In Part 1 of this blog series we explored the background to Kafka® and meta-data management, including the use of ZooKeeperTM and the recent move to KRaft to replace it. We revealed the results of our first experiment with Kafka ZooKeeper vs. KRaft, to measure the impact of increasing partitions on a data workload. Interestingly, there was no difference in performance between a ZooKeeper cluster and a KRaft cluster. This result was to be expected, however, as ZooKeeper and KRaft are used for Kafa meta-data management. With this in mind, let’s formulate some more explicit hypotheses about expected similarities and differences between ZooKeeper and KRaft that we can evaluate further, and test the performance of Partitions and Meta-Data operations.
Hypotheses
Here’s a table with our initial hypotheses:
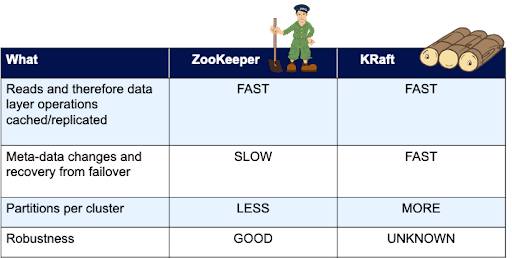
We’ve already confirmed the first hypothesis, that data layer workloads will be fast (and actually identical) with both ZooKeeper and KRaft, so it’s time to move onto the second hypothesis and explore the performance of meta-data operations, where we will hopefully see some measurable performance differences.
Experiment 2: Partition Creation Performance
For the next experiments we focus on some purely meta-data related operations, including how many partitions can we create on a cluster, can we create more on a KRaft cluster, and how long does it take to create them? For these experiments we limit the replication factor to RF=1, otherwise the background CPU load due to partition replication is too high and we could need very large Kafka clusters to achieve many partitions (CPU load on our 3 node Kafka cluster with 100 partitions and RF=3, with no data or workload is 50% as a baseline, leaving little headroom for data, workloads, or more partitions).
But the first problem we have to solve is how to come up with an approach to successfully create lots of partitions without disasters. We tried 4 different methods with varying degrees of success:
- kafka-topics.sh -create topic with lots of partitions
- kafka-topics.sh -alter topic with more partitions
- curl with the Instaclustr provisioning API
- A script to create multiple topics with fixed (1000) partitions each
All of these approaches failed eventually, some sooner rather than later! And, more seriously, after some failures the Kafka cluster was unusable, even after restarting the Kafka process on each node (thanks again to John Del Castillo for help behind the scenes)!
 (Source: Commons Wikipedia)
(Source: Commons Wikipedia)
The errors included:
- Error while executing topic command: The request timed out. ERROR org.apache.kafka.common.errors.TimeoutException: The request timed out.
- From curl: {“errors”:[{“name”:”Create Topic”,”message”:”org.apache.kafka.common.errors.RecordBatchTooLargeException: The total record(s) size of 56991841 exceeds the maximum allowed batch size of 8388608″}]}
- org.apache.kafka.common.errors.DisconnectException: Cancelled createTopics request with correlation id 3 due to node 2 being disconnected
- org.apache.kafka.common.errors.DisconnectException: Cancelled createPartitions request with correlation id 6 due to node 1 being disconnected
Nevertheless, even using the “all at once” approaches, we were able to get some results for partition creation time as follows:
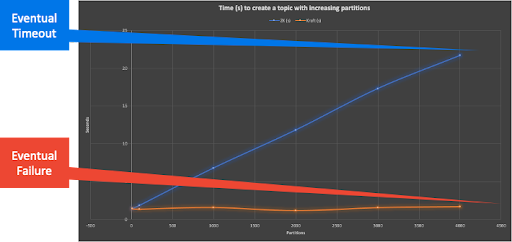
The performance difference between ZooKeeper (blue) and KRaft (orange) is very obvious, with the partition creation time increasing and eventually taking 10s of seconds and timing out for ZooKeeper (linear time, O(n)), and very low (constant time, O(1)) for KRaft, but with eventual “failure” with many partitions. However, for both ZooKeeper and KRaft the maximum partitions obtained was similar, around 4,000.
We also tried an incremental approach by adding partitions to an existing topic with results as follows:
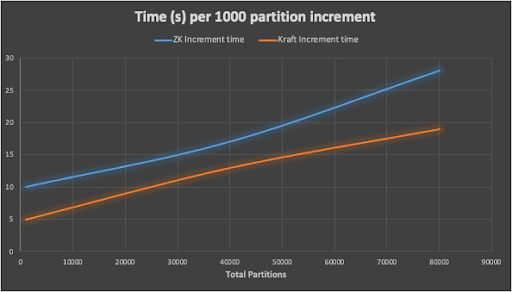
This was more successful as we were able to create more partitions than before. This graph shows time (s) per 1000 partition increment—the time increases with total partitions. Again, ZooKeeper is slower than KRaft, but it’s interesting that KRaft also takes time to add partitions (this was unexpected, and I’m not 100% sure why). But it’s a slow process to create a topic with many partitions for both ZooKeeper and KRaft (many minutes), and there is eventual failure for both—above around 80,000 partitions.
Our initial conclusions were that:
- It’s faster to create more partitions on KRaft c.f. ZooKeeper
- There’s a limit of around 80,000 partitions on both ZooKeeper and KRaft clusters
- Kafka fails in multiple ways!
- It’s very easy and quick to kill Kafka on KRaft—just try and create a 100k partition topic and it fails.
We’ll come back to the failure problems in the next blog.
Experiment 3: Partition Reassignment Performance
Partition reassignment is a common Kafka operation behind the scenes. If a server fails, you can move all of the leader partitions on the failed server to other brokers using the partition reassignment tool:
kafka-reassign-partitions.sh
You run it once to get a plan, and then again to actually move the partitions. For this experiment I measured the time to move a 10,000 partition topic (RF=2) from 1 broker to the other 2 brokers on a 3 broker cluster.
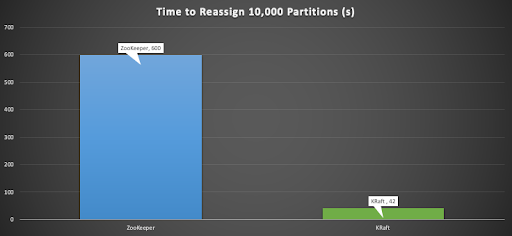
The time difference was significant, 600 seconds for the ZooKeeper cluster, and only 42 seconds for the KRaft cluster. Note that there was no partition data, and in a real-life example the time to move the actual data would be dominant.
With this experiment we have of course also provided the mice with a plausible question for the “Answer” (to Life, the Universe, and Everything!) i.e. how many seconds does it take to reassign 10,000 partitions using KRaft? 42 seconds!
(Source: Wikimedia, Creative Commons, https://commons.wikimedia.org/wiki/File:The-Meaning-Of-Life.png)
In the next and final blog of this series we will attempt to answer our final question (to Kafka, KRaft, Everything): How many Partitions can we create? And come to some conclusions about Kafka KRaft vs. ZooKeeper.