Intro
We’ve seen in previous articles some of the ways in which Cadence® makes it easy to create powerful, complex, and reliable workflows.
We have also compared it to other workflow technologies, such as Conductor and Apache Airflow, but solutions like Cadence primarily compete against in-house solutions and companies doing it themselves.
It is perfectly normal, even ideal, for something small to grow into a complex system over time, but it eventually becomes challenging to onboard new starters and difficult to scale and support.
Instaclustr and Cadence
Instaclustr is no different! We began building our system for provisioning clusters 7 years ago. At that time, we only supported AWS for creating Apache Cassandra® clusters. Since then, the system has evolved to incorporate more cloud providers like GCP and Azure. It also has been updated to support more products like Apache Kafka®, PostgreSQL®, and even Cadence itself, just to name a few.
When we first discovered Cadence, the use case I immediately thought of was how we could use it to power our provisioning system. Not for any particular flaw—the solution we have now is proven, highly performant, and modular. However, I felt it was a great example of the types of problems Cadence was created to solve.
Fast forward to today, and I am lucky enough to be in the position to put my money where my mouth is; and in this article I am going to replicate a small, but meaningful, portion of our cluster provisioning system in Cadence.
We will then take a look at the various ways that Cadence saves, or perhaps increases, developer effort and, if it can be quantified, the cognitive load it helps to alleviate.
This was super fun for me! Let’s dive in!
What’s a Cluster, Precious?
Let’s quickly describe our provisioning system and what it’s designed to do.
Instaclustr offers a turn-key solution for creating clusters for distributed systems like Kafka and Cassandra. Customers can use the Console or REST API to trigger our provisioning system and, in a few minutes, have a running database ready to use for their production level requirements.
This is no mean feat!
There are a bunch of considerations to align here, first amongst them is creating the infrastructure the customer needs, where they want it.
- 15 AWS i3.xlarge Cassandra 4.0 instances in us-west-2? Ok.
- 6 GCP n-standard OpenSearch 2.0 nodes in Germany, with no public IP addresses? Done!
- 3 on premises nodes of Kafka 3.11 in your custom data centre in Brazil? Erm.. it’s tricky but we can do it!
Second to the infrastructure are the instances; we need to be able to monitor the health of these nodes, upgrade their operating system, and perform maintenance operations.
All of these services are facilitated by the information we capture during provisioning.
- We can’t troubleshoot a data transfer problem if we didn’t accurately capture the id of the NAT gateway that was setup for your private network cluster.
- You might need to migrate to a different region, and we will need to tear down this infrastructure, leaving nothing running that will cost you money in your account.
All of this shows that our provisioning system is critical to the success of Instaclustr, now and into the future. It has many responsibilities and a single failure or misconfiguration can have detrimental downstream effects.
Let’s go ahead and build it again, but this time better.
Glance Behind the Curtain
Ok now we know what our provisioning system does, let’s discuss HOW we built it, while carefully avoiding divulging business information that will get me into trouble.
A lot of the Instaclustr “back end”, as it were, is built in Java, including the provisioning system. This is convenient, because we will be using the Cadence Java SDK when we replicate it. Almost like I chose it for that very reason!
Ok but how did we build it to support different cloud services, and ensure it is as resilient as possible to failure?
Broadly, it consists of a few components.
PostgreSQL Database
This is the source of truth for a cluster. The account owner, cluster name, number of nodes, cloud provider, running applications etc. is all in here. Any time we are creating, updating, or removing infrastructure components, this database must be updated otherwise we are in trouble.
RabbitMQ
We use RabbitMQ as our message broker internally for dispatching requests for new infrastructure. It ensures that if the provisioning system is offline for any reason, we won’t lose any requests that were enqueued but not processed.
You might notice we aren’t using Kafka here. Could we? Sure. Kafka wasn’t really around when we started, and RabbitMQ has proven itself to be sufficient for our purposes.
Provisioning Service
This is the monolithic microservice™ responsible for doing the work of creating infrastructure in the cloud providers, and it’s written in Java. For the purposes of this article, I’m going to focus on how we implemented the AWS provisioning logic, but it’s essentially the same for GCP and Azure.
The Wheels in Motion
At a high level, our architecture is as follows.
1. A request comes in via RabbitMQ to create a new cluster
2. We grab the details of the cluster out of the PostgreSQL database
3. Using the decorator pattern, we create a set of java futures based on the cloud service provider we intend to use, e.g. AWS
-
- This first set of tasks configures the initial infrastructure that will hold our server instances, in AWS this involves creating a VPC and the required infrastructure around it.
4. We then call these futures and wait for them to complete.
The futures themselves are all called in parallel, and some of them consume the results of other futures and will wait until their required data is available.
-
- If any of these tasks fail, a new set of rollback tasks are created and executed to delete anything that was created.
5. Once completed, a new message will be sent via RabbitMQ to create the individual nodes.
6. This pattern is repeated for the node provisioning logic.
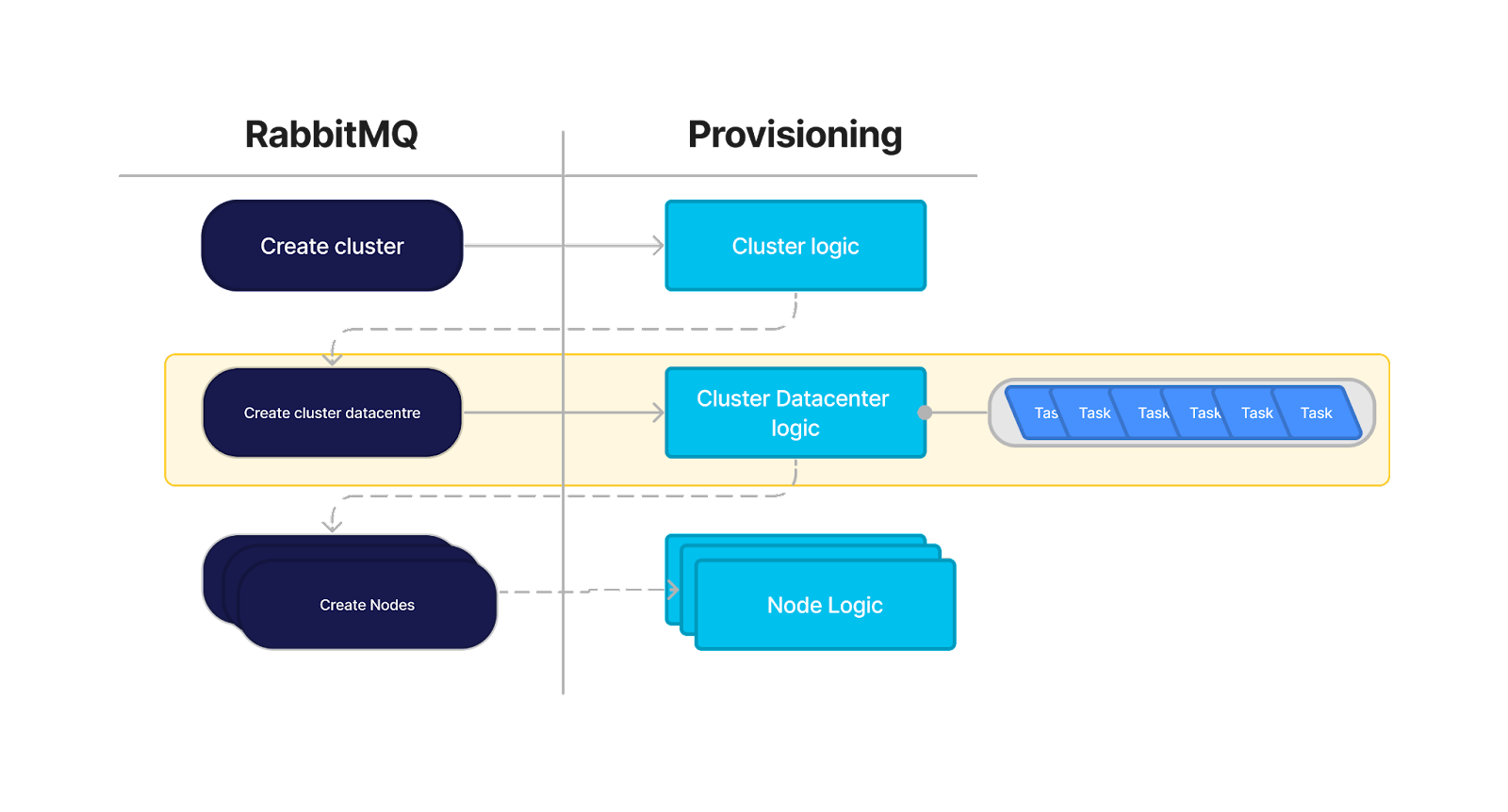 Fig 1: Provisioning example
Fig 1: Provisioning example
This is a simplistic summary of the design and we will see it in a bit more detail later. However, it should highlight the nature of our approach.
It is highly parallelized, ensuring that everything is provisioned as efficiently as possible, but it’s somewhat fragile, a single failure will roll back the entire operation.
We have some resilience to service failure with RabbitMQ, but it’s not quite as granular as we’d like it to be. If a task in the VPC provisioning fails (yellow section in Fig. 1), the entire process is rolled back. In some circumstances, we will be rolling back infrastructure that we will need to then recreate when we resolve the underlying issue.
All of these things we can make better with Cadence!
Getting to the Point
Ok let’s get specific and take a look at some Java code for the provisioner, and then implement that same logic using Cadence. Then we can compare the 2 implementations and make some observations.
We’ll do this in 3 parts, starting with the code that handles the request to create a new cluster.
Provisioning Handler
Native Java Version
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
protected void run(final ClusterDataCentre clusterDataCentre) throws Exception { logger.info("Provision cluster data centre operation started."); // Check all preconditions for cluster provisioning are met validateCdcProvisioning(clusterDataCentre); try { // Get cloud provider specific controller final ClusterDataCentreController clusterDataCentreController = clusterDataCenterControllerProvider.get(clusterDataCentre); // execute the tasks taskExecutor.executeTasks(decorateTasksWithStatusUpdater( clusterDataCentreController.dataCentreProvisioningTasks(clusterDataCentre), progress -> postgresService.setCdcDetails(clusterDataCentre, progress, "Provisioning data centre"))); // All the tasks have completed, update the status postgresService.setCdcStatus(clusterDataCentre, Status.PROVISIONED); } catch (final ProviderOverCapacityException e) { // The cloud provider has encountered capacity problem // It requires manual intervention to resolve postgresService.markCdcDeferred(clusterDataCentre, DeferredReason.CAPACITY); // Delete everything we created executeRollback(clusterDataCentre); } catch (final Exception e) { // Delete everything we created executeRollback(clusterDataCentre); postgresService.setCdcStatus(clusterDataCentre, Status.FAILED); throw e; } logger.info("Provision cluster data centre operation complete."); } |
As we described before, this is the starting point for our cluster provisioning tasks. This snippet is truncated slightly, some of the validation tasks and other plumbing is obfuscated for readability but it is an accurate representation of the process each cluster goes through.
It’s important to note, in a failure scenario the entire set of operations will be rolled back. We will refer to this later in the article.
Now let’s look at how it translates to Cadence.
Cadence Java Version
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
public void provisionCdc(CdcInfo cdc) { // Setup the cadence interface final CdcActivities activities = Workflow.newActivityStub(CdcActivities.class, new ActivityOptions.Builder() .setRetryOptions(new RetryOptions.Builder() .setInitialInterval(Duration.ofSeconds(10)) .setMaximumAttempts(3) .build()) .setScheduleToCloseTimeout(Duration.ofMinutes(5)).build()); logger.info("Provision cluster data centre operation started."); // Check all preconditions for cluster provisioning are met validateCdcProvisioning(cdc); // Create a child workflow, sending to a tasklist with a worker dedicated to // implementing that provider ProviderCdcProvisioningWorkflow provisioningWorkflow = Workflow.newChildWorkflowStub( ProviderCdcProvisioningWorkflow.class, new ChildWorkflowOptions.Builder() .setTaskList(String.format("%s-cdc-provisioning", cdc.provider)) .build()); // call synchronously and wait for result ProvisioningResult result = provisioningWorkflow.provisionCdc(cdc); if (result.provisioningSuccessful()) { activities.updateCdcStatus(cdc.id, Status.PROVISIONED, null); } else if (result.getError().getMessage().contains("capacity")) { activities.updateCdcStatus(cdc.id, Status.DEFERRED, DeferredReason.CAPACITY); } else { activities.updateCdcStatus(cdc.id, Status.FAILED, null); } logger.info("Provision cluster data centre operation complete."); } |
On face value, it’s a pretty similar implementation. This is great! It means the barrier to entry for a new Cadence developer is low, everything “looks” how you would expect.
The key difference here is how we are encapsulating the tasks required for each cloud service.
We can see on line 18 we are starting a child workflow. Child workflows are great ways to encapsulate parcels of work and open up a few options for us as well.
Here, we are implementing different logic depending on what task list we are using (line 21). The parent workflow doesn’t know, or care, how this child workflow is implemented.
We are driving “how” based on the task list. For AWS, we will send it to the AWS specific task list. On the other end of the task list, we will create a worker that implements the ProviderCdcProvisioningWorkflow interface and returns the result.
Analysis
Here we can see the first advantage Cadence offers us over the old code base.
Using the old method, we essentially had a switch statement that checked where the customer wanted their cluster, and then it created the instance of the interface for that cloud provider and loaded up the tasks, executed them and returned them.
If we wanted to add support for a new cloud provider, we needed to update this switch statement, create the implementation code, and deploy the provisioner again. There is a tight coupling.
With Cadence, this coupling is much looser. Tomorrow, if we need to start supporting Azure, the parent workflow doesn’t need to change at all.
Now, the old code could have replicated some of this behaviour using RabbitMQ. We could create a queue per cloud provider, and send the traffic to each one.
This doesn’t come for free though, we would have to set up a new queue in RabbitMQ, register it to the correct exchange, ensure it has the correct settings. It essentially becomes an infrastructure task to scale it out. If you aren’t an expert at RabbitMQ, this is a time-consuming process.
With Cadence, we just need to assign it to a task list and it will handle the rest.
AWS Provisioning Logic
Let’s move onto the code that actually creates the infrastructure. Instaclustr’s provisioning system was built on v1 of the AWS Java SDK, so we will keep it the same in our Cadence implementation.
Native Java Version
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
public Iterable<ListenableFutureTask<?>> dataCentreProvisioningTasks(final ClusterDataCentre clusterDataCentre) { final ImmutableSet.Builder<ListenableFutureTask<?>> provisionTasks = ImmutableSet.builder(); final ListenableFutureTask<InstanceProfile> createInstanceProfileTask = create(awsvpcTaskFactory.generateCreateInstanceProfileTask(iamClient, clusterDataCentre)); final ListenableFutureTask<Role> createRoleTask = create(awsvpcTaskFactory.generateCreateRoleTask(iamClient, clusterDataCentre)); final ListenableFutureTask<Void> addInstanceProfileToRoleTask = create(awsvpcTaskFactory.generateAddInstanceProfileToRoleTask(iamClient, clusterDataCentre, createInstanceProfileTask, createRoleTask)); final ListenableFutureTask<Vpc> createVPCTask = create(awsvpcTaskFactory.generateCreateVPCTask(ec2Client, clusterDataCentre)); final ListenableFutureTask<InternetGateway> createInternetGatewayTask = create(awsvpcTaskFactory.generateCreateInternetGatewayTask(ec2Client, clusterDataCentre, createVPCTask)); provisionTasks.add(createInstanceProfileTask) .add(createRoleTask) .add(addInstanceProfileToRoleTask) .add(createVPCTask) .add(createInternetGatewayTask); final ListenableFutureTask<List<Subnet>> createRackSubnetsTask = create(awsvpcTaskFactory.generateCreateRackSubnetsTask(ec2Client, clusterDataCentre, createVPCTask)); provisionTasks.add(createRackSubnetsTask); final ListenableFutureTask<RouteTable> createMainRouteTableTask = create( awsvpcTaskFactory.generateConfigureNewRouteTableTask( ec2Client, clusterDataCentre, createVPCTask, mainRouteTableGatewayId)); final ListenableFutureTask<Void> associateMainRouteTableToRackSubnetsTask = create( awsvpcTaskFactory.generateAssociateRouteTableToSubnetTask( ec2Client, clusterDataCentre, createMainRouteTableTask, Futures.transform( createRackSubnetsTask, subnets -> Lists.transform(subnets, Subnet::getSubnetId), MoreExecutors.directExecutor()))); provisionTasks.add(createMainRouteTableTask); provisionTasks.add(associateMainRouteTableToRackSubnetsTask); return provisionTasks.build(); } |
Here we have some more simplified code of our provisioning logic. The main takeaway from this code is how we ensure as much parallelism as possible by encapsulating everything in its own java future.
Tasks can also accept futures as a parameter, and this is how we configure dependencies.
The entire collection of futures is returned to the caller and they are executed in parallel. However, in reality, many of them end up progressing sequentially as their dependency chain is satisfied.
Not shown here are the rollback tasks that get generated when a failure is encountered. The rollback tasks are essentially generated the same way, but in reverse order.
Cadence Java Version
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
public ProvisioningResult provisionCdc(CdcInfo cdc) { final AwsCdcProvisioningActivities activities = Workflow .newActivityStub(AwsCdcProvisioningActivities.class, new ActivityOptions.Builder() .setRetryOptions(new RetryOptions.Builder() .setInitialInterval(Duration.ofSeconds(2)) .setMaximumAttempts(10) .build()) .setScheduleToCloseTimeout(Duration.ofMinutes(5)) .build()); Saga.Options sagaOptions = new Saga.Options.Builder().setParallelCompensation(false).build(); Saga saga = new Saga(sagaOptions); try { // Instance Profile activities.createInstanceProfile(cdc); saga.addCompensation(activities::deleteInstanceProfile, cdc); Promise<String> instanceProfileNameTask = Async.function(activities::getRoleByName, cdc); // Role activities.createRole(cdc); saga.addCompensation(activities::deleteRole, cdc); Promise<String> roleNameTask = Async.function(activities::getRoleByName, cdc); Promise.allOf(instanceProfileNameTask, roleNameTask).get(); // Add IP to Role activities.addRoleToInstanceProfile(cdc, instanceProfileNameTask.get(), roleNameTask.get()); saga.addCompensation(activities::removeRoleFromInstanceProfile, cdc, instanceProfileNameTask.get(), roleNameTask.get()); // Vpc String vpcId = activities.createVpc(cdc); saga.addCompensation(activities::deleteVpc, cdc, vpcId); activities.modifyVpc(cdc, vpcId); // Internet Gateway String igwId = activities.createInternetGateway(cdc, vpcId); saga.addCompensation(activities::deleteInternetGateway, cdc, igwId); activities.verifyInternetGateway(cdc, igwId); activities.attachInternetGateway(cdc, vpcId, igwId); saga.addCompensation(activities::detachInternetGateway, cdc, vpcId, igwId); // Rack Subnets List<String> subnets = activities.createRackSubnets(cdc, vpcId); for (String s : subnets) { saga.addCompensation(activities::deleteRackSubnet, cdc, s); } // Route table String routeTableId = activities.createRouteTable(cdc, vpcId, igwId); saga.addCompensation(activities::deleteRouteTable, cdc, routeTableId); // Routing List<Promise<Void>> routing = new ArrayList<>(); for (String s : subnets) { routing.add(Async.procedure(activities::associateMainRouteTableToRackSubnet, cdc, routeTableId, s)); } Promise.allOf(routing).get(); return new ProvisioningResult(true, null); } catch (ActivityException e) { saga.compensate(); return new ProvisioningResult(false, e); } } |
The first thing you will notice is we are taking advantage of the saga pattern. Cadence has a built-in framework for this, and we can see in line 12 that we are creating a Saga and adding new compensation tasks to it after each successful task completes. If a failure is encountered, we execute the saga compensation in reverse of the order in which they are added.
This contrasts with how our legacy code handles rollbacks, where the whole set of rollback tasks is executed, regardless of where the failure happened.
The great benefit of this approach is that all the relevant code is contained in one place. A new developer can immediately follow the steps, and also immediately understands what is required to roll back the code.
Analysis
We have made a sacrifice here by using the saga pattern, some of the parallelism has been lost. Cadence completely supports asynchronous execution of activities, and we can see one example of how it works on lines 63-68.
The activities to set up routes for our subnets have no dependencies or rollbacks necessary, so we can create a group of Promises. These asynchronous tasks are then executed in parallel and we wait for them all to complete with the Promise.allOf() command
The issue with Promises is that it becomes a bit more complicated when you want to configure saga compensations with the result of an asynchronous task. While it’s possible to accomplish it, in our case it’s not necessary.
As an alternative, I investigated what a Cadence solution would look like if we didn’t use the saga pattern and instead replicated the pattern in our legacy code. After getting it working, I determined that the saga pattern was more preferable for maintainability and simplicity.
Individual Provisioning Task
Finally, we will analyze how the logic changes for each individual task, or activity, inside a workflow.
Most of these tasks are very similar in design, so we will use one as an example, creating an AWS instance profile.
Native Java Version
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
protected InstanceProfile call0() throws Exception { final InstanceProfile instanceProfile = attemptProvisionOperation(() -> iamClient.createInstanceProfile(new CreateInstanceProfileRequest() .withInstanceProfileName(cdcId)) .getInstanceProfile() ); waitUntilReady(() -> iamClient.getInstanceProfile(new GetInstanceProfileRequest() .withInstanceProfileName(instanceProfile.getInstanceProfileName()) )); logger.info("Created instance profile {}", cdcId); return instanceProfile; } |
There are 2 things in here that are crucial to point out, attemptProvisionOperation (line 2) and waitUntilReady (line 8).
These are in-house wrapper functions that we created for exception handling. When working with cloud providers such as AWS, over a long enough period of time you will encounter transient errors or exceptions that don’t immediately warrant a complete failure.
Instaclustr developed these wrappers to capture exceptions, and depending on the scenario, retry the API call with exponential backoff. The backoff is required in case we are rate limited by AWS, and the retry mechanisms are important because data isn’t immediately replicated across all of AWS’s services.
In this example, if we create an instance profile and immediately try to use it in a subsequent action, we may encounter a EntityNotFound exception. Lines 8-11 are there to mitigate this issue. After we create the profile, we then try to read it back out. We will retry until the data has replicated, then we can move onto the next task.
This retry code is everywhere in our solution and for good reason. It is refined from years of experience creating, updating, and deleting infrastructure across multiple cloud service providers.
Cadence Java Version
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
@Override public void createInstanceProfile(final CdcInfo cdcInfo) { AmazonIdentityManagement iamClient = getIamClient(cdcInfo); iamClient.createInstanceProfile( new CreateInstanceProfileRequest().withInstanceProfileName(cdcInfo.id.toString())); logger.info("Created instance profile {}", cdcInfo.id); } @Override public String getInstanceProfileByName(final CdcInfo cdcInfo) { AmazonIdentityManagement iamClient = getIamClient(cdcInfo); return iamClient.getInstanceProfile(new GetInstanceProfileRequest() .withInstanceProfileName(cdcInfo.id.toString())) .getInstanceProfile() .getInstanceProfileName(); } |
As we can see here, the retry mechanisms are gone. This is because when we set up our activity stub in the previous section, we configured it with retry options. There are a number of different retry configurations available and exponential back off is natively built into these mechanisms, so we can leave Cadence to manage it.
This is really helpful for the type of errors that are transient in nature, and those that generally resolve themselves after some amount of time. With any external api call, these can be relatively common, and it’s great to not have to add code into each task to handle them.
Measuring the Difference
There we have it; we have managed to replicate some of the logic that Instaclustr uses to create clusters in AWS. And we have an extensible pattern ready to go for Azure, GCP, and anything else that comes along in the future.
Now that we have done the work, is it possible to measure any efficiency we gained by moving to Cadence? Let’s break it down.
Code Written
A somewhat facile metric, lines of code are a simple starting point when doing a comparison.
We tallied the number of lines of code it took to replicate the existing codebase and it looks like this:
| 1 | File | Lines Old – Create | Lines Old – Rollback | Lines old – total | Lines New | Lines new Rollback | Lines new total | Diff |
| 2 | CdcFactory | 67 | 67 | 62 | 62 | -5 | ||
| 3 | AWSCdcProvisioning | 30 | 28 | 58 | 41 | 5 | 46 | -12 |
| 4 | Instance Profile Task | 16 | 19 | 35 | 17 | 11 | 28 | -7 |
| 5 | CreateRole | 27 | 15 | 42 | 19 | 10 | 29 | -13 |
| 6 | AttachRole | 23 | 15 | 38 | 12 | 11 | 23 | -15 |
| 7 | Create VPC | 35 | 25 | 60 | 13 | 10 | 23 | -37 |
| 8 | IGW | 30 | 25 | 55 | 20 | 10 | 30 | -25 |
| 9 | Subnets | 30 | 14 | 44 | 12 | 13 | 25 | -19 |
| 10 | Route table | 30 | 15 | 45 | 16 | 11 | 27 | -18 |
| 11 | Associate | 22 | 0 | 22 | 5 | 0 | 5 | -17 |
| 12 | Misc | 54 | 54 | 10 | 10 | 20 | -34 | |
| 13 | Total | 364 | 156 | 520 | 227 | 91 | 318 | -202 |
First, this is for illustrative purposes only! There are hundreds of different variables in play here, but for our example the Cadence implementation ends up with roughly two thirds the number of lines of code.
You can see the bulk of the difference is contained in the old code when we are creating infrastructure, and that makes sense. As I mentioned before, we are extremely careful to wrap most calls in the retry wrappers to make the system as durable as possible for the transient errors we may encounter.
With Cadence all that logic isn’t necessary, so it significantly cuts down on the boilerplate code.
The other significant savings is by employing the saga pattern. Because all the rollback code is co-located with the provisioning code, we save lines by not having to wire up the rollback tasks, and re-accessing the data that is already available.
Infrastructure Costs
In order to use Cadence, we need a Cadence cluster. This requires the Cadence application itself, and a persistence store. We will be using Apache Cassandra which takes the required infrastructure to +2 extra things.
We can now get rid of RabbitMQ. Cadence clients can start workflows, taking care of the original request message and Cadence uses task lists to route signals to different implementations, which we will be using to start our child workflows for the different cloud service providers.
Our PostgreSQL server is still necessary, it’s used as the source of truth for other services like our REST API and monitoring pipeline. However, we no longer need the tables we were using to track the provisioning tasks.
All of the information necessary to execute, run and recover from failure is contained in Cadence and its persistence store. This is a benefit in the future as well, because we no longer have to update the PostgreSQL schema to support some new technology or cloud service provider.
That takes us to a +1 “infrastructure cost” for the Cadence solution and less SQL code.
Fostering Resilience
When discussing RabbitMQ I mentioned that it protects us from temporary service outages. The basic concept is that we use RabbitMQ to queue up provisioning requests, so if the provisioning service goes down, the in-flight requests aren’t lost, which would be a Bad Thing.
With our existing design, if the provisioning service crashes, any in-flight provisioning activity is forfeit. It isn’t rolled back and we don’t know what step it got to. To mitigate this, we could have implemented every single sub-task as a RabbitMQ message, but as I mentioned before, there are externalities that need to be addressed before you do that.
In the provisioning example, our provisioning service may crash just after creating the VPC. There is no automatic recovery system. We could trawl through the logs and database to figure out what step we got to but normally we just issue a delete and start the provisioning again.
In contrast, our Cadence solution is much more resilient to service failure than that. Firstly, if our Cadence worker process fails, Cadence simply waits until a worker comes back online. It knows the last successful activity that was executed, and the result was persisted in its history store. In Cadence, service failure is not only tolerated, it’s expected.
To continue our provisioning example, if our AWS worker crashes just after creating the VPC. A worker will re-join at some point, Cadence will connect to the worker and then will replay the history of the in-flight workflow. Our workflow will rebuild the state it had, step by step, then move onto the next step of creating the internet gateway.
This is incredibly powerful and we didn’t have to do anything except use Cadence. The worker could be down for hours, and there isn’t any risk of losing data or progress.
This feature benefits our deployment strategy too; we don’t have to worry about draining in-flight transactions anymore or any of the other concerns we might have by taking down running services.
Service Scaling
The final dimension we will compare is how these systems can scale.
While our provisioning system is critical, its relatively low traffic. It supports creating and tearing down clusters with hundreds of nodes but that’s relatively rare. But let’s imagine what might happen if this suddenly changes and we are flooded with provisioning and deprovisioning requests.
At the moment, we have RabbitMQ to buffer the requests. We leave a lot of performance headroom for our RabbitMQ servers but if it needs to scale, we are left with only 1 option—scale the underlying server instances.
A slight digression, I was “lucky” enough to encounter this exact scenario on Christmas Eve a few years ago. Working as on-call 3rd level support, the RabbitMQ cluster ended up horribly unbalanced and 90% of the load ended up on 1 server. I had to go into AWS and manually scale the instances up, while praying the replication settings ensured we didn’t lose any messages. Not fun!
PostgreSQL scales similarly, scaling up instances means taking them offline, even briefly, and that causes massive headaches and planning.
Our provisioning service, the monolithic microservice, is currently only built to scale vertically as well. It runs multiple services that poll the database, and although we have table locks and other mitigation processes it has never been tested with multiple instances, and we don’t know what might break if more than one system reads the same records.
Why is it like this? It’s a product 5+ years in the making! When it started, we only supported AWS and it has grown into what it is now. When you “move fast and break things”, often you make sacrifices that need to be addressed later.
Or do you? If we had started with Cadence all those years ago, the scaling problem would have become much easier. Cadence itself is a cluster of nodes, and it scales horizontally. If the Cadence cluster is approaching performance limits, we can throw more nodes at it.
Our Cadence persistence store is Apache Cassandra—this too scales horizontally. If Cadence needs more storage, we can add more nodes. All of this is invisible to the Cadence workers.
What about the applications which are performing the workflow activities—the Cadence workers? Since we are using child workflows assigned to their own task lists, we can assign resources with surgical precision.
Are we seeing an increased load in Azure signups? The Azure workers can be scaled up to handle that load independently of anything else. Is GCP provisioning slowing down? We can downscale the workers for that provider. We can even go a step further—if we implement our workers with a Kubernetes autoscaling pod, these things could be happening automatically.
Could we do it with our native Java application? Sure, but Cadence encourages you to design your applications in a way where these solutions are immediately available to you and the tooling to help you implement them.
Final Thoughts
The goal for this exercise was to take an existing application and see what we could gain by converting it to use Cadence.
In reality, there is no value in taking a perfectly functional application like this and converting it for fun. The application we took is a heavily tested and optimized system that has proven itself over years of operation as one of the backbones of Instaclustr’s journey to where we are now.
Having said that, there absolutely is value in comparing and reflecting on what advantages we could have if we used Cadence from the start.
Having implemented a small portion of our provisioner in Cadence, we’ve seen the ways it can be optimized and simplified.
We were able to:
- Decrease the amount of code and increase the maintainability with easier to read code
- Simplify the rollback process by implementing the saga pattern
- Keep the exception resilience we had with native retry logic
- Improve the resilience of the system as a whole, for both downstream outage and local service outages
- Add scalability when required and targeted to specific requirements.
This didn’t come for free; we had some increase in infrastructure and using a new client framework. But we didn’t introduce any new language or DSL. We wrote regular java code, not yaml configuration files!
We are worrying less about about
- Retry policies
- Flakey downstream API’s
- Failure scenarios and recovery solutions
- Deployment strategies for mission critical applications.
We never do anyway—until it fails the first time, test in production!
More seriously, all of these things increase developer velocity—the golden metric that all engineering teams strive to improve and the standard for keeping developers happy and moving efficiently.
Cadence didn’t happen by mistake or coincidence. It was created because the team at Uber understood how much time was being dedicated to all of those tasks that, while extremely important, don’t contribute to business value to the company.
From its inception in those early days at Uber, Cadence has now transitioned to a widely used, fully open source solution. Community members like Instaclustr are developing fixes and enhancements that are learnt from our real experience, and contributing them back to the project.
This ensures Cadence will continue to improve, and make developers lives easier now and into the future.