Kafkafying: the transformation of a primitive monolithic program into a sophisticated scalable low-latency distributed streaming application (c.f. “An epidemic of a zombifying virus ravaged the country”)
Steps for Kafkafying Kongo
In the previous blog (“Kongo” Part 2: Exploring Apache Kafka application architecture: Event Types and Loose Coupling) we made a few changes to the original application code in order to make Kongo more Kafka-ready. We added explicit event types and made the production and consuming of events loosely-coupled using the Guava EventBus. In this blog we build on these changes to get an initial version of Kongo running on Kafka.
Step 1: Serialise/deserialize the event types
What is serialization? In publishing serialization is when a larger book is published in smaller, sequential instalments. Serialized fiction surged in popularity during Britain’s Victorian era. A well-known example is the Sherlock Holmes detective stories, which were originally serialized in The Strand magazine:
 (Source: Wikimedia)
(Source: Wikimedia)
And deserialization? That’s what happens when you try and reconstitute the original complete stories. There are 79 Strand magazines with Sherlock Holmes stories!
The concept is similar in distributed systems and is necessary due to differences in data types, programming languages, networking protocols, etc. Data structures or Objects are serialized into bit streams, transmitted or stored somewhere else, and the process reversed and the bits deserialized into copies of the originals.
In the previous blog we created the explicit event types to prepare Kongo for Kafka:
Sensor, RFID Load, RFID Unload and Location check Events. To use these with Kafka we need to enable them to be serialized and deserialized.
From our introductory Kafka blog (Exploring the Apache Kafka “Castle” Part A: Architecture and Semantics) recall that the important Kafka concepts are Producers, Consumers and Topics. In Kafka, a ProducerRecord object is created to write a record (a value) onto a Kafka topic from a Producer. ProducerRecord takes a topic and a value (and optionally timestamp, partition, and key).
To create a ProducerRecord you need to supply the key (optional) and value (required) serializers, and some other parameters. Here’s an example using the built in Kafka serializers for basic Java types, with the key and value as Strings:
// create and use a Kafka producer with key and value as String types
KafkaProducer<String, String> stringProducer;
Properties props = new Properties(); props.put("bootstrap.servers", KafkaProperties.KAFKA_SERVER_URL + ":" + KafkaProperties.KAFKA_SERVER_PORT);
props.put("client.id", "KongoSimulator");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
stringProducer = new KafkaProducer<>(props);
// write a string value to a topic
stringProducer.send(new ProducerRecord("topic", "event 1").get();
Here’s the list of built-in Kafka (de)serialization methods.
But what if you have more complex event types (like Kongo’s Sensor and RFID events) that you want to write and read from Kafka topics? Under the hood Kafka only writes and reads byte streams to/from topics, so Java objects can’t be directly written and read. You have to write custom serializers.
To create custom serializers (such as for POJOs) the Serializer interface has to be implemented. We wrote a serializer class for each Kongo event type. Here’s the example for Sensor. Note that both the serializer and deserializer are in the same class for simplicity:
public class SensorSerializer implements Closeable, AutoCloseable, Serializer<Sensor>, Deserializer<Sensor> {
public static final Charset CHARSET = Charset.forName(“UTF-8”);
@Override
public void configure(Map<String, ?> map, boolean b) {
}
@Override
public byte[] serialize(String s, Sensor sensor) {
String line =
sensor.time + “, ” +
sensor.doc + “, ” +
sensor.tag + “, ” +
sensor.metric + “, ” +
sensor.value;
return line.getBytes(CHARSET);
}
@Override
public Sensor deserialize(String topic, byte[] bytes) {
try {
String[] parts = new String(bytes, CHARSET).split(“, “);
int i = 0;
long time = Long.parseLong(parts[i++]);
String doc = parts[i++];
String tag = parts[i++];
String metric = parts[i++];
double value = Double.parseDouble(parts[i++]);
return new Sensor(time, doc, tag, metric, value);
}
catch(Exception e) {
throw new IllegalArgumentException(“Error reading bytes”, e);
}
}
@Override
public void close() {
}
}
RFIDLoad and RFIDUnload Events also need similar code. This approach simply turns the java objects into Strings and then into a byte stream, and is the simplest approach I could think of. There are more sophisticated approaches. This is a useful blog which looks at some alternative custom serializers, and is also based on a Sensor POJO example. It also has code examples. The blog “Kafka Serialization and the Schema Registry”
provides a more in-depth look at using the Apache Avro serializer and the Kafka Schema Registry which may give improved flexibility and type safety.
Luckily this is the first time I’ve had to think about writing explicit code for (de-)serialization for a (long) while. However, it’s similar to (un-)marshalling which was a significant contributor of performance overhead in other distributed systems technologies such as CORBA, enterprise Java, and XML-based web services. It turns out that there are slower and faster Kafka (de-)serialization methods. If you want to read further, the following linked blog demonstrates that byte arrays are faster for reading and writing, and there’s also an example of using the default Java Serializable interface and Input/Output streams. Once I’ve got Kongo up and running on a more production-like Kafka cluster I may revisit the question of which is the best approach, for functionally and performance.
After implementing Kafka Producers and Serializers, events can be written to Kafka topics. Different event types can be written to the same topic, or the same event types can be written to different topics. Now there is a choice to make about how to map the EventBus topics from the previous blog to Kafka topics. How many topics should there be?
Interlude
In order to add Kafka Producers and Consumers to the Kongo application, a new class called KafkaRun was written which acts as the top-level control for the simulation. It creates Kafka Consumers for each event type, and starts them running in their own thread(s). They are all single threaded at present but can have more if required. Then it starts the simulation running. The simulation code was modified to use the new Kafka Producers to sent events to different topics. Note that the default is for kafka topics to be created automatically which is what we assumed (the code doesn’t explicitly create any topics). During the simulation the Consumers read messages from topics and process them as before (i.e. checking sensor/goods rules, moving goods around, and checking co-location rules).
Step 2: One or Many Topics?
Alternative 1: The more topics the merrier!
The simplest way to map the previous loosely coupled EventBus Kongo design to Kafka was to blindly follow the same design, and replace the EventBus code with equivalent Kafka producers, topics and consumers. For Sensor events, we previously used (2.1 Sensor Events: One or many topics?) many EventBus (topics), one for each location, with each Goods object (dynamically) subscribed to the topic corresponding to its current location:
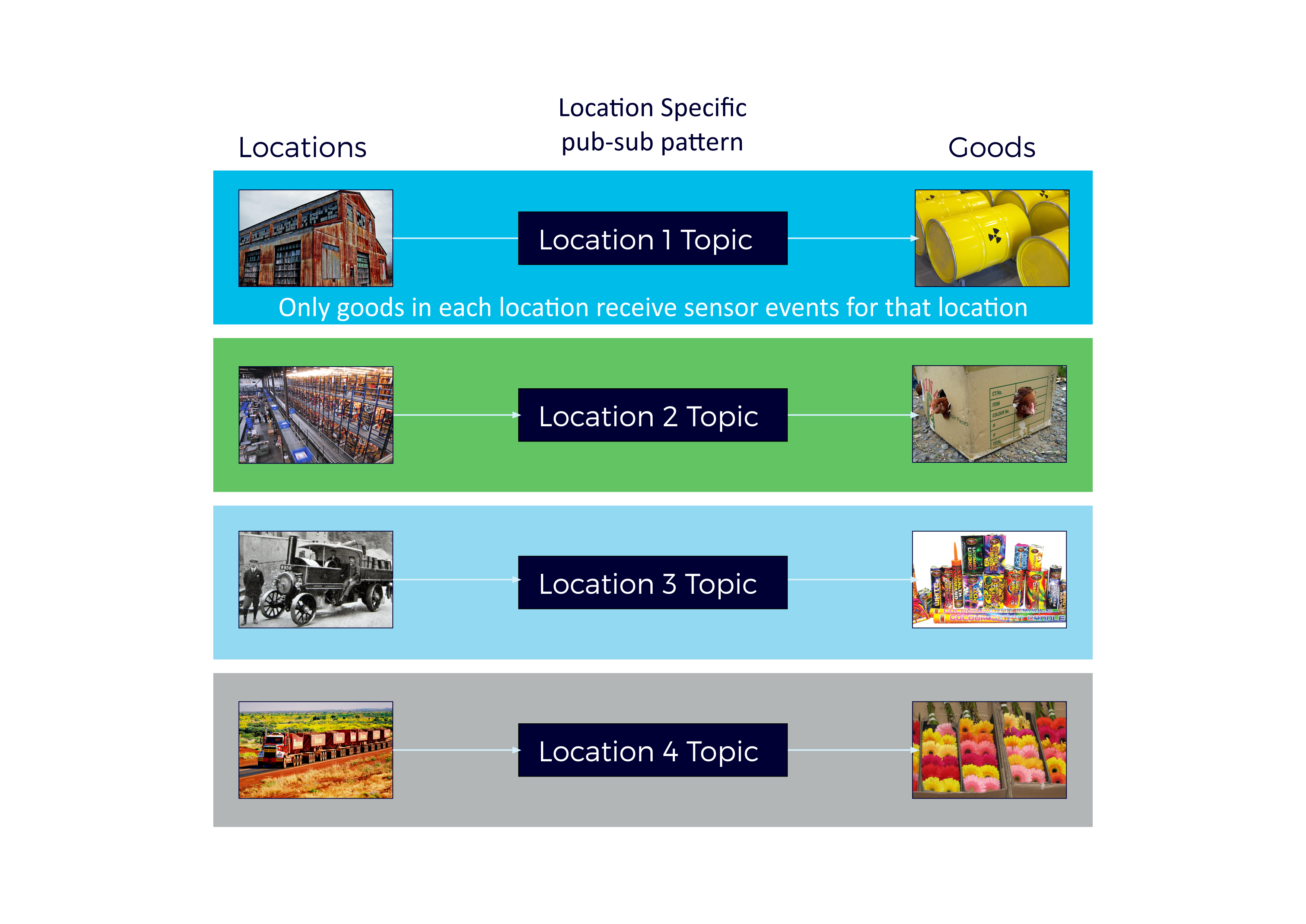
The Kafka version of this was also implemented with a Kafka topic for each location, and a Kafka Consumer per Goods object polling a Kafka location topic for sensor events.
Extra code was written to implement the Consumers to allow Goods objects to dynamically subscribe to the correct Kafka location topic, and run the sensor rules, We also needed RFID consumers to change the subscriptions when Goods were moved (in response to RFID Load and Unload events), and to check co-location rules. The simplest (and somewhat naive, as it turned out) implementation was to have a thread per consumer Goods object, and with each consumer object was in it’s own consumer group (to ensure that each Goods object got a copy of each sensor event per location). The code for this approach is in SensorGoodsConsumer, with some logic and options in KafkaRun and Simulate to create multiple sensor location topics and subscribe Goods consumers.
This diagram shows this approach with new Kafka components in black (rectangles are topics, diamonds are consumers):
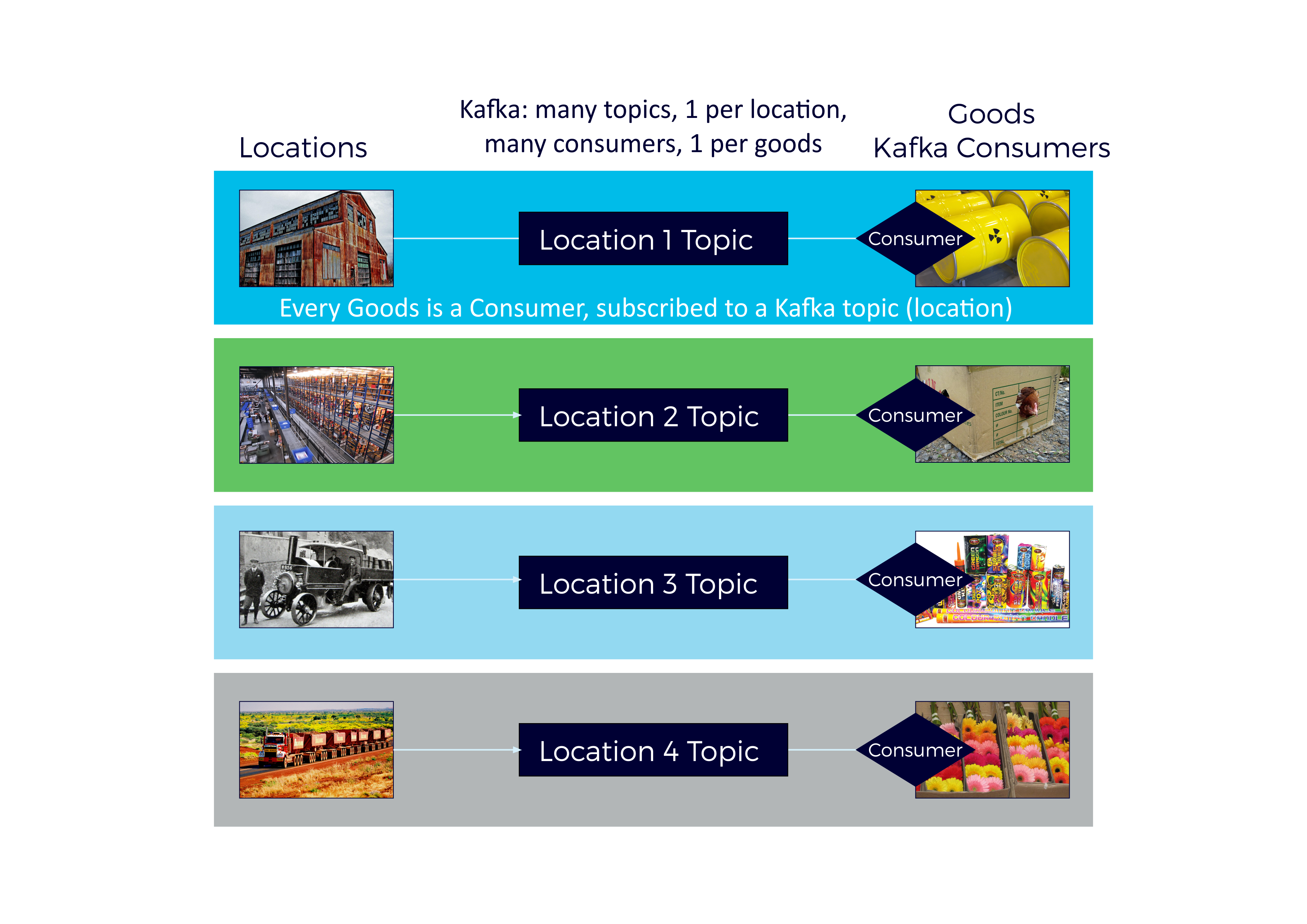
This approach (obviously) resulted in lots of topics (100s) and consumer threads/groups (1000s). Note that there was only 1 partition per topic, but due to the number of topics this meant there were also 100s of partitions. Did it work?
Functionally, yes. Performance-wise? Probably not, but it was hard to determine exactly where the bottlenecks were as everything is currently running on a single machine. For example, it’s possible that the problem was on the Kongo application side due to the large number of Consumer threads (we could have used a worker thread pool perhaps). In the long run this design isn’t scalable anyway – i.e. with thousands of locations and millions of Goods!
Note that the original EventBus RFIDLoad and RFIDUnload topics were also replaced by two equivalent Kafka topics and consumers (RFIDLoadEventConsumer, RFIDUnloadEventConsumer). Refer to the step 3 event ordering section below for further discussion.
Another related design choice is around alternative Consumer models. How many consumers and how many threads are desirable? This article explores the pros and cons of different Kafka consumer and thread models, and has code examples.
Alternative 2: One Topic (to rule them all)
One Ring to rule them all, One Ring to find them,
One Ring to bring them all and in the darkness bind them
– inscription on the One Ring, forged by Sauron
Given that many topics design didn’t work as expected, what’s the alternative? How many topics can you have? What’s the general advice?
It seems that there is no hard limit, but topics and partitions obviously consume resources. The standard advice is that rather than having lots of topics, it’s better to have a smaller number of topics (possibly only 1) and multiple partitions. This also guarantees event order, as there’s no guarantee of event order across topics or within a topic across partitions, only within each partition in a topic.
Taking inspiration from the Dark Lord Sauron we changed the design to have one Kafka topic for sensor events for all locations, with (currently) a single Kafka consumer subscribed to it. The consumer reads all the sensor events and puts each event on one of the original EventBus location topics, so that only the Goods at that location get the event and check their sensor rules as before. I.e. we are basically wrapping the original EventBus code with Kafka. The diagram shows this approach:
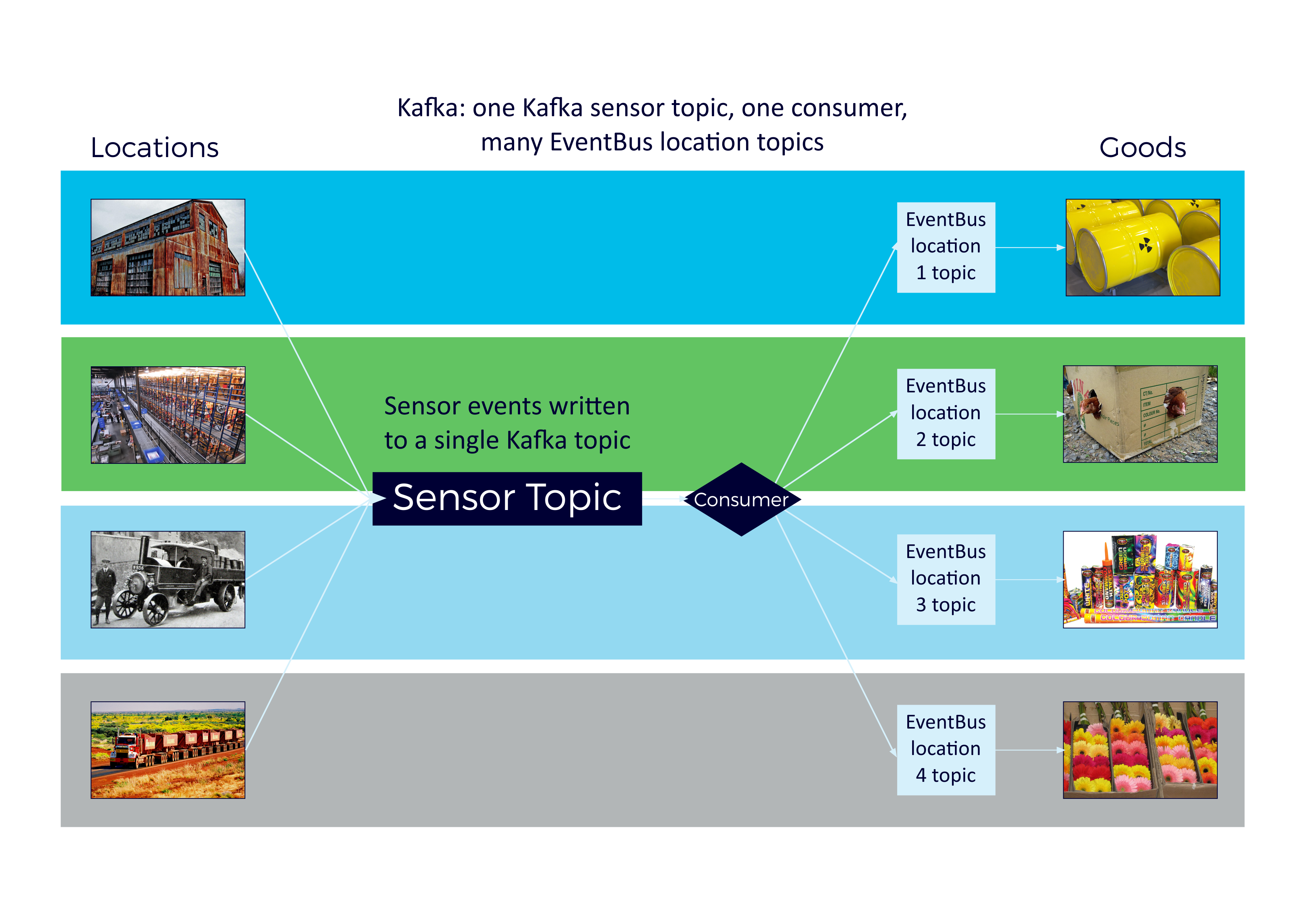 This code is SensorConsumer (with some logic in KafkaRun and Simulate.java to create 1 topic and subscribe consumers), and it works better than the approach with a large number of Kafka topics.
This code is SensorConsumer (with some logic in KafkaRun and Simulate.java to create 1 topic and subscribe consumers), and it works better than the approach with a large number of Kafka topics.
Step 3: Matter event order does? Depends it does.
The version of Kongo with a one sensor event topic sometimes produced exceptions related to the location of Goods (luckily I had put in pre-conditions with warning messages in the code for moving the location of Goods which checked if Goods were really in the location that a RFIDLoad and RFIDUnload event assumed). This turned out to be due to the use of the two distinct Kafka RFIDLoad and RFIDUnload topics which means that the load and unload consumers can get events out of order. Event order actually matters for RFID events. I.e. a Goods must be loaded onto a truck before they can be unloaded. The obvious solution was to use a single Kafka topic for both RFIDLoad and RFIDUnload events in order to guarantee event order. The code for this approach is RFIDEvent, RFIDEventSerializer, and RFIDEventConsumer (which determines which RFID event type is received and posts a load or unload event to the EventBus).
For event stream processing applications like Kongo, the state of the world depends on a stream of events in a particular order, so a general principle to keep in mind is that all events about the same “thing” may need to go in the same Kafka topic to guarantee ordering. Kafka streams are likely to be relevant for this so we’ll look at them in a future blog (as they provide state, windows etc).
Is this finally a correct and scalable design for a distributed Kafka version of Kongo? The current design has two Kafka topics, one dedicated to sensor events and one for RFID events. This gives correct event ordering within each event type but not across them. Could this be a problem? What happens if Goods are moved from a location before the sensor events can be checked for them at the location? Sensor rule violations could be missed. Part of the solution to these sorts of problems is to ensure that the consumers for each topic can keep up with the throughput so that they don’t get behind. The consumers can keep track of their own progress relative to the latest event (i.e. current offset – last read offset, see SensorConsumer), and spin up/down more instances until the backlog is processed. Explicit use of timestamps for processing (in conjunction with Kafka streams) and more explicit use of topic keys and partitions are also options that we will explore in future blogs.
Another approach is suggested by the fact that we detected event ordering problems as a result of having explicit preconditions in the Kafka consumer code for RFID events. If event ordering preconditions are not satisfied for an event it may be possible to postpone processing and retrying later on. Because Kafka consumers keep track of their own topic offsets a simple approach is for consumers to remember which events have problems, and retry them periodically, or even just write them back into the same topic again. Here are some blogs on Kafka event ordering and retrying.
The complete code for this initial Kafka version of Kongo is available here.
Instructions on setting up a local Kafka broker are in the blog: Apache Kafka Christmas Tree Light Simulation.