Kafka Streams is a client library providing organizations with a particularly efficient framework for processing streaming data. It offers a streamlined method for creating applications and microservices that must process data in real-time to be effective. Using the Streams API within Apache Kafka, the solution fundamentally transforms input Kafka topics into output Kafka topics. The benefits are important: Kafka Streams pairs the ease of utilizing standard Java and Scala application code on the client end with the strength of Kafka’s robust server-side cluster architecture.
This is part of a series of articles about Apache Kafka-IR
Kafka Streams Advantages
Kafka’s cluster architecture makes it a fault-tolerant, highly-scalable, and especially elastic solution—able to handle hundreds of thousands of messages every second. It can be readily deployed on the cloud in addition to container, VMs, and bare metal environments, and provides value to use cases large and small. Kafka Streams utilizes exactly-once processing semantics, connects directly to Kafka, and does not require any separate processing cluster. Developers can leverage Kafka Streams using Linux, Mac, and Windows environments, and by writing standard Java or Scala applications. Kafka Streams is also fully integrated with Kafka Security, making it a secure and enterprise-trusted solution for handling sensitive data. Kafka Streams real-time data streaming capabilities are used by top brands and enterprises, including The New York Times, Pinterest, Trivago, many banks and financial services organizations, and more.
Learn more in our detailed guide to apache kafka cluster
Best yet, as a project of The Apache Foundation Kafka Streams is available as a 100% open source solution. That means Kafka Streams delivers all the benefits of a proven open source technology that’s fully backed and iteratively improved on by Kafka’s particularly active open source community. As a real-time data streaming solution, leveraging Kafka Streams in its 100% open source form protects businesses from the risks of vendor and technical lock-in associated with other proprietary and “open core” data-layer offerings.
Stream Processing—What Is It?
Stream processing encompasses continuous streams of data to recognize specific values and conditions—near instantaneously—upon that data’s arrival. Often associated with big data, stream processing is also characterized as real-time analytics, event processing, and other related terms. Stream processing provides value through the rapid analysis of data that quickly yields useful (and actionable) insights. However, take note that some use cases require more rapid processing than others in order for those insights to provide value. Stream processing is capable of ensuring that processing is completed and insights are available within milliseconds.
There are additional reasons you will want to leverage stream processing. In scenarios where event data arrives in unending streams, the idea of capturing and storing that data, then interrupting data capture at certain points in order to process particular batches and then reassembling data across those batches after processing becomes complicated very quickly. Stream processing inherently and easily overcomes these challenges. Time series data and other continuous data series use cases are an apt fit for stream processing, which makes it simple to recognize patterns within data and to view data at multiple levels (and even from multiple streams) all at once.
Stream processing is also the best and possibly only option when dealing with incoming data so large in size that it cannot be stored. Even facing tremendous fire hoses of data, stream processing offers the capability to leverage high velocity information for useful insights. Considering the high potential for Internet of Things (IoT) and other high data volume use cases that will be crucial to the success of businesses across industries in the near future (or indeed already is), pursuing stream processing capabilities to handle those use cases is a prudent choice.
That said, not every use case is congruent with stream processing as a solution. Processing tasks such as AI/ML algorithm training models, or those that include random access or require multiple passes through data sets, likely will not be appropriate candidates for stream processing.
Learn more in our detailed guide to Kafka management
Kafka and Kafka Streams
Apache Kafka includes four core APIs: the producer API, consumer API, connector API, and the streams API that enables Kafka Streams.
It is possible to achieve high-performance stream processing by simply using Apache Kafka without the Kafka Streams API, as Kafka on its own is a highly-capable streaming solution. Doing so would mean writing code with a Kafka consumer to read data from a topic (a source of data), performing data processing, and writing those processed-data insights back to another topic using a Kafka producer. However, Kafka Streams offers the advantage of abstracting the complexity of maintaining those consumers and producers, freeing developers to focus instead on the stream processor logic. The aggregations joins, and exactly-once processing capabilities offered by Kafka Streams also make it a strategic and valuable alternative.
Learn more about Data architecture principles
Key Concepts
Kafka Streams can be stateless: it responds to events without regard for previous events or states. Importantly, though, it can also leverage processing that is stateful, accounting for time duration through the use of windows, and for the state, by turning streams into tables and then back into streams.
Core Kafka Streams concepts include topology, time, keys, windows, KStreams, KTables, domain-specific language (DSL) operations, and SerDes.
Topology
Streams are unbounded, ordered, replayable, continuously updating data sets that consist of strongly typed key-value records. A processor topology includes one or more graphs of stream processors (nodes) connected by streams (edges) to perform stream processing. In order to transform data, a processor receives an input record, applies an operation, and produces output records.
A source processor receives records only from Kafka topics, not from other processors. A sink processor sends records to Kafka topics, and not to other processors.
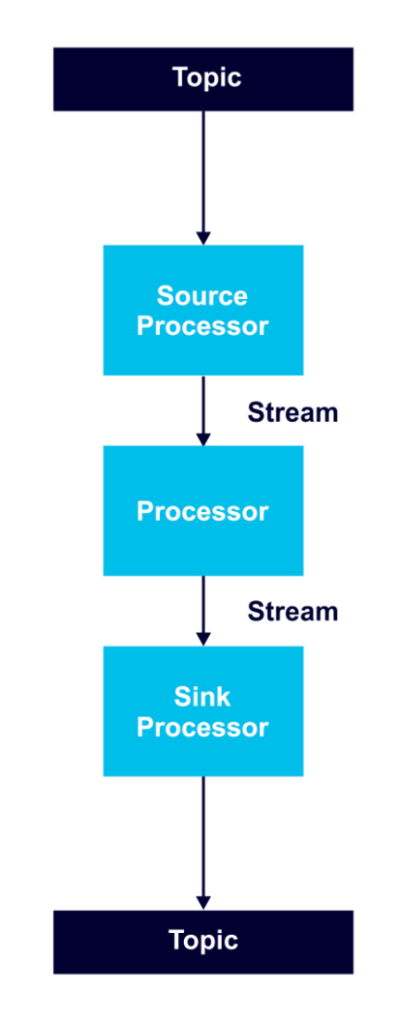
Processor nodes can run in parallel, and it’s possible to run multiple multi-threaded instances of Kafka Streams applications. However, it’s necessary to have enough topic partitions for the running stream tasks, since Kafka leverages partitions for scalability.
Stream tasks serve as the basic unit of parallelism, with each consuming from one Kafka partition per topic and processing records through a processor graph of processor nodes.
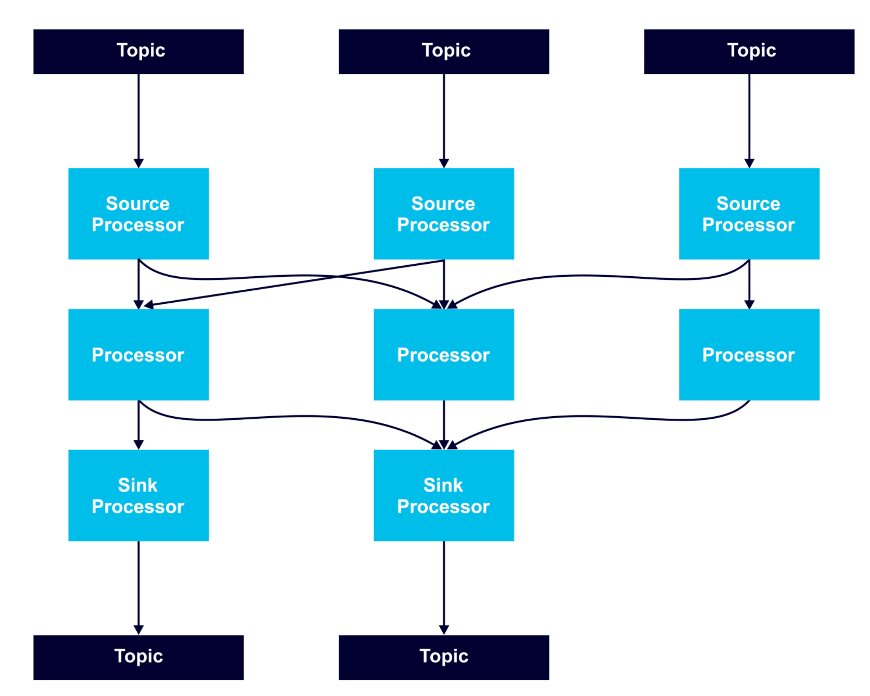
To keep partitioning predictable and all stream operations available, it’s a best practice to use a record key in records that are to be processed as streams.
Time
Time is a critical concept in Kafka Streams. Streams operations that are windowing-based depend on time boundaries. Event time is the point in time when an event is generated. Processing time is the point in time when the stream processing application consumes a record. Ingestion time is the point when an event or record is stored in a topic. Kafka records include embedded time stamps and configurable time semantics.
Domain-Specific Language (DSL) built-in abstractions
There are three types of streams operations:
- functional operations provided by the built-in Streams DSL,
- lower-level procedural operations defined by the Processor API, and
- those produced using proprietary methods, such as KSQL
The Streams DSL offers streams and tables abstractions, including KStream, KTable, GlobalKTable, KGroupedStream, and KGroupedTable.
Developers can leverage the DSL’s declarative functional programming style to easily introduce stateless transformations such as map and filter operations, or stateful transformations such as aggregations, joins, and windowing.
KTables
KTables make it possible to keep and use a state. They have key/value rows that retain each key’s latest value. Records that are incoming provide a changelog stream—delivering new inserts, updates, and deletes. Each KTable is populated from assigned input data partitions only; input topic partitions are collectively read and processed across all instances of an application. That said, each application instance’s local GlobalKTable instance is populated with data from all input topic partitions.
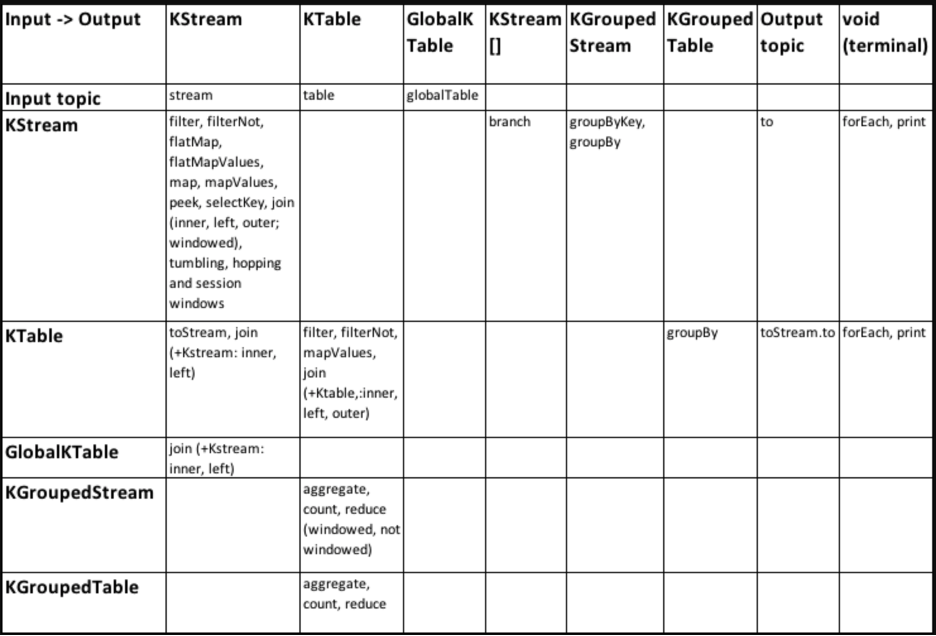
DSL Operations
The following table offers a quick-and-easy reference for understanding all DSL operations and their input and output mappings, in order to create streaming applications with complex topologies:
SerDes
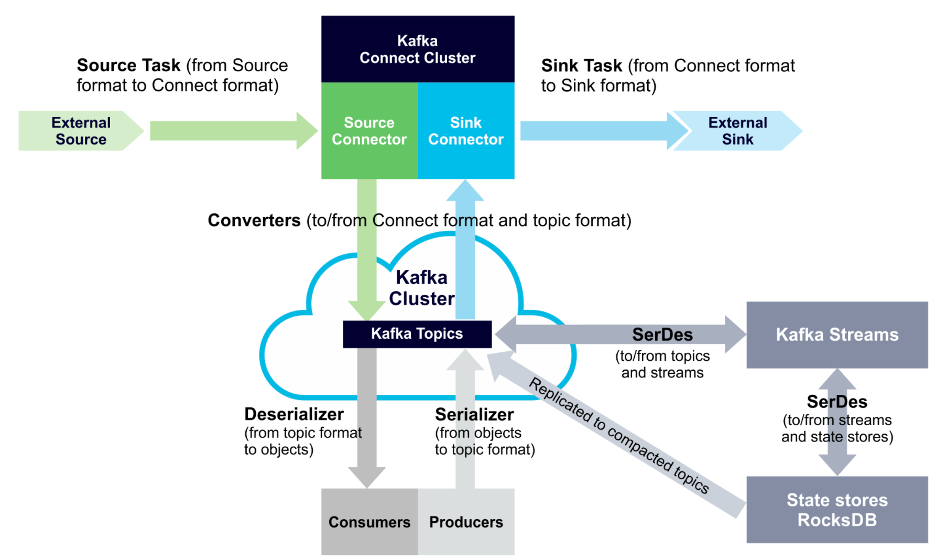
Kafka Streams applications need to provide SerDes, or a serializer/deserializer when data is read or written to a Kafka topic or state store. This enables record keys and values to materialize data as needed. You can also provide SerDes either by setting default SerDes in a StreamsConfig instance, or specifying explicit SerDes when calling API methods.
The following diagram displays SerDes along with other data conversion paths:
Architecture
Kafka Streams leverages Kafka producer and consumer libraries and Kafka’s in-built capabilities to provide operational simplicity, data parallelism, distributed coordination, and fault tolerance.
This diagram displays the architecture of a Kafka Streams application:
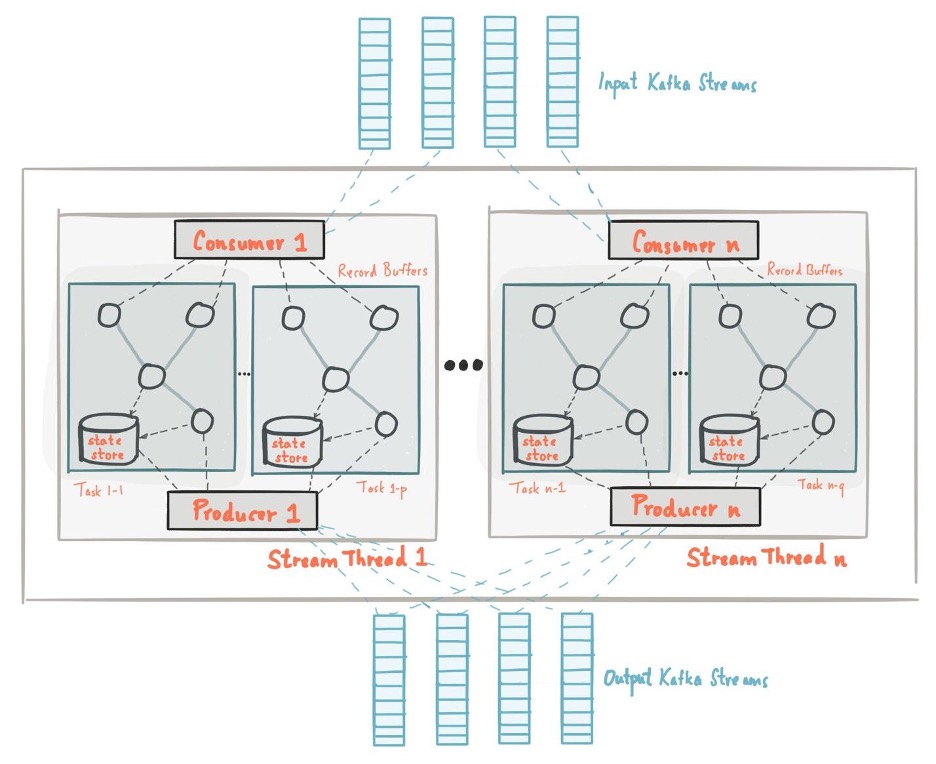
Stream Partitions
Kafka Streams partitions data for processing—enabling scalability, high performance, and fault tolerance. A stream partition is an ordered sequence of data records that maps to a Kafka topic partition. Each data record in a stream maps to a Kafka message from the topic. Data record keys determine the way data is routed to topic partitions.
The processor topology of an application can scale by dividing it into multiple tasks. Each task is able to be processed on its own and in parallel, automatically. An application can be run with as many instances as there are partitions in the input topic. Each instance contributes to processing the data in the topic. Instances in excess of the number of partitions will run as idle and will take on the work of any instance that goes down.
Kafka Streams assigns topic partitions to tasks, and tasks to all threads in all instances, in order to achieve both load-balancing and give stickiness to stateful tasks.
Stream Threading
Developers can configure the number of threads Kafka Streams uses for parallel processing in an application instance. A thread can independently execute one or multiple stream tasks, and because threads have no shared state, coordination among threads isn’t required. Kafka Streams automatically handles the distribution of Kafka topic partitions to stream threads.
Local State Stores
Kafka Streams includes state stores that applications can use to store and query data. This is useful in stateful operation implementations. For instance, the Streams DSL creates and manages state stores for joins, aggregations, and windowing. Stream tasks can embed local state stores, accessible by API, to store and query data that’s necessary to processing.
Fault Tolerance
Just like Kafka itself, in which partitions are replicated and highly available, Kafka Streams streaming data persists even through application failures. Kafka Streams will automatically restart tasks running on failed application instances using a working instance. Local state stores are similarly kept failure resistant.
Scaling Out
Kafka Streams applications can scale out simply by distributing their load and state across instances in the same pipeline. While aggregation results are then spread across nodes, Kafka Streams makes it possible to determine which node hosts a key and allows the application to collect data from the correct node or send the client to the correct node.
Interactive Queries
With an application existing in numerous distributed instances—and each including locally managed state stores—it’s useful to be able to query the application from outside of it. For this purpose, Kafka Streams makes applications queryable with interactive queries. Developers can effectively query local state stores of an application instance, including local key-value stores, local window stores, and local custom state stores. Alternatively, developers can query remote state stores across the full app by adding an RPC layer in the application, exposing the application’s RPC endpoints, and discovering application instances and their local state stores.
Implementing Kafka Streams
Here is an in-depth example of utilizing the Java Kafka Streams API complete with sample code. In this example, the application will count how many times certain words appear in a Kafka topic.
To begin, add the Kafka package to your application as a dependency:
|
1 2 3 4 5 |
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>1.1.0</version> </dependency> |
Configuring Kafka Streams
Some basic configuration options must be set before using the Streams API. For this example, make a streams.properties file with the content below. Be sure to change the bootstrap.servers list to include your own Kafka cluster’s IP addresses.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Kafka broker IP addresses to connect to bootstrap.servers=54.236.208.78:9092,54.88.137.23:9092,34.233.86.118:9092 # Name of our Streams application application.id=wordcount # Values and Keys will be Strings default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerde # Commit at least every second instead of default 30 seconds commit.interval.ms=1000 |
If connecting to your Kafka cluster using a private network, it’s necessary to use 9093 rather than 9092. It may also be necessary to provide authentication credentials (this is the case if using Kafka on Instaclustr). Clusters with client-broker encryption in place will also require encryption credentials.
Include the following code in the streams.properties file, using your own truststore location and password:
ssl.enabled.protocols=TLSv1.2,TLSv1.1,TLSv1 ssl.truststore.location = truststore.jks ssl.truststore.password = instaclustr ssl.protocol=TLS security.protocol=SASL_SSL sasl.mechanism=SCRAM-SHA-256 sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username=”ickafka” \ password=”64500f38930ddcabf1ca5b99930f9e25461e57ddcc422611cb54883b7b997edf”
Alternatively, if client-broker encryption isn’t enabled on your cluster, use the following code (with the correct credentials).
|
1 2 3 4 5 |
security.protocol=SASL_PLAINTEXT sasl.mechanism=SCRAM-SHA-256 sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \ username="ickafka" \ password="361d4871ff1a5ef58deaf3b887b4898029faee9690e62c549078a1f51f18f755"; |
Create the Streams Application
To build a Kafka Streams application, begin by loading the properties defined above.
|
1 2 3 4 5 6 7 |
Properties props = new Properties(); try { props.load(new FileReader("streams.properties")); } catch (IOException e) { e.printStackTrace(); } |
For this project, we’ll create a new input KStream object that’s on the wordcount-input topic.
|
1 2 |
StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> source = builder.stream("wordcount-input"); |
Next, we’ll build a word count KStream that determines how many times words occur.
|
1 2 3 4 5 6 7 |
final Pattern pattern = Pattern.compile("\\W+"); KStream counts &nbsp;= source.flatMapValues(value-> Arrays.asList(pattern.split(value.toLowerCase()))) .map((key, value) -> new KeyValue<Object, Object>(value, value)) .groupByKey() &nbsp;&nbsp;&nbsp; .count(Materialized.as("CountStore")) .mapValues(value->Long.toString(value)).toStream(); |
The following line of code directs the word count KStream output to a topic called wordcount-output.
|
1 |
counts.to("wordcount-output"); |
Lastly, create the KafkaStreams object and start it.
|
1 2 |
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start(); |
Create the Input Topic
With the Kafka Streams application prepared, we need to set up a topic from which the application can read input.
Create a new Kafka topic named wordcount-input, with a single partition and a replication factor of 1. (For help on creating a new topic, refer to our guide available here.)
Create Input
Set up a Kafka console producer (guide here), which produces messages to the wordcount-input topic. Use it to send input to Kafka that includes repeated words. For example:
|
1 2 |
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start(); |
Launch the Kafka Streams Application
Now, run the Streams application. It runs until stopped.
Consume the Application’s Output
The Streams application is finding the word counts included in the input text. Now we’ll view that output by setting up a Kafka console consumer for the wordcount-output topic (guide here).
When ready (allow up to a minute for the first output to arrive), the consumer output will include word counts that the Streams application has produced.
|
1 2 3 4 5 6 7 8 9 |
How 1 much 2 as 2 if 2 a 4 woodchuck 4 could 4 chuck 4 wood 4 |
Note that the Streams application outputs word counts only for the most recent message. For instance, producing “chuck the woodchuck chucked wood” as new input results in this output:
|
1 2 3 4 5 |
chuck 5 the 1 woodchuck 5 chucked 1 wood 5 |
There you have an example of a completed functional Kafka Streams application. By mimicking this example, you can leverage Kafka Streams to create highly-scalable, available, and performant streaming applications able to rapidly process high volume data and yield valuable insights.

Master Apache Kafka with expert insights
Struggling to strike the perfect balance between performance, scalability, and reliability in your Kafka ecosystem? Whether you're optimizing for zero downtime or maximizing resource efficiency, this guide has you covered.