Integrating diverse data systems seamlessly can be a daunting task, but the OpenSearch Sink Connector simplifies this challenge with precision and efficiency. Serving as a vital bridge between Apache Kafka and OpenSearch, this connector makes real-time data integration and streaming more accessible than ever.
With its ease of use, flexibility, and scalability, the OpenSearch Sink Connector empowers organizations to transform complex data pipelines into streamlined operations tailored to their needs. Whether you’re managing system logs, user behavior metrics, or IoT data, this tool ensures consistent and reliable data flow without added complexity.
This blog will guide you through configuring the OpenSearch Sink Connector, giving you the insights and steps you need to optimize your data streaming processes and unlock the true potential of your Kafka ecosystem.
Pre-requisites
- An Apache Kafka cluster
- A Kafka Connect cluster
- An OpenSearch cluster
- An open source Kafka OpenSearch Sink Connector
NetApp Instaclustr offers these as managed services (Apache Kafka, Kafka Connect, OpenSearch), including a managed OpenSearch Sink Connector, which is available by default (pre-loaded and ready to use) in our Kafka Connect clusters. The linked support documentation provides details for this connector.
Simplifications are applied, such as using JSON data with no schemas or Karapace (open source Kafka schema registry)—i.e., schemaless JSON. This extends the previous ten-part blog series (real-time zero-code tide data processing pipeline), now adding a third sink system, OpenSearch (previously explored Elasticsearch and PostgreSQL® sinks), with eventual changes to the source data.
Why you need Kafka Connect
One of the main use cases for Apache Kafka® is to stream data between heterogeneous systems using the Kafka Connect API (one of the 5 Kafka APIs, including Producer, Consumer, Streams, Connect, Admin). Kafka Connect enables you to solve the multiple source/sink heterogeneity without having to have a separate pipeline for every permutation—just one source or sink connector per technology.
For it to work, you need an Apache Kafka cluster, a Kafka Connect cluster (which runs the connectors reliably at scale), a source connector for every system you want to read data from into Kafka, and a sink connector for every system you want to write the data from Kafka out to.
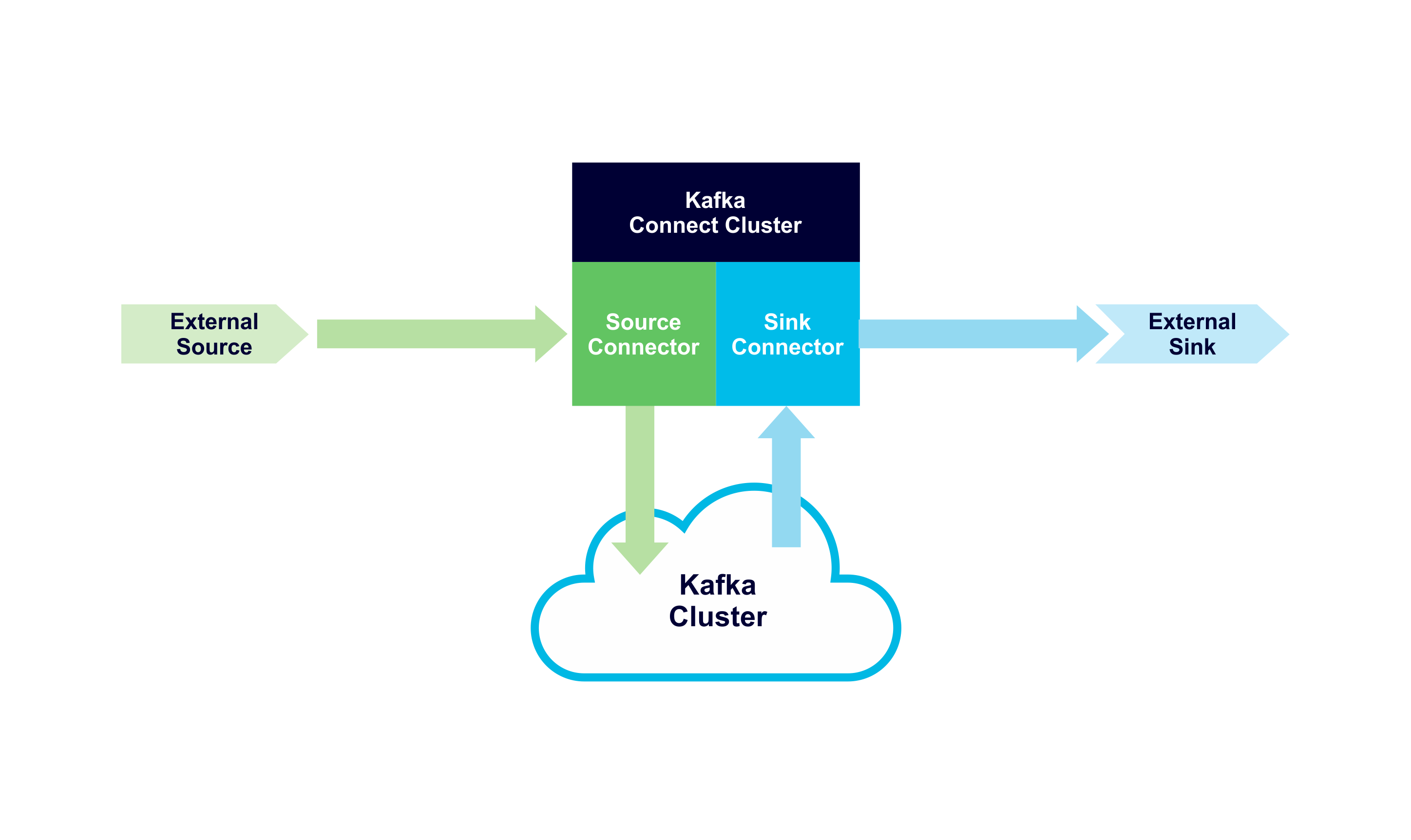
Basic cluster setup
The basic setup is similar to here—you need to create a Kafka cluster, an OpenSearch cluster, and a Kafka Connect cluster (with the Kafka cluster as the target cluster, and the OpenSearch cluster as a connected cluster—this enables Kafka connectors to access the OpenSearch cluster). You also need to add the IP address of your client machine to the firewalls for each cluster.
If you click on the Kafka Connect “Connectors” tab you will see the list of available connectors, which will include io.aiven.kafka.connect.opensearch.OpensearchSinkConnector; this is the connector we will use. Note that for this introduction we don’t have a Source System—we assume the data is already in Kafka (or put some sample data into a topic with the CLI producer). In practice, we also need to add a source system and Kafka Source Connectors eventually.
Configuring the OpenSearch sink connector
Connector configuration is typically more of an art than a science, as all connectors are subtly (or sometimes radically) “different.” Each connector typically has support for generic Kafka connect configurations, and configurations that are specific for each connector, including configurations that are peculiar to the related source or sink technology. For our open source OpenSearch Sink Connector, the specific configurations are documented here.
How do you find the correct configurations and run the connector? Mainly by trial and error (but customers of our managed platform using the bundled OpenSearch sink connector have access to support for general help and our consulting team for more specialized help).
The steps involved are as follows.
First, create a JSON configuration file with your best guess for the configurations. Here’s my final configuration, which took me several attempts to get working:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{ "name": " os_sink_test", "config": { "connector.class": "io.aiven.kafka.connect.opensearch.OpensearchSinkConnector", "topics": "test1", "connection.url": "OS_URL:OS_PORT", "connection.username": "OS_User", "connection.password": "OS_Password", "tasks.max": "3", "key.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "errors.deadletterqueue.topic.name": "dead1", "key.ignore": "true", "schema.ignore": "true", "drop.invalid.message": "true", "behavior.on.malformed.documents": "ignore", "errors.log.enable": "true", "errors.log.include.message": "true", "errors.tolerance": "all", "value.converter.schemas.enable": "false" } } |
Note that because we are using basic JSON we don’t need the AVRO specific configurations from the support page example (which is currently an AVRO use case—including value.converter.basic.auth.credentials.source).
To write records to OpenSearch you need to allow the connector to find and connect to it, by adding the correct values for connection.url, connection.username, and connection.password. These are all found under the OpenSearch cluster “Connection Info” tab and Examples (e.g., CURL).
To debug the configurations, it’s essential to be able to see any error logs that the connector produces when it fails—unless you are very lucky you will need a few iterations of configuration changes to get them right, and failures and the resulting logs are the best way to debug connectors. You therefore need these two lines from the start, otherwise, the connector fails silently:
|
1 2 |
"errors.log.enable": "true", "errors.log.include.message": "true" |
But where do the error logs go? Error logs are available on the Instaclustr Console for the Kafka Connect cluster under the “Application Logs” tab. You can “View Logs” for each broker in the cluster, but you will find that the error messages are only visible in one of the brokers.
Where does the connector read the data from? The Kafka cluster that is the target of the Kafka Connect cluster. And from the topics specified in the “topics” list in the configuration file. tasks.max determines how many concurrent instances of the connector will be run; three is a good starting point. Kafka Connect provides a reliable and scalable distributed platform for running connectors, as tasks will be automatically restarted if they are “killed.” However, there’s a catch! If the connectors fail themselves, then they are not automatically restarted. This is where it gets tricky to ensure the configurations are sufficiently robust to catch and prevent failures. A common cause of failure is if records are not valid JSON.
We want to be able to process JSON records with no schema and ignore the record key if present. To do this the following settings are used:
|
1 2 3 4 5 |
"key.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "key.ignore": "true", "schema.ignore": "true", "value.converter.schemas.enable": "false" |
This enables the “happy path” where the records are in a correct JSON format. However, if the records don’t contain valid JSON then the connectors will rapidly fail. How can we prevent this? With the following configurations:
|
1 2 3 4 |
"errors.deadletterqueue.topic.name": "dead1", "drop.invalid.message": "true", "behaviour.on.malformed.documents": "ignore", "errors.tolerance": "all" |
These allow the connector to keep running even with invalid JSON records, with the invalid records being sent to a dead letter queue for subsequent inspection, the bad records are dropped from the Kafka topic, errors thrown by OpenSearch for malformed documents are ignored, and we have an infinite tolerance for errors.
See some of my previous blogs for more background about error tolerance and handling for Kafka connectors, e.g., here and here.
Running and checking the connector
This configuration file (if named os_sink_connector.json) can be used to start a connector from a command line as follows (given the Kafka Connect URL, User and Password, available from the Kafka Connect “Connection Info” tab):
|
1 |
curl https://KC_URL:8083/connectors -X POST -H 'Content-Type: application/json' -d @os_sink_connector.json -k -u KC_User:KC_Password |
If it’s successful in starting, the command will output some JSON with the requested configurations confirmed, and you can check in the Kafka Connect “Active Connectors” tab and the logs to confirm.
Did it work? You can test this pipeline out as follows.
Send some JSON data to test with the Kafka CLI producer (instructions on getting the CLI, configuring producer.config and the Kafka cluster public IP addresses are available from the Kafka Cluster “Connection Info” tab):
|
1 |
kafka-console-producer.sh --broker-list Kafka_IP:9092 --topic test --producer.config kafka.properties |
You can now type in valid JSON records or other data (e.g. duck) to see how well the connector handles errors, e.g.:
|
1 2 3 4 |
>{"name":"Paul", "Favourite book":"Quicksilver"} >{"name":"John", "Favourite book":"Raising Steam"} >duck >{"name":"Jill", "Favourite book":"Roses"} |
You can check that duck was sent to the dead letter queue with:
|
1 |
kafka-console-consumer.sh --bootstrap-server Kafka_IP:9092 --topic dead1 --consumer.config kafka.properties |
And finally check that all the valid JSON records have appeared in OpenSearch with:
|
1 2 3 4 5 6 |
curl -XGET -u OS_User:OS_Password "https://OS_URL:9200/test1/_search" -H 'Content-Type: application/json' -d' { "query": { "match_all": {} } } |
Conclusions
Configuring the Apache Kafka OpenSearch Sink Connector opens unparalleled possibilities for organizations striving to transform raw data into actionable insights. By streaming data from Kafka into OpenSearch, you unlock powerful real-time analytics, advanced search capabilities, and efficient operational monitoring. These enhancements drive faster decision-making, anomaly detection, and trend analysis, making your data more accessible and impactful.
Throughout this blog, you’ve gained practical skills in setting up and fine-tuning a Kafka OpenSearch Sink pipeline. From understanding essential configurations to ensuring error tolerance and seamless execution, you now have the tools to tackle data complexities with confidence.
This is just the beginning of what you can achieve with Kafka and OpenSearch. There are potentially lots of configuration choices for the OpenSearch sink connector—but you may need an OpenSearch guru on hand to understand some of these. Some of the configurations impact performance and scalability (e.g., batch size will be important for high throughput; see this blog), error handling, data conversion and mapping, how the key is handled, and data streams (they sound interesting, stay tuned for future updates). You also need to check your OpenSearch configurations to ensure the cluster has sufficient resources and scalability to cope with the expected load from the connectors (e.g., check and potentially increase the default shards per index).
Try it out
Don’t wait to leverage the full potential of this powerful combination! Sign up for a free 30-day trial of NetApp Instaclustr’s managed services to get hands-on experience with Apache Kafka, Kafka Connect, OpenSearch, and the pre-loaded managed OpenSearch Sink Connector. Having an OpenSearch expert onboard can help unlock even more advanced features and ensure maximum scalability for your projects, and our team is here to support you every step of the way.