In this final part of the Kafka KRaft blog series we try to answer the final question (to Kafka, KRaft, Everything!) that has eluded us so far: Is there a limit to the number of partitions for a cluster? How many partitions can we create? And can we reach 1 Million or more partitions?!
1. Experiment 4: Maximum Number of Partitions

How many balls (partitions) can we juggle at once?!
(Source: Shutterstock)
For the fourth and final experiment in this blog series, we made one final attempt to reach 1 Million (or more) partitions (but with RF=1, to ensure that background CPU load on the Kafka cluster is minimal and doesn’t impact partition creation). For this approach, we used manual installation of Kafka 3.2.1 on a single large AWS EC2 instance so we had complete control over the environment with the latest version of Kafka available at the time. (Note that we are not using the Instaclustr Managed Kafka service this time around). We also used an incremental approach to partition creation, to prevent any of the errors previously encountered when trying to create too many partitions at once.
However, as before, trying to create lots of partitions hits a limit, this time at around 30,000 partitions, with this error (now visible in the logs):
|
1 2 3 4 5 |
ERROR [BrokerMetadataPublisher id=1] Error publishing broker metadata at 33037 (kafka.server.metadata.BrokerMetadataPublisher) java.io.IOException: Map failed # There is insufficient memory for the Java Runtime Environment to continue. # Native memory allocation (mmap) failed to map 65536 bytes for committing reserved memory. |
Initially, this looked like we didn’t have sufficient memory available, so we increased the instance size to one with 64GB of RAM available. However, we still got the same error.
After some Googling we wondered if we had sufficient file descriptors, as apparently 2 descriptors are used per partition. The default number of file descriptors is 65535 on Linux, so we increased the number to a much bigger number (on our Managed Kafka service this number is set a lot higher), but we still got the same error.
Further Googling found this error (from 2017!):
- KAFKA-6343 OOM as the result of creation of 5k topics (2017)
- Linux system setting: vm.max_map_count: Maximum number of memory map areas a process may have
- Each partition uses 2 map areas, default is 65,530, allowing a maximum of only 32,765 partitions
So again it looked like we were hitting a Linux OS limitation due to the default of 65530 mmap requests allowed per process, limiting the number of partitions to around 30,000 which was suspiciously close to the maximum we could create.
We therefore tried increasing vm.max_map_count to a very large number, and tried again. This time at least the error message was different, just a “normal” memory error:
|
1 |
“java.lang.OutOfMemoryError: Java heap space” |
After tweaking the JVM settings the error went away and we had more success at creating lots of partitions.
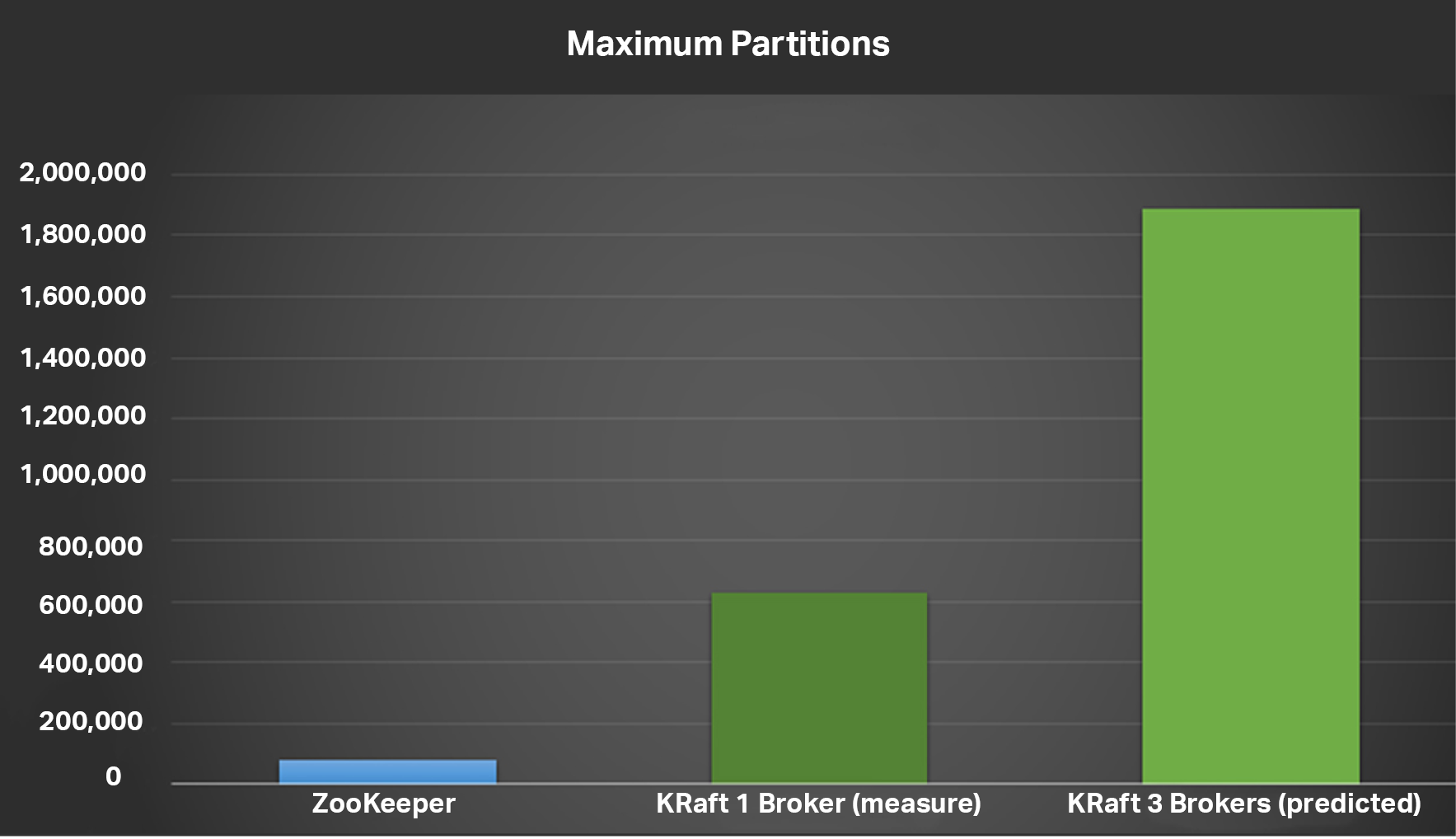 The maximum number of partitions we succeeded in creating in the previous experiments on a ZooKeeper cluster was around 80,000. In this experiment we succeeded in creating a lot more (x7.5), around 600,000 on a single Kafka KRaft broker. Extrapolating this to a 3 broker Kafka KRaft cluster would give us 1.9 Million partitions—which is more than a million so we have succeeded in our goal to create at least 1M partitions.
The maximum number of partitions we succeeded in creating in the previous experiments on a ZooKeeper cluster was around 80,000. In this experiment we succeeded in creating a lot more (x7.5), around 600,000 on a single Kafka KRaft broker. Extrapolating this to a 3 broker Kafka KRaft cluster would give us 1.9 Million partitions—which is more than a million so we have succeeded in our goal to create at least 1M partitions.
{kind=link}
However, it’s still painfully slow to create this many partitions using the incremental approach, due to the batch error when creating too many partitions at once. This turned out to be a real bug:
KAFKA-14204: QuorumController must correctly handle overly large batches
This bug has been fixed in Kafka version 3.3.0 (but we didn’t test it as it wasn’t available in time).
2. Use Cases for Lots of Partitions
From our experiments, we have demonstrated that Kafka KRaft clusters can support more partitions than Kafka ZooKeeper clusters. But what are some use cases for large numbers of partitions?
Use Case 1: Lots of Topics, Resulting in Lots of Partitions
Lots of topics may be required due to your data model or security requirements (e.g. to restrict Kafka consumer access to specific topics). And of course, each topic has at least 1 partition (more due to replication) so this results in many partitions as well.
Use Case 2: High Throughput
More partitions enable higher Kafka consumer concurrency and therefore higher throughput for Kafka clusters.
Use Case 3: Slow Kafka Consumers
Slow Kafka consumers limit the throughput, so you need to increase the number of consumers to increase throughput.

Shoppers with more groceries take longer at the checkouts, so you need more checkouts to reduce time spent queuing—just like Kafka consumers
However, as we have seen from these experiments, running Kafka clusters with large numbers of partitions is challenging. If you are running Kafka in production you typically use a replication factor of 3 (RF=3), however, increasing partitions with RF=3 results in higher background CPU load on the cluster, and eventually a reduction in cluster throughput, requiring much more cluster resources. Higher throughputs also require more Kafka consumers, so you will end up needing more resources to run consumers on. Other things to watch out for are that more consumers in a group will result in worse consumer group balancing (and rebalancing) performance, and you also have to ensure that you have many more key values than partitions to avoid the chance of partition and consumer starvation.
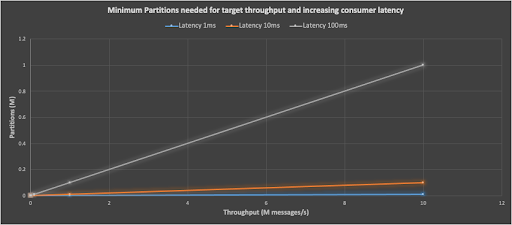
You can use Little’s Law (Concurrency = Throughput x Response Time) to estimate the number of Kafka consumers (concurrency) required to achieve a given target throughput with increasing response time. This graph shows the minimum number of partitions required to achieve increasing target throughputs (x-axis, millions of messages/s) with different consumer latencies (1ms, blue; 10ms, orange; 100ms grey). For a target of 10M messages/s and a latency of 1ms, you only need 10,000 partitions; with a latency of 10ms you need 100,000 partitions; and for a latency of 100ms you will need 1 Million or more partitions and consumers. In general, it’s really important to keep Kafka consumer latencies as short as possible to avoid this scenario.
Are you worried about running Kafka clusters with large numbers of partitions? Well, there is actually a “trick” that can be used to increase the parallelism in Kafka consumers, resulting in higher throughput without having to increase the number of partitions. Kafka consumers are normally single-threaded, but this approach uses a thread pool in the consumers. We previously demonstrated this approach to achieve 19 Billion anomaly checks a day for a demonstration Kafka/Cassandra Anomaly Detection system.
There is an open source Kafka Parallel Consumer available (although we have not evaluated it yet, so you should test it out before use in a production environment, to check if it meets your quality and functionality requirements). Of course, you will still need sufficient partitions to achieve the required producer throughput (from the first blog in this series, 10-1,000 partitions give good producer throughput).
3. Conclusions
Let’s revisit our initial hypotheses about ZooKeeper vs. KRaft, and see what our experiments revealed.
| What | ZooKeeper | KRaft | Results |
| Reads and Therefore Data Layer Operations Cached/Replicated | FAST | FAST | Identical
Confirmed |
| Meta-Data Changes | SLOW | FAST | Confirmed |
| Maximum Partitions | LESS | MORE | Confirmed |
| Robustness | YES | WATCH OUT | OS settings! |
First (from part 1 of this blog series), we confirmed that both ZooKeeper and KRaft clusters have fast, and identical, producer data workloads. These were better results than what we had previously obtained in 2020, and show that a small Kafka cluster can support high producer throughputs with no substantial drop-off up to around 1,000 partitions. Even 10,000 partitions may be practical, although the drop-off in throughput is more noticeable above 1,000 partitions.
Second, several experiments in part 2 of the series proved that KRaft is faster than ZooKeeper for meta-data operations including topic/partition creation and re-partitioning.
Third, as we saw in this part, KRaft can support the creation of Kafka clusters with more partitions than ZooKeeper—potentially 1 Million or more partitions (this is primarily because it’s a lot faster and less error-prone to create more partitions with KRaft).
But, how robust is KRaft for production workloads? We encountered many and varied errors with both ZooKeeper and KRaft, but when using KRaft it’s important to ensure that the Linux OS settings, available RAM, and JVM settings are configured with high enough values to allow for potentially more partitions than what was achievable with ZooKeeper.
Finally, the latest version of Kafka (3.3) is now marked as KRaft production ready (for new clusters) so we can look forward to a faster and more scalable Kafka in the near future (3.3.1 is the latest version available). A KRaft version of Instaclustr for Apache Kafka will be available in the near future.
Missed the earlier blogs? Catch up on the entire ZooKeeper series here!
Part 1: Partitions and Data Performance
Part 2: Partitions and Meta-Data Performance
Looking for enterprise support or consulting services? We’re here to help