What is Apache Kafka?
Apache Kafka is a leading open source, distributed event streaming platform used by over 80% of the Fortune 500. Originally developed by LinkedIn and donated to Apache, Kafka is used by companies requiring high-performance data pipelines, streaming analytics, data integration, and support for mission-critical applications. Kafka’s publish/subscribe model was designed with fault tolerance and scalability in mind, capable of handling over a million messages per second or trillions of messages per day.
This is part of a series of articles about Apache Spark
What is Apache Spark?
Apache Spark is a distributed computing framework designed to perform processing tasks on big data workloads. First introduced as a Hadoop subproject in the UC Berkeley R&D labs in 2009, Spark was donated to Apache in 2013. In-memory caching and optimized query execution for fast analytic queries, makes Spark a popular choice for data engineering, data science, and machine learning projects. Spark provides APIs in Java, Scala, Python, and R, allowing developers to write data processing applications in their preferred language.
In this article:
- Kafka key concepts
- Spark key concepts
- What are the similarities between Kafka and Spark?
- Kafka pros and cons
- Spark pros and cons
- Kafka Streams vs. Structured streaming: 8 key differences
- When to use Kafka or Spark
Kafka key concepts
- Producers: Producers are responsible for data from event generating devices, applications, and other data sources to Kafka topics. As an example, in the case of data streams focused on detecting credit card fraud, producers might include payment processing systems, point of sales systems, payment gateways, and e-commerce platforms.
- Topics: Producers publish events into topics. Topics are categories of data, and consumers subscribe to them. In our credit card fraud detection stream example, transaction data might be stored into “in store” topics, “online” topics, or “ATM withdrawals” topics.
- Partitions: Kafka topics are configured into partitions, which divide the topic into smaller subsets of data. Partitioning helps Kafka achieve scalability, load balancing, and fault tolerance by writing, storing, and processing the partitions across brokers. In our example, the partitions might contain data about a transaction’s amount, location, or time which could be distributed and replicated across Kafka brokers.
- Consumers: Consumers are the applications, platforms, and systems that subscribe to analyze the real-time data stored in Kafka topics. Examples of fraud detection consumers might be fraud detection systems, consumer notification systems, transaction monitoring dashboard, or payment authorization systems.
- Kafka Brokers: Brokers are the Kafka instances where data published by the producer is made available to consumers by subscription. Kafka ensures fault tolerance by replicating data across multiple broker instances. Kafka brokers contain topic log partitions, where data is stored and distributed:
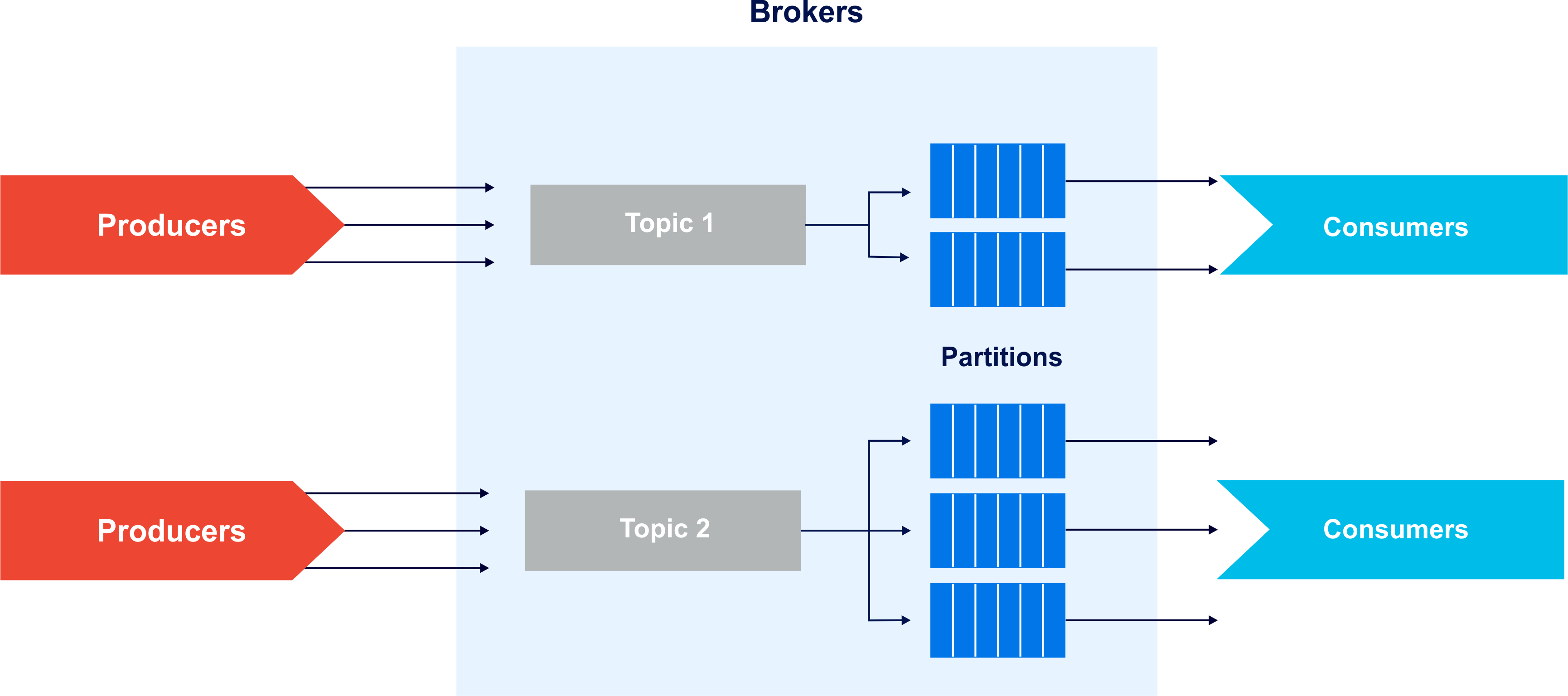
Kafka Brokers (Source: Instaclustr)
Combined, Kafka delivers 3 overarching capabilities: the ability to publish or subscribe to data streams, the ability to process records in real-time, and fault tolerant and reliable data storage. Note: After a message is written to a topic, it cannot be deleted for a preconfigured amount of time (e.g., 7 days) or altered at all.
Related content: Read our guide to architecture of Apache Spark
Kafka Streams
Kafka comes with 5 primary API libraries including:
- Producer API: enables applications to publish data to Kafka topics
- Consumer API: enables applications to subscribe to Kafka topics
- Streams API: enables streaming data transformation between Kafka topics
- Connect API: enables integration with publishers and consumer applications
- Admin API: enables management and review of Kafka objects
Apache Kafka on its own is a highly capable streaming solution. However, Kafka Streams delivers a more efficient and powerful framework for processing and transforming streaming data. As described by IBM, Streams APIs “builds on the Producer and Consumer APIs and adds complex processing capabilities that enable an application to perform continuous, front-to-back stream processing.” Although the Producer and Consumer APIs can be used together for stream processing, it’s the Streams API specifically that allows for advanced event and data streaming applications.
Related content: Read our guide to apache spark streaming
Spark key components
Spark’s ecosystem consists of 5 key components:
- Spark Core: Contains the foundational functionality of Spark, including input-output operations, data transformation, fault tolerance, monitoring, and task scheduling. Spark core provides in-memory computing and references datasets to external storage systems. The core comes with REST APIs, which are language independent.
- Spark SQL: Spark SQL is a Spark module used for processing structured data stored in Spark programs or externally stored structured data accessed via standard JDBC and ODBC connectors.
- As an example, if a car manufacturer were using Spark to measure the effectiveness of a new car ad campaign, they could use Spark SQL to ingest structured data from website analytics, customer surveys, and dealership records. They could then develop SQL queries to correlate when and where ads are run, what the impact the ads had on website performance and ultimately on dealership new car sales performance.
- Streaming: Spark Streaming is responsible for scalable, high-throughput, fault-tolerant processing of live data streams. Spark Streaming applies algorithms like map, reduce, join, and window on data streams, and then pushes the data to destinations such as file systems, dashboards, or databases. Spark Streaming natively supports both batch and streaming workloads.
- In the new car campaign example, streaming data could continuously monitor social media platforms and news websites in real-time and generate alerts to the marketing team of changes in customer or market sentiment.
- MLlib: The MLlib (Machine Learning Library) comes with common learning algorithms for building, training, and deploying machine learning models at scale. The broad set of MLlib algorithms include tasks such as classification, regression, clustering, recommendation, and frequency analysis.
- In our new car campaign example, MLlib could be used to segment customers by their car preferences (i.e., luxury, eco-friendly, safety), region and buying behavior and then could be used to predict future sales and customer demand based on the segmentations.
- GraphX: GraphX is a graph processing library built on top of Spark. GraphX leverages the distributed computing capabilities of Spark, making it an ideal approach for processing and analyzing massive and complex graph-structured data.
- In our example, GraphX could be used to track and visualize user interactions across channels and identify audiences with interest in the campaign, such as auto enthusiasts or tech pundits so that marketing could further hone their messaging to the specific buyer groups.
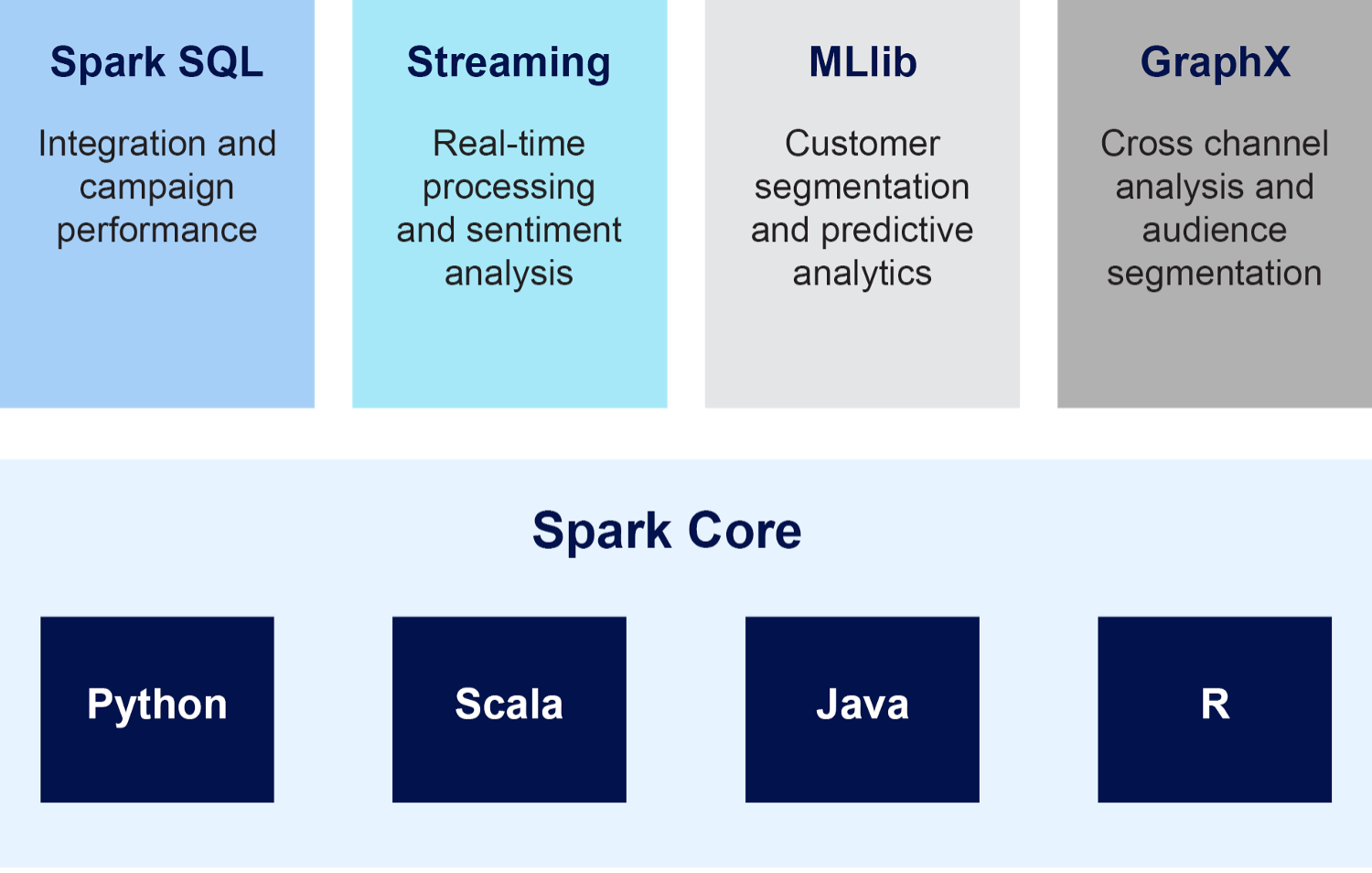
An example of Apache Spark’s architecture designed to measure the effectiveness of a new car ad campaign. The combination of Spark components is used to measure the campaign’s reach and performance (Spark SQL), monitor sentiment in real-time across social media and news sites (Streaming), forecast future sales based on buyer segment (MLib), and visualize target audiences across channels (GraphX). (Source: Instaclustr)
Structured streaming
As of Spark 2.0, Apache launched Structured Streaming. Structured Streaming is generally favored for processing data streams. One reason is that Spark Streaming sends data via micro batches over fixed time intervals, which can add latency. On the other hand, Structured Streaming has lower latency because it sends data on a record-by-record basis as the data is available, it has less data loss because of its event handling capabilities and is generally preferred for developing real-time streaming applications.
What are the similarities between Kafka and Spark?
Apache Kafka and Apache Spark share several commonalities, making them popular choices for handling large-scale, real-time data streams:
- Distributed architecture: Both Kafka and Spark are distributed systems, designed to handle high volumes of data across clusters. This distributed nature ensures fault tolerance, scalability, and the ability to manage data in parallel across multiple nodes.
- Real-time data processing: Kafka and Spark are both designed for real-time processing. Kafka handles real-time event streaming with its publish/subscribe model, while Spark uses its Structured Streaming or Spark Streaming module for processing continuous data streams.
- Fault tolerance and scalability: Kafka and Spark are built with fault tolerance in mind, ensuring reliable data processing even in the case of node failures. Kafka achieves this through data replication across brokers, while Spark achieves it via checkpointing and lineage tracking in its processing jobs. Event time and processing time handling: Both Kafka and Spark offer mechanisms for handling different time-based semantics, such as event time, ingestion time, and processing time. This allows for flexibility in analyzing and processing events as they occur or when they are received.
- Integration capabilities: Kafka and Spark are often used together in the same architecture. Kafka serves as the ingestion and messaging layer, while Spark processes and analyzes the incoming data from Kafka topics. This combination is powerful for building scalable, low-latency data pipelines.
- API libraries for stream processing: Both Kafka and Spark offer APIs for developers to build stream processing applications. Kafka has the Kafka Streams API, while Spark provides the Structured Streaming API, both of which enable developers to work with real-time data streams in a flexible, scalable manner.
Pros and cons of Apache Kafka
Pros:
- High throughput and scalability: Kafka can handle millions of events per second and scale horizontally by adding more brokers. This makes it ideal for use cases requiring high-throughput data pipelines, such as large-scale analytics or IoT data streams.
- Fault tolerance: Kafka’s distributed architecture ensures fault tolerance. Data is replicated across multiple brokers, which allows the system to recover quickly from node failures without data loss.
- Durability: Kafka guarantees message durability by persisting data to disk and keeping messages in topics for a configurable retention period, ensuring that data remains accessible even in the case of consumer failures.
- Low latency: Kafka’s design allows for near real-time event processing, with low-latency transmission of messages from producers to consumers, making it suitable for time-sensitive applications such as fraud detection, live monitoring, or order processing.
- Decoupled systems: Kafka provides a reliable messaging layer that allows producers and consumers to operate independently. This decoupling simplifies the design of complex data pipelines.
- Wide ecosystem: Kafka integrates easily with many systems through Kafka Connect and provides libraries like Kafka Streams, making it a flexible tool for various streaming data use cases.
Cons:
- Complex configuration: Kafka can be complex to configure and tune, especially in larger deployments. Managing partitions, retention policies, and broker configurations requires deep knowledge of Kafka’s internals.
- Lack of built-in data transformation: While Kafka Streams adds stream processing functionality, Kafka itself does not natively support complex data transformations. External frameworks like Apache Flink or Apache Spark are often needed for advanced transformations.
- Limited support for exactly-once semantics: Although Kafka has support for exactly-once semantics in certain scenarios, achieving it requires careful configuration, and it may impact performance.
- Operational overhead: Running Kafka clusters at scale requires significant operational resources, including monitoring, troubleshooting, and ensuring proper replication and partitioning for optimal performance and fault tolerance.
Pros and cons of Apache Spark
Pros:
- Fast in-memory processing: Spark’s in-memory computing model makes it significantly faster for data processing compared to disk-based alternatives like Hadoop MapReduce. This speed is particularly beneficial for iterative algorithms and real-time analytics.
- Unified framework: Spark provides a unified platform for batch processing, stream processing, and machine learning, making it a versatile tool for various big data use cases.
- Rich ecosystem: Spark offers APIs for multiple languages (Java, Scala, Python, and R) and includes libraries like Spark SQL, MLlib for machine learning, and GraphX for graph processing, providing a wide range of functionality in a single framework.
- Fault tolerance: Spark ensures reliability with its Resilient Distributed Datasets (RDDs) and lineage-based fault recovery. Data can be recomputed in case of failures, making Spark highly fault-tolerant.
- Advanced analytics: With built-in support for machine learning and graph analytics, Spark enables advanced data science workflows, such as predictive modeling, customer segmentation, and anomaly detection.
Cons:
- Resource intensive: Spark’s in-memory processing requires significant resources, particularly RAM. This can make it costly to run, especially for large datasets, as scaling Spark workloads may require substantial hardware investments.
- Complex tuning: Spark requires extensive tuning to optimize performance. Tasks such as memory management, caching strategies, and job scheduling can be complex, especially in large-scale or multi-tenant environments.
- Batch-oriented streaming: Despite improvements with Structured Streaming, Spark’s original micro-batch processing model introduces some latency compared to event-driven frameworks like Kafka Streams, which can impact real-time streaming applications.
- Latency for small data: Spark is optimized for large datasets, and when dealing with smaller data volumes, its overhead can result in higher latency compared to lighter-weight solutions like Apache Flink or Kafka Streams.
- Learning curve: While Spark provides powerful features, mastering its API and tuning options can present a steep learning curve, particularly for developers new to distributed computing.
Learn more in our detailed guide to apache spark tuning
Kafka Streams vs Structured streaming: 8 key differences
The release of Structured Streaming enabled Spark to stream data like Apache Kafka. Each platform consumes data as it arrives, making them both suitable low-latency data processing use cases. Both platforms tightly integrate into Kafka: Kafka with its Streams library for building applications and micro services and Structured Streaming can easily be used as a consumer of Kafka topics.
However, there are also differences between the Kafka Stream and Structured Streaming which are important to note:
| Kafka Streams | Spark Structured Streaming | |
| 1. Primary Objective | Streams is a foundation component built into Kafka | Structured Streaming is library that enables streaming for Spark |
| 2. Performance | With inherent data parallelism, scalability, and built-in fault tolerance, Kafka Streams is faster and easier to use than most platforms | Spark Streaming offers high-throughput, scalable, and fault-tolerant processing, but requires regular performance tuning in order to scale. |
| 3. Processing Model | Streams event-driven model processing | Supports micro-batched and event-driven models |
| 4. Programming Language | Natively, the Kafka Streams API supports Java and Scala | Spark Streaming provides API libraries in Java, Scala, and Python |
| 5. Integration | Kafka Streams is designed to import and process data provided by Kafka topics, but can export to a variety of systems, including Kafka® Connect. | Structure Streaming can import and export to a variety of applications and devices. |
| 6. Machine Learning | Kafka does not have a built-in machine learning library for applying ML algorithms to streaming data. You can use an external ML library or system with Kafka, but it may not be as straightforward as Spark’s MLlib | Spark comes with a machine learning library (MLlib) that offers a suite of algorithms that can inject machine learning into streaming data processing workflows. This could enable you to apply machine learning to streaming data for tasks like real-time prediction. |
| 7. Data Processing | Data processing based on:
Event time Ingestion time Processing time |
Data processing based on:
Event time Ingestion time Processing time |
| 8. Fault Tolerance | Uses Kafka topics as changelog topics to store application state | Uses checkpointing to maintain processing state |
When to use Kafka or Spark?
The streaming solution you use depends on a variety of factors. If you want to analyze the streaming data against multiple other data sources, run analytics against the data, or train the data against a machine learning model, then Spark Structured Streaming is a good choice.
Kafka Streams are good options where ultra-low latency is required, simple tasks such as data filtering, routing or transforming is required, and where high data throughput is needed. But ultimately, the decisions should come down to your existing architecture, use cases, and platform experience.
Final thoughts: Kafka or Spark?
Apache Kafka and Apache Spark are both powerful open source data processing platforms that are the true leaders at what they are designed to do: data streaming and large-scale data analytics, respectively.
It’s not a matter of which open source tech is “the best”; instead, it’s all about which technology is best for your particular use case.
Ready to experience how Kafka can unlock the hidden value within your dataset? Contact our open source experts and let’s discuss your particular use case.
Want to experience these open source technologies for yourself? Spin up your first cluster for free on the Instaclustr Managed Platform and get started today.