It’s Quiz time! What does CDC stand for?
- Centers for Disease Control and Prevention
- Control Data Corporation
- Change Data Capture
(1) In the last year the U.S. Centers for Disease Control and Prevention (cdc.gov) has certainly been in the forefront of the news, and their Apache Kafka Covid-19 pipeline was the inspiration for my ongoing Kafka Connect streaming data pipeline series. So when colleagues at work recently mentioned CDC for databases I was initially perplexed.
(2) The second CDC that came to mind was the Control Data Corporation. This CDC was a now-defunct 1960s mainframe computer company, perhaps most famous for the series of supercomputers built by Seymour Cray before he started his own company. The CDC 6600 was the first computer to hit 1 megaFLOPS (arguably making it the first “supercomputer”), which it achieved by replacing the older and hotter-running Germanium transistors (see section 5.5 below) with the new silicon transistor.

(3) But soon another word was introduced into the conversation which clarified the definition of CDC, Debezium! Although it sounds like a newly discovered metallic element, it’s actually a new open source distributed platform for Change Data Capture from multiple different databases. Like germanium, most metallic elements end in “ium”, and surprisingly the latest “ium” element, moscovium, was only officially named in 2016. The name Debezium (DBs + “ium”) was indeed inspired by the periodic table of elements.
1. What is Change Data Capture?
Change Data Capture has been around for almost as long as databases (I even wrote one for Oracle in the 1990s!) and is an approach used to capture changes in one database to propagate to other systems to reuse (often other databases, but not exclusively).
Some basic approaches rely on SQL to detect rows with changes (e.g. using timestamps and/or monotonically increasing values), or internal database triggers. Oracle, for example, produces a “change table” that can be used by external applications to get changes of interest to them. These approaches typically put extra load on the database and were therefore often only run as batch jobs (e.g. at night when the normal load was low or even paused), so the change data was only available to downstream systems once every 24 hours—far from real time!
More practical CDC solutions involve the use of custom applications (or sometimes native functionality) on the database to access the commit logs and make changes available externally, so called log-based CDC. Debezium uses this approach to get the change data, and then uses Kafka and Kafka Connect to make it available scalably and reliably to multiple downstream systems.
2. CDC Use Cases
The Debezium Github has a good introduction to Debezium Change Data Capture use cases, and I’ve thought of a few more (including some enabled by Kafka Streams):
- Cache invalidation, updating or rebuilding Indexes, etc.
- Simplifying and decoupling applications. For example:
- Instead of an application having to write to multiple systems, it can write to just one, and then:
- Other applications can receive change data from the one system, enabling multiple applications to share a single database
- Data integration across multiple heterogeneous systems
- For triggering real-time event-driven applications
- To use database changes to drive streaming queries
- To recreate state in Kafka Streams/Tables
- To build aggregate objects using Kafka Streams
The last two use cases (or possibly design patterns) use the power of Kafka Streams. There is also a recent enhancement for Kafka Streams which assists in relational to streams mapping using foreign key joins.
3. Kafka Connect JDBC Source Connectors
Recently I’ve been experimenting with Kafka Connect JDBC and PostgreSQL sink connectors for extensions to my pipeline blogs. But what I hadn’t taken much notice of was that there were also some JDBC source connectors available. For example, the Aiven open source jdbc connector comes in sink and source flavors. It supports multiple database types and has configurations for setting the poll interval and the query modes (e.g. batch and various incremental modes). However, it will put extra load onto the database, and the change data will be out of date for as long as the poll interval, and it only works for SQL databases, not for NoSQL databases such as Cassandra.
There is at least one open source Kafka Connect Cassandra source connector, which we mention on our support pages, but it is not suitable for production environments.
So how does Debezium work for production CDC scenarios?
4. How does Debezium Work? Connectors + Kafka Connect
Debezium has “Connectors” (to capture change data events) for the following list of databases currently:
- MySQL
- MongoDB
- PostgreSQL
- SQL Server
- Oracle (preview)
- Cassandra (preview)
Debezium requires custom database side applications/plugins to be installed for some of these (PostgreSQL and Cassandra), which means that you may need the cooperation of your cloud provider if you are running them in the cloud.
Debezium “Connectors” always write the change data events to a Kafka cluster, and most of them are in fact Kafka Connect source connectors, so you will most likely need a Kafka Connect cluster as well, which brings other advantages. Here’s an example of the Debezium architecture for a PostgreSQL source, which uses both Kafka Connect source and sink connectors.
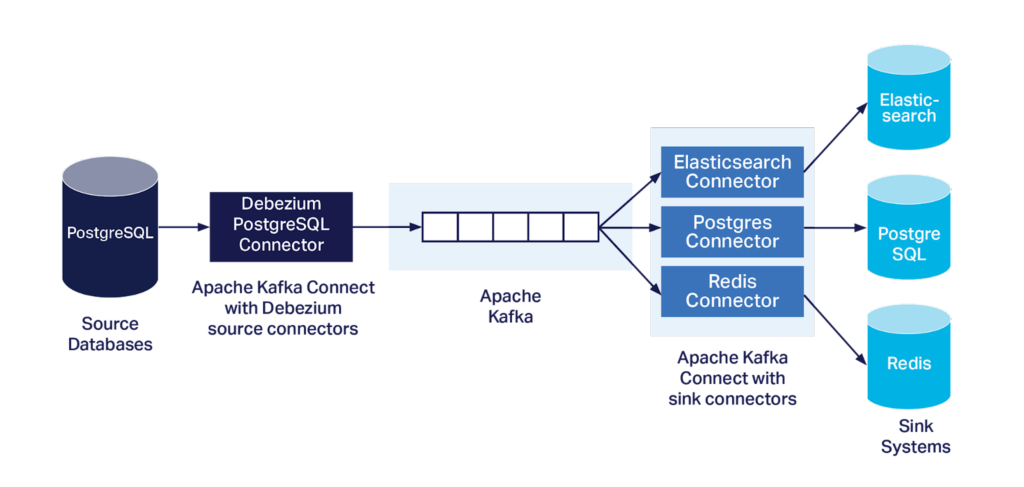
Using Kafka and Kafka Connect clusters to capture and deliver change data capture messages has many potential benefits. Kafka is very fast and supports high message throughput. It works well as a buffer to absorb load spikes to ensure that the downstream systems are not overloaded and that no messages are lost. It also supports multiple producers, enabling change data capture from multiple sources.
Moreover, multiple sinks can subscribe to the same messages, allowing for sharing and routing of the CDC data among heterogeneous target systems. The loose coupling between consumers and producers is beneficial for the CDC use case, as the consumers can consume from multiple heterogeneous data sources, and transform, filter, and act on the change types depending on the target systems.
One of my favorite Kafka “super powers” is its ability to “replay” events. This is useful for the CDC use case for scenarios involving rebuilding the state of downstream systems (e.g. reindexing) without putting extra load on the upstream databases (essentially using Kafka as a cache). An earlier (pre-Kafka) heterogeneous open source CDC system, DataBus (from LinkedIn), also identified this as a vital feature, which they called “look-back”.

5. Change Data Capture With the Debezium Cassandra Connector
Instaclustr recently built, deployed, configured, monitored, secured, ran, tested, fixed, and tuned the first Debezium Cassandra Connector on our managed platform for a customer. The customer use case was to replicate some tables from Cassandra into another analytical database, in close to real time, and reliably at scale. The rest of this blog series looks at the Debezium Cassandra Connector in more detail, explores how the change data could be used by downstream applications, and summarises our experiences from this project.
Because the Cassandra connector is “incubating” it’s important to understand that the following changes will be ignored:
- TTL on collection-type columns
- Range deletes
- Static columns
- Triggers
- Materialized views
- Secondary indices
- Lightweight transactions
5.1 What “Change Data” is Produced by the Debezium Cassandra “Connector”?
Most Debezium connectors are implemented as Kafka Connect source connectors, except for the Debezium Cassandra Connector, which just uses a Kafka producer to send the change data to Kafka as shown in this diagram:
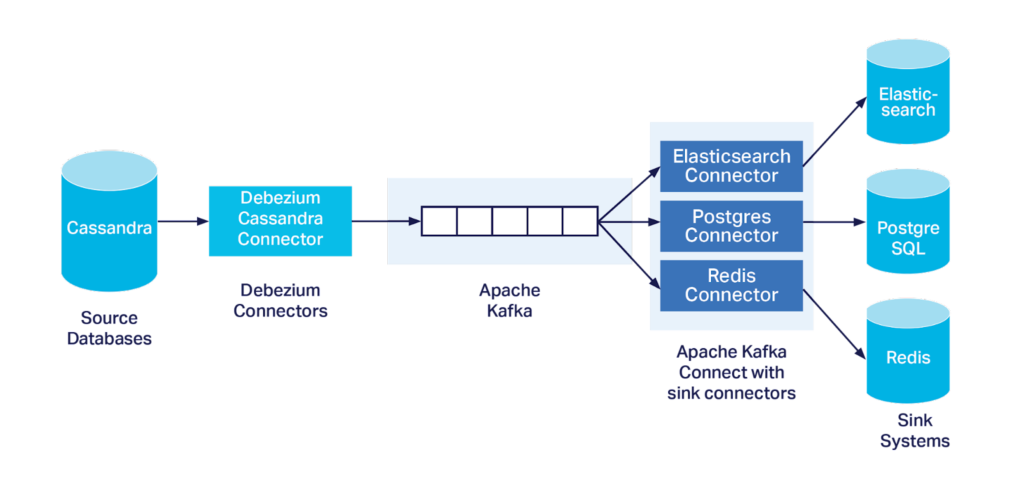
From the documentation for the Debezium Cassandra “Connector”, I discovered that the Debezium Cassandra Connector:
- Writes events for all Casandra insert, update and delete operation
- On a single table
- To a single Kafka topic
- All change events have a key and value
- The Kafka key is a JSON object that contains:
- A “key schema”, an array of fields including the name, type and possibly a “logicalType” (which is not really explained anywhere), and
- A payload (name value pairs);
- For each column in the primary key of the table
- The Kafka value is a bit more complicated, see below
The value of a change event message is more complicated, is JSON, and contains the following fields:
- op: The type of operation, i = insert, u = update, d = delete
- after: The state of the row after the operation occurred
- source: Source metadata for the event
- ts_ms: The time at which Debezium processed the event
Unlike some other Debezium connectors, there is no “before” field (as the Cassandra commit log doesn’t contain this information), and some fields are optional (after, and ts_ms). Note that the value of “after” fields is null if their state is unchanged, except for primary key fields which always have a value.
Here are some simplified examples, for keeping web page metrics.
First, an insert (where the table primary key is page, and there are also visits and conversions):
INSERT INTO analytics (page, visits, conversions) VALUES ("/the-power-of-kafka-partitions", 4533, 55);
Results in this (simplified, the source fields are omitted for clarity) message value:
{
"op": "c",
"ts_ms": 1562202942832,
"after": {
"page": {
"value": "/the-power-of-kafka-partitions/",
"deletion_ts": null,
"set": true
},
"visits": {
"value": 4533,
"deletion_ts": null,
"set": true
},
"conversions": {
"value": 55,
"deletion_ts": null,
"set": true
}
},
"source": {
...
}
}
Note that each of the after fields has a new value as the record has been created.
Now let’s see what happens with an UPDATE operation:
UPDATE analytics
SET visits=4534
WHERE page="/the-power-of-kafka-partitions/";
An UPDATE results in a change message with this value:
{
"op": "u",
"ts_ms": 1562202944319,
"after": {
"page": {
"value": "/the-power-of-kafka-partitions/",
"deletion_ts": null,
"set": true
},
"visits": {
"value": 4534,
"deletion_ts": null,
"set": true
},
"conversions": null
},
"source": {
...
}
}
Note that for this UPDATE change event, the op field is now “u”, the after visits field has the new value, the after conversions field is null as it didn’t change, but the after page value is included as it’s the primary key (even though it didn’t change).
And finally a DELETE operation:
DELETE FROM analytics
WHERE page="/the-power-of-kafka-partitions/";
Results in this message value:
{
"op": "d",
"ts_ms": 1562202946329,
"after": {
"page": {
"value": "/the-power-of-kafka-partitions/",
"deletion_ts": 1562202947401,
"set": true
},
"visits": null,
"conversions": null }
},
"source": {
...
}
}
The op is now “d”, the after field only contains a value for page (the primary key) and deletion_ts now has a value, and other field values are null.
To summarize:
- For all operation types the primary key after fields have values
- For updates, non-primary key after fields have values if the value changed, otherwise null
- For deletes, non-primary key after fields have null values
And now it’s time for a brief etymological interlude, brought to you by the suffix “ezium”:
Oddly enough, there is only one word permitted in Scrabble which ends in “ezium”, trapezium! Sadly. Debezium hasn’t made it into the Scrabble dictionary yet. A trapezium (in most of the world) is a quadrilateral with at least one pair of parallel sides. But note that in the U.S. this is called a trapezoid, and a “trapezium” has no parallel sides. Here’s an “Australian” Trapezium = U.S. Trapezoid:

Read Next: Change Data Capture (CDC) With Kafka Connect and the Debezium Cassandra Connector (Part 2)
Instaclustr managed Kafka service streamlines deployment. Get in touch to discuss our managed Kafka service for your application.