Generating a load for Apache Kafka using Apache JMeter
1. Introduction
The Anomalia Machina has kicked off, and as you might be aware, it is going to do some large things on Instaclustr’s Open Source based platform. This application will primarily use Apache Kafka and Apache Cassandra hosted on Instaclustr’s managed services.
The building of Anomalia Machina is going to be iterative and experimental. We want to be ready in order to support this approach, so we want to develop some tools to help us setup the infrastructure for such a colossal task.
In the previous blog we showed how to provision Cassandra and Kafka clusters automatically with Instaclustr’s provisioning API. In this blog we generate lots of load for Kafka.
2. Kafka Cluster Load Generation
The Anomalia Machina is going to require (at least!) one more thing as stated in the intro, loading with lots of data! Kafka is a log aggregation system and operates on a publish-subscribe mechanism.
The Kafka cluster in Anomalia Machina will be accumulating a lot of events which are to be processed to discover anomalies. The exact sequence of processing is still being prototyped at this point in time, but there is a solid requirement of a tool/mechanism to load the Kafka cluster with lots of data in a hurry.
The requirements pointed me in direction of looking for ‘Kafka Load Testing’. Firstly thinking of load testing, one tool comes to mind which is used very widely for load testing of Java based systems: ‘Jmeter’. Jmeter has rich toolset to perform various types of testing.
It also comes with many advantages viz. Open source, easy to use, platform independent, distributed testing etc. I can use Jmeter and test its ability to perform cluster loading.
As I expected, there are few open source Jmeter extensions available for Kafka load testing. I downloaded and installed Jmeter on my laptop and started testing out the Kafka extensions.
I used ‘kafkameter’ and ‘pepperbox’ to connect and load a local kafka cluster. Both the extensions worked well for me as I did very basic setup of a local Kafka cluster with no security options used, nor any networking complexity.
3. What is Jmeter?
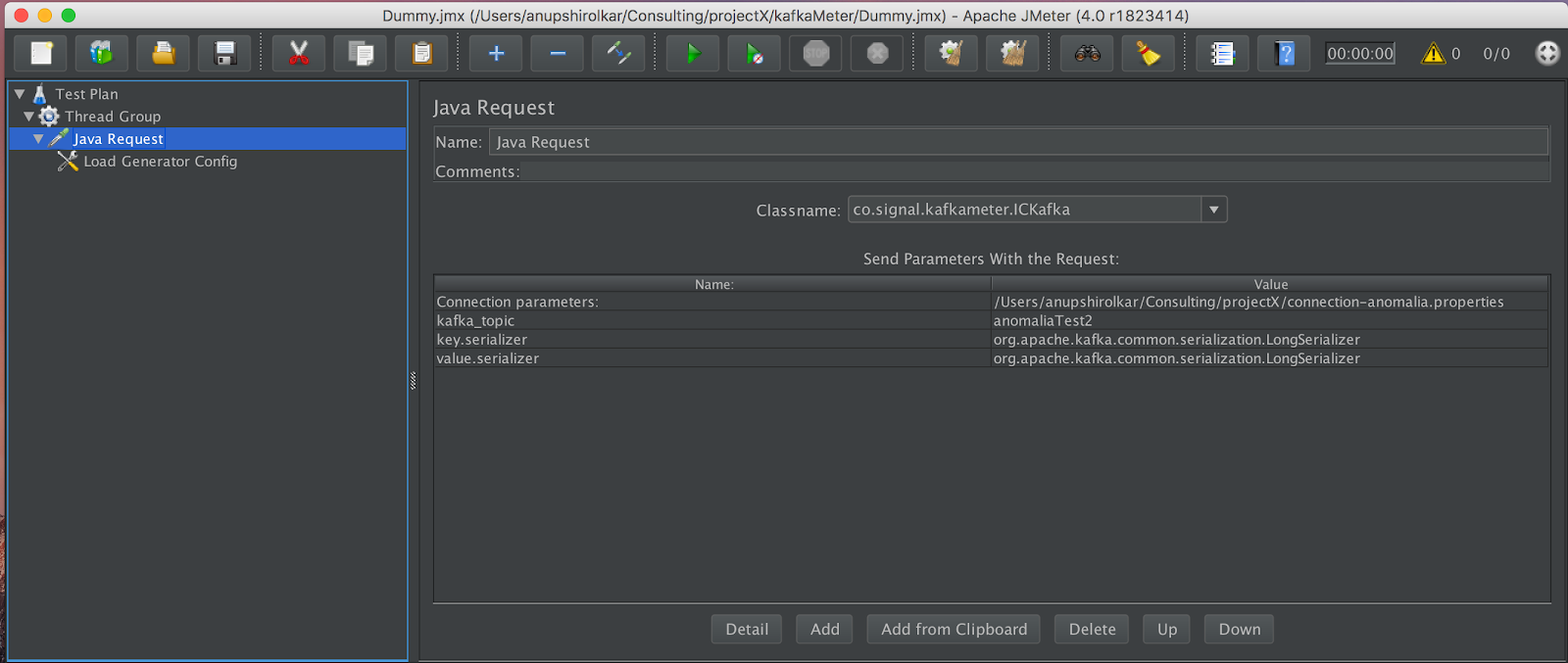
Before proceeding further, let me go into the essential basics of Jmeter. I used Jmeter project documentation: how to use it. Jmeter comes with a nice GUI which helps to use it and understand the concept. Jmeter requires a ‘Test Plan’ in the form of a jmx file.
The test plan contains all the details e.g. Number of threads to run, number of iterations, variables to hold dynamic data, result capturing, logic for generating test cases etc.
Jmeter comes with the facility to create extensions for testing various products. The extensions are in the form of jar files which can be simply dropped into Jmeter to use. Finally, Jmeter can be used with a command line without the GUI and it is much more efficient.
The extensions I evaluated give different capabilities to Jmeter. The ‘KafkaMeter’ has a load generator element which provides a ‘Synthetic load generator’.
In short, you can plug in a custom java class and generate events of your choice. ‘pepperbox’ uses KafkaMeter internally and provides the ability to configure complex events based on JSON templates.
Equipped with Jmeter, a couple of Kafka extensions and test plans at my disposal, I provisioned a Kafka cluster with 3 brokers. The Instaclustr Kafka clusters have SASL_SSL enabled by default. For more information on Apache Kafka encryption and authentication see “Introduction to Apache Kafka Security” and Apache Kafka Security documentation.
4. Testing Kafka Extensions
I wanted to test the Kafka extensions to load events with the cluster, but I faced a few challenges with connectivity due to the security settings. The problem was that the default options provided by the both the extension were not sufficient for including SASL_SSL connection options.
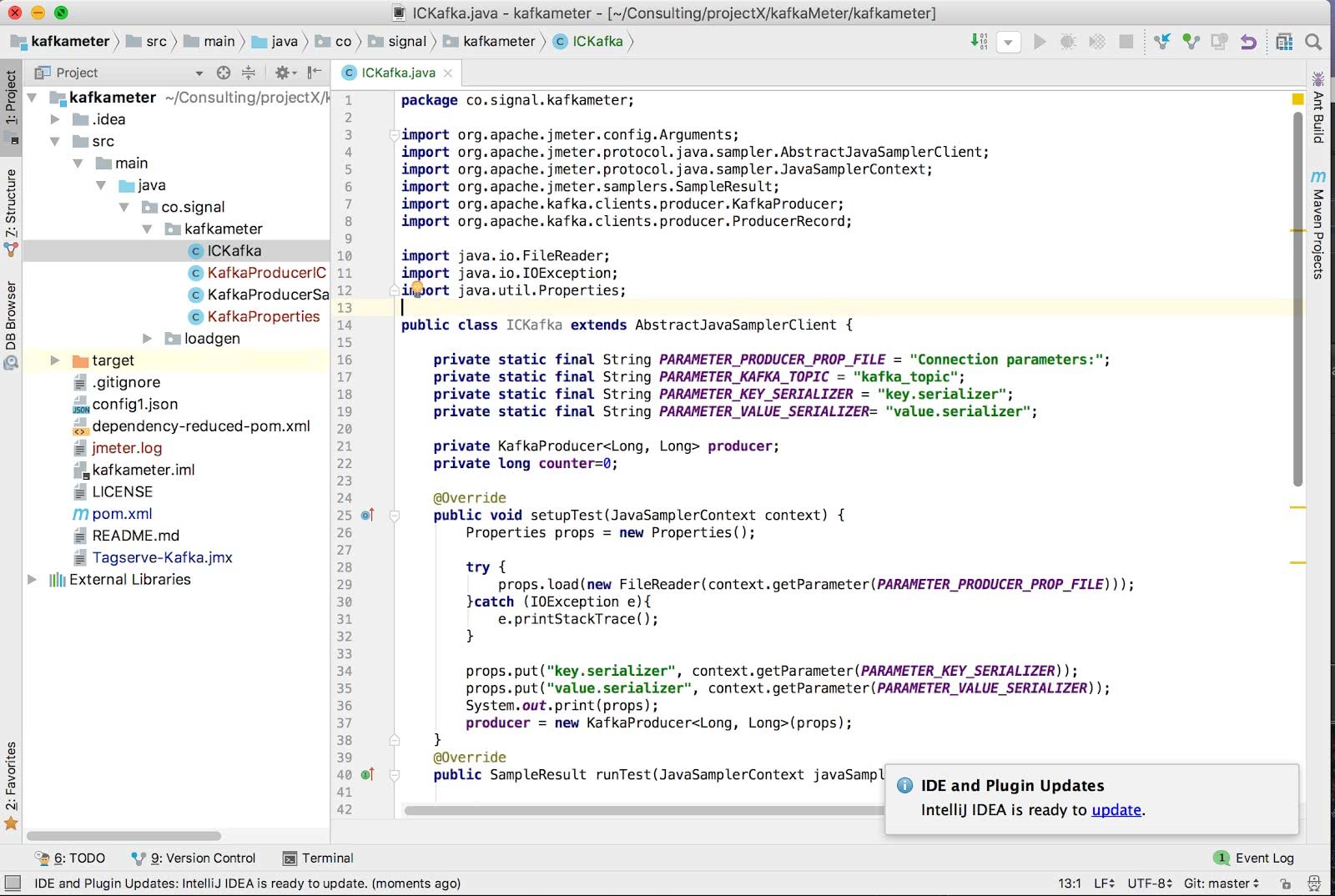
I looked into the code and after some head scratching, debugging, and googling I figured out that I had to write a new class which overrides ‘AbstractJavaSamplerClient’, implement lifecycle methods to setup the connection and generate events for kafka.
I also faced issues due to wrong dependencies being picked up as KafkaMeter and pepperbox both work with similar dependencies. Finally, I decided to go with KafkaMeter and removed all the pepperbox part from my Jmeter setup and was successfully able to load sample events to a Kafka cluster hosted on Instaclustr.
The next few steps were focused towards increasing the efficiency of load generation. This involved executing the Jmeter from an EC2 instance in AWS to put it right next to the cluster and get rid of all the network latency.
I provisioned an EC2 instance with basic setup required like Ubuntu ami, java and jmeter installations. I loaded Jmeter with my custom jar and test plan. The non gui mode of Jmeter on the ec2 instance gave me good performance.
I also increased the number of threads which worked seamlessly and gave me an increased rate in multiples of the first run as expected.
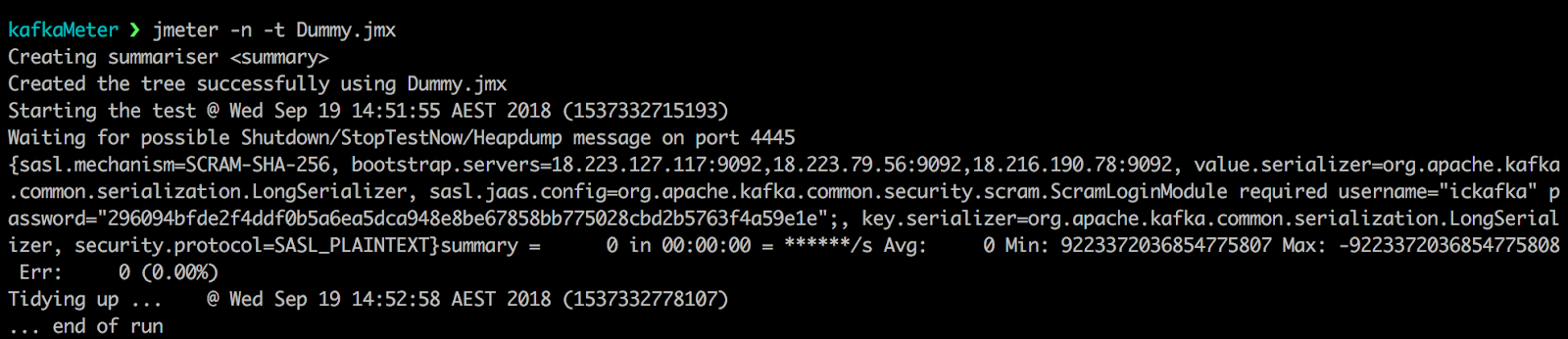
Well, the setup looks pretty solid with an EC2 instance which can be fully utilised with 100s of threads to generate a high event generation rate for Kafka loading.
5. Distributed Testing
But there is one more area to cover so that we can talk in terms of 1000s of threads generating some serious amount of load which will be required at some point for Anomalia Machina.
Jmeter supports ‘Distributed Testing’ which can be used for ‘distributed loading’. The feature includes setting up multiple instances called servers to generate load parallely (yes, parallely is a word, albeit from the 17th century). These servers are invoked and controlled by a single ‘master’ instance.
The Distributed testing requires setting up a few things. Jmeter instances communicate over RMI so there should be designated port for RMI, the nodes need to be reachable from each other and if there is a requirement of secure connection, SSL needs to be setup.
I provisioned 3 more EC2 instances to perform distributed testing. The EC2 instances are all part of one VPC and hence are reachable from each other via private IP.
Using private IP is not a strict requirement, but the instances must be able to communicate over RMI. The configuration file for jmeter is ‘/bin/jmeter.properties’. The master node needs to have server nodes listed in ‘remote_hosts’, ‘client.rmi.localport’. The server nodes should have ‘server.rmi.localport’.
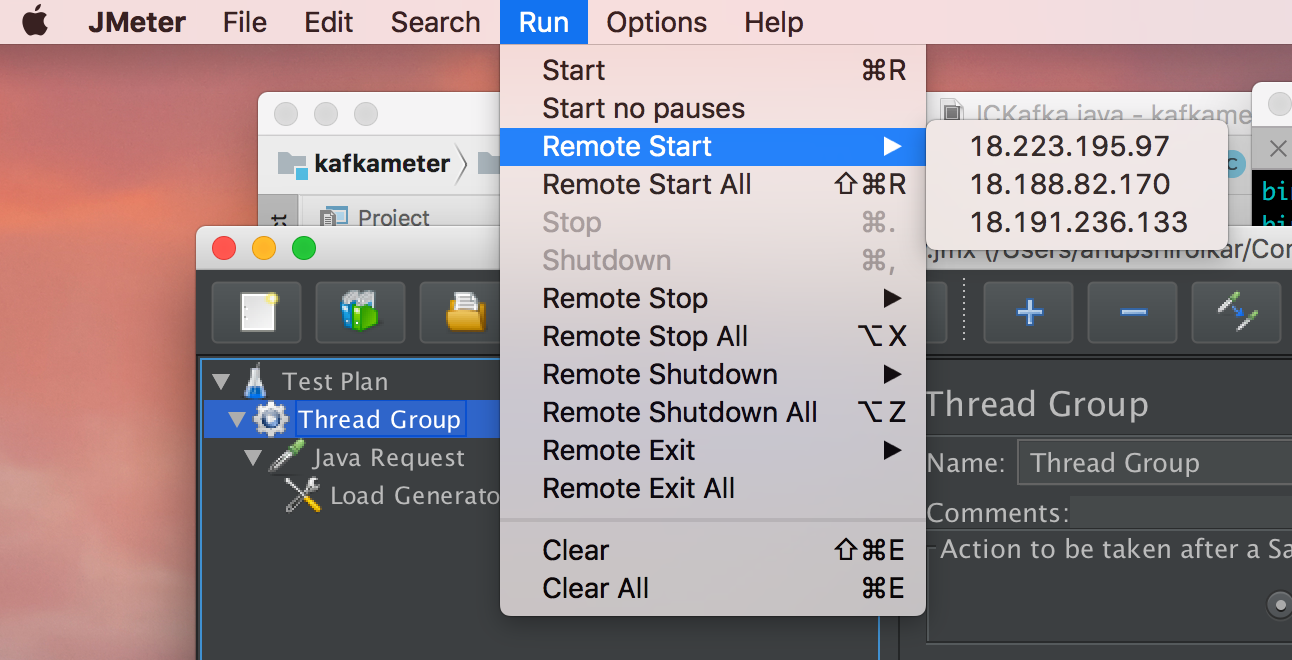
Once all the setup was done, I started the server process on all server nodes and invoked the Jmeter console on master node.
The servers take some time to start until the Jar is copied across from master, after which distributed load generation works great. The setup utilises a single jmx test plan submitted at master node, each server invokes number of threads suggested in test plan. The complete setup gives us a scalable mechanism for load generation.
***
Please find the Kafka loading project on our Github account: https://github.com/instaclustr/KafkaLoadGenerator