on premises in our customers own data centers.
Finally, our customers have their own operational requirements for their clusters, and sometimes they may need to postpone OS upgrades to cover a business requirement or special event.
As you can imagine, coordinating OS upgrades across a fleet like this is a complex task, and the Operations team dedicates a lot of resources to ensuring these upgrades are executed as efficiently and seamlessly as possible.
For this article, we are going to propose a solution using Cadence workflows, and track the upgrade process of the fleet using Advanced Visibility.
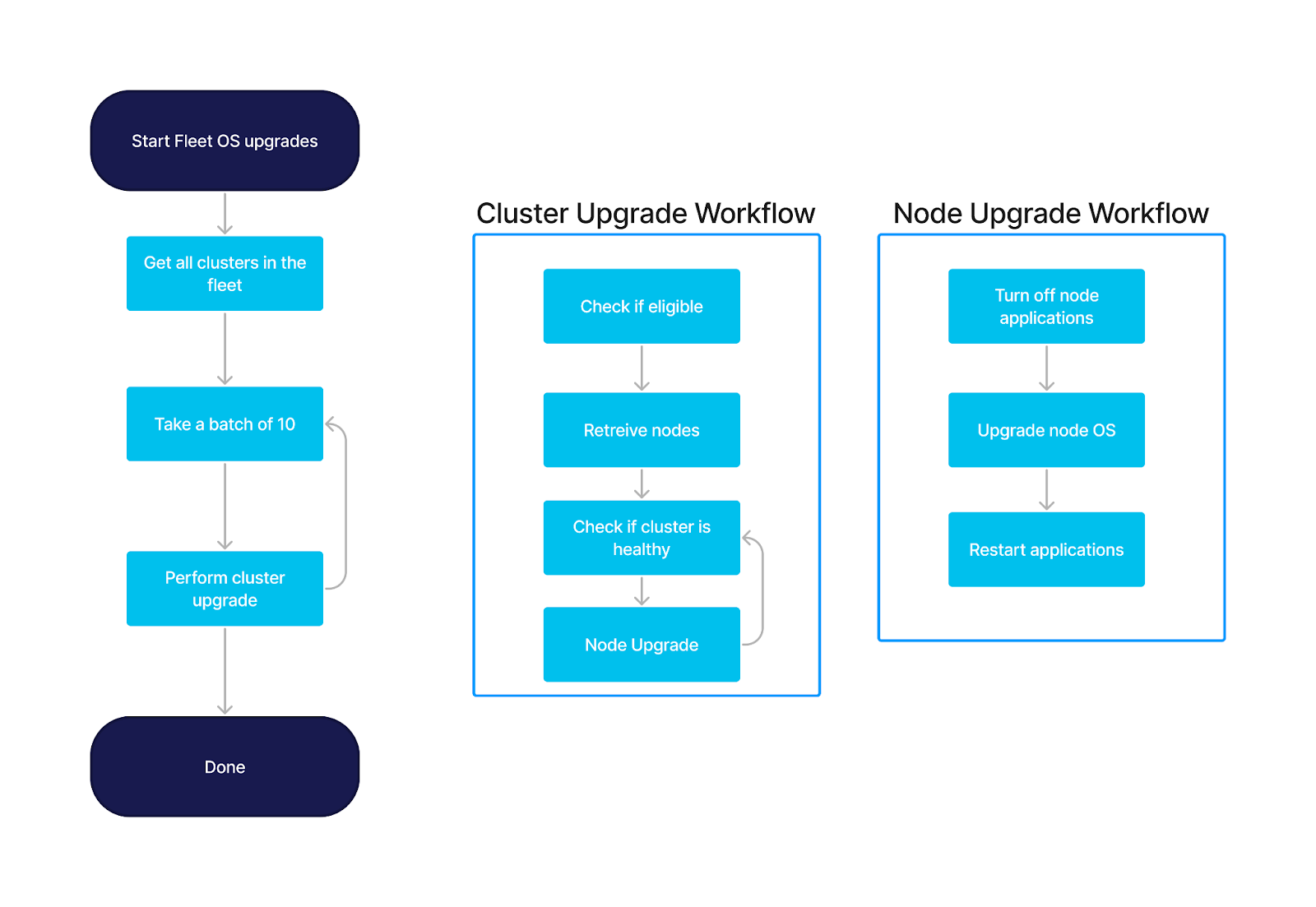
The Fleet Upgrade Workflow
Let’s have a look at our fleet upgrade workflow definition.
Our Operations team’s dream is to have a fully automated process that starts itself every quarter, so let’s aim for the stars here and see how we go.
We perform the fleet update in a staged approach. We want to limit the number of operations that are happening at one time; upgrading 8000 clusters at once is…not advised!
- Take the entire fleet of clusters and split them into batches of 10—we have a very well defined strategy for grouping these clusters, but for this exercise we will just keep it simple.
- For each cluster, we start a child workflow.
- The cluster level workflow is responsible for upgrading 1 node at a time.
- First we check if the cluster is eligible for upgrade, checking if there is an exception that the customer has asked for
- Notify the customer of impending upgrade
- Then, we check if the cluster is in a healthy state using metrics and other indicators. Each application handles offline nodes differently, and we must be sure taking the node offline will not put the cluster in a degraded state
- We start a child workflow to upgrade the node
- Shut down the applications
- Upgrade the node
- Restart the applications
- Once it’s complete, we repeat the process and health check the cluster again until all the nodes are exhausted
- Notify the customer the cluster upgrade is complete
- Once all 10 of the inflight clusters are upgraded, we move onto the next 10 clusters.
The workflow can be visualized in this diagram:
Potential Fleet Operation Issues
Now that we understand the steps to our workflow, we need to anticipate some of the likely issues we will encounter. Experience has shown us that as our fleet grows, the number of different issues we observe during fleet operations increases. We take the lessons of the previous process into the next one, but the most important priority for our Operations team is to have all the tools available to diagnose and respond to any issue in a timely manner.
Let’s identify some issues that can arise during a fleet operation of this magnitude:
Long Running Operations
Fleet operations such as these can take a long time to complete—it’s important to give our Technical Operations team as much visibility of potential issues as soon as possible. One potential risk in our workflow is a single slow cluster in the batch of 10 which can hold up the entire fleet OS upgrade process. We don’t want to increase the number of parallel tasks, we just want to identify these clusters quickly and remediate them.
In our example, the most likely scenario would be a cluster that is continually failing health checks. The health checks are calibrated to ensure a cluster is in the best possible state to accept a node being upgraded; it may not be in an unhealthy state, but just not healthy enough to progress.
It’s important that the Operations team is able to identify this and resolve it, or cancel the upgrade so the rest of the fleet can progress.
Cloud Provider Outage
This is not an uncommon occurrence, it can range from a minor issue like an API responding slowly to a full blown availability zone outage.
When issues like this occur, we need to be able to identify which clusters are impacted quickly so we can assess what the next step is. The best thing to do in this scenario is to cancel all operations during the downtime to avoid any issues.
Application Specific Incompatibility
We do extensive testing for every operating system upgrade, each application is thoroughly verified in lower environments, but that isn’t a guarantee we won’t run into any issue once we hit production.
If we identify such an issue, we need to be able to find all impacted clusters and triage them further.
Preparing the Workflow
So we have identified the information we need, now let’s see how Cadence enables us to find workflows for these scenarios.
For simplicity’s sake, we are going to focus on the child workflow, OSUpgrades workflow at the Cluster level, to deliver all the visibility fields we need.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
public void quarterlyOSUpgrades(UUID cluster) { final ClusterOSUpgradeActivities activities = Workflow.newActivityStub(ClusterOSUpgradeActivities.class, new ActivityOptions.Builder() .setRetryOptions(new RetryOptions.Builder() .setInitialInterval(Duration.ofSeconds(10)) .setMaximumAttempts(3) .build()) .setScheduleToCloseTimeout(Duration.ofMinutes(5)).build()); Workflow.upsertSearchAttributes(Map.of("clusterId", cluster)); // Check maintenance window is open if (activities.canUpgradeCluster(cluster)) { // Get cluster info ClusterInfo clusterInfo = activities.getClusterInfo(cluster); Workflow.upsertSearchAttributes(Map.of( "primaryApplication", clusterInfo.primaryApplication, "provider", clusterInfo.provider, "datacenter", clusterInfo.datacentre, "account", clusterInfo.accountId)); // Notify customer Async.procedure(activities::notifyCustomerUpgradeStarted, clusterInfo.clusterId.toString()); // Create workflow for each node, wait for it to complete then progress for (UUID node : clusterInfo.clusterNodes) { waitForHealthyCluster(cluster, activities); // Start node workflow synchronously NodeOSUpgradesWorkflow nodeWorkflow = Workflow.newChildWorkflowStub(NodeOSUpgradesWorkflow.class); nodeWorkflow.quarterlyOSUpgrades(node); } // Final health check for cluster waitForHealthyCluster(cluster, activities); // Notify customer the upgrade is complete Async.procedure(activities::notifyCustomerUpgradeStarted, clusterInfo.clusterId.toString()); } } // Perform a cluster health check, and keep track of how long the workflow is // waiting for private void waitForHealthyCluster(UUID cluster, final ClusterOSUpgradeActivities activities) { // Wait for cluster health // We do this for every node because the OS Upgrade process could be disruptive int healthChecks = 1; while (!activities.clusterIsHealthy(cluster)) { Workflow.sleep(Duration.ofSeconds(60)); healthChecks++; // Time a cluster has been waiting for a healthcheck // This will it easy to find clusters in an unhealthy state for a prolonged // period of time Workflow.upsertSearchAttributes(Map.of("timeWaitingForHealthyCluster", healthChecks * 60)); } } |
The important piece of code here is Workflow.upsertSearchAttributes. This adds new values to the search attributes of the workflow instance.
We can see that we have added Cluster Id, Account Id, Primary Application, Provider, and Datacenter in this way. When the workflow is executed, these fields will be indexed by OpenSearch and can be used to search for workflows later on.
Another key aspect is that it’s an Upsert, meaning if we re-use a key, the value will be replaced.
We can see an example of why this is useful in the waitForHealthyCluster function; everytime a health check fails, we will increment the value. We will also reset the value for every new node that we encounter.
This is a good example of ephemeral operational data that may not be relevant anywhere else but is very useful to an operations team.
Adding Visibility
We have our workflow code figured out, now we need to configure the Cadence cluster before we can start searching.
We can do this by issuing a command with the Cadence Cli tool:
|
1 |
cadence --domain fleet-upgrades adm cl asa --search_attr_key timeWaitingForHealthyCluster --search_attr_type 2 |
The second value search_attr_type defines the value type of the field, which will be stored in our OpenSearch cluster.
| 0 | String(Text) |
| 1 | Keyword |
| 2 | Int |
| 3 | Double |
| 4 | Bool |
| 5 | DateTime |
We will run the command and register all the other fields, and then we can run our fleet upgrade workflow.
Searching Our Workflows
Now it’s time to launch our fleet upgrade workflow, I’ve kicked it off and let it run for a while. Now let’s see if we can respond to the3 issues we identified earlier.
Long Running Operations
First, let’s use Cadence Web to find clusters that have been waiting for healthy nodes longer than 2 minutes. In reality, 2 minutes is not very long, but for our purposes it is sufficient to demonstrate.
We start by flicking over to “Advanced search” and entering: timeWaitingForHealthyCluster > 120.
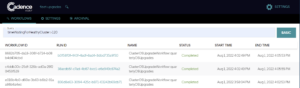
And there we have it, we found 3 clusters which went over that threshold, in this case all they have all completed successfully. In a production environment, the Operations team will have the flexibility to set whatever limits they feel are necessary to resolve these problems.
Service Provider Outage
Onto the next challenge—we’ve been notified of an issue in the Europe region in AWS, we need to find any workflows executing in this region so we can ensure they are not impacted.
Again, using Cadence Web we can find impacted workflows by entering the following search term:
Provider = ‘AWS’ and datacenter = ‘EUROPE’
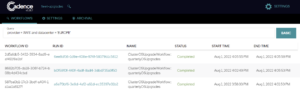
And again, we get the list of impacted workflows. Now depending on the issue, the Operations team can respond however they need to, but immediately know where to focus their attention.
Application Specific Incompatibility
Finally onto our last issue—some customers are reporting an issue with Redis after the OS upgrades. We have cancelled the workflow and now we need to investigate all the potentially impacted clusters.
This time, we will use the Cadence Cli to perform the search, using the command below:
|
1 |
> cadence --ad lb-2c111d97-3fcb-4c0a-aeb3-64edd-0dd7fc3ba12ee88d.elb.ap-southeast-2.amazonaws.com:7933 --domain fleet-upgrades wf list -q 'primaryApplication = "Redis"' -psa |
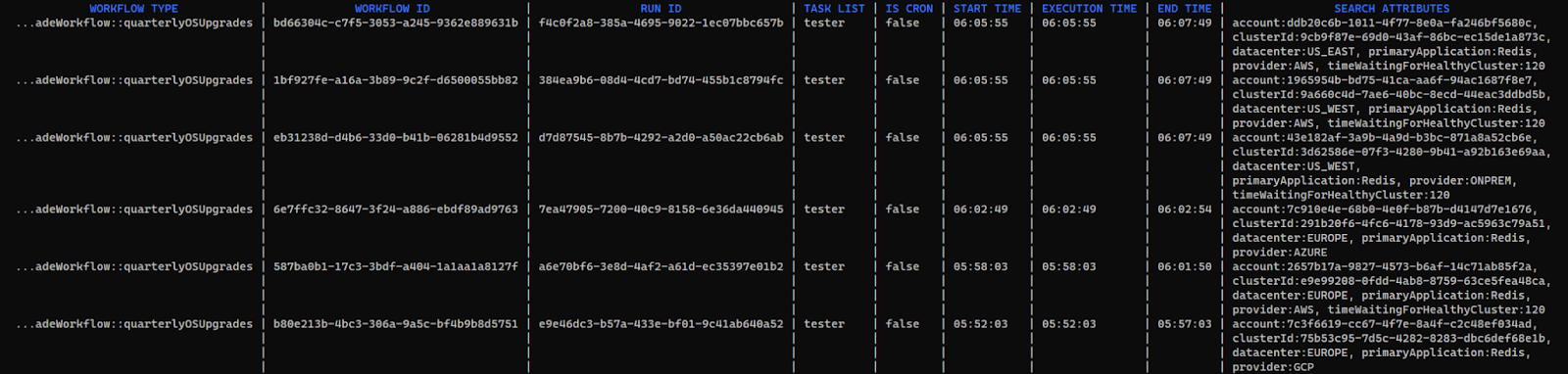
We can see here, in addition to the workflow information, our custom search fields are included in the output, allowing us to process the result with our favourite text formatting scripts if we so desire.
Wrapping Up
So there you have it! Hopefully we have illustrated the power and convenience of Cadence with Advanced Visibility. The possibilities are manifold, and taking advantage of them is really easy.
The fun doesn’t have to end here either. All of our information is stored in OpenSearch, and we could (perhaps in a later article) leverage the power of that application to drive even more reporting or visualizations for our fleet OS upgrade workflow.
Advanced Visibility allows developers to keep the information important to the operation of their workflows right next to the workflows and business logic. We can see how simple it is to add additional fields as we mature our workflow, and it’s all written in simple to understand code in Java or Golang.
Instaclustr continues to develop our Cadence managed service, and we are adding new features regularly to help developers take advantage of this incredibly powerful application. Try it now and start building your next great workflow.