OpenSearch Sink Connector
The OpenSearch Sink Connector allows you to store messages from your short-term streaming Kafka application into OpenSearch documents for querying and later use. It is based on the open-source Apache 2 licensed connector available here.
The OpenSearch Sink Connector takes a list of topics that we want to sink to the OpenSearch cluster as part of its configuration. It reads the specified topics from the source Kafka cluster from the beginning and pushes all the contained messages into the OpenSearch cluster via Kafka Connect.
Kafka Connect must be configured to deserialize the Kafka messages and serialize them for the OpenSearch datastore appropriately. As OpenSearch requires the data it is reading to be in a JSON format, we strongly recommend using Karapace Schema Registry with your Kafka cluster to guarantee the serialized data from Kafka Connect to OpenSearch will always be in an OpenSearch readable format.
This OpenSearch Sink Connector is available on the Instaclustr for Kafka Connect versions 3.6.1 or greater. If you have an older version of Kafka Connect, reach out to the Instaclustr Support Team to upgrade your cluster so you can leverage the benefits of this connector.
Configuration Properties
Before we go into the steps on setting up the connector, let’s take a brief look at the 2 areas that need to be configured:
- Kafka Connect Configuration:
- Kafka Connect needs to be configured to handle deserialization from Kafka and serialization for the sink. This is done by Kafka Connect converters.
- Depending upon your use-case, you might also want to do simple transformations like changing the topic name to append the date at the end. There is a lot of inbuilt support for transformation using Kafka Connect transformers.
- For a list of exhaustive configurations of Kafka Connect properties, refer to this documentation.
- Connector Configuration: The connectors have additional configuration that is specific to the type of connector. For the OpenSearch Sink connector, an exhaustive list of the configuration properties can be found in OpenSearch Sink Connector Documentation.
How to configure the OpenSource OpenSearch® Sink Connector for Apache Kafka®
The rest of this guide will walk you through configuring the connector using Instaclustr for Kafka with Karapace Schema Registry add-on, Instaclustr for OpenSearch and the Instaclustr for Kafka Connect clusters.
You can refer to this guide for detailed instructions on how to create an Instaclustr for Kafka cluster with Karapace Schema Registry add-on enabled, this guide for creating an OpenSearch cluster and this guide for creating a Kafka Connect cluster.
Additionally, you will need to keep the following details handy:
- OS_CONNECTION_URL: OpenSearch connection URL (e.g., https://HOST:PORT)
- OS_USERNAME: OpenSearch username
- OS_PASSWORD: OpenSearch password
- TOPIC_LIST: A comma-separated list of Kafka topics to sink
- SCHEMA_REGISTRY_HOST: Kafka hostname
- SCHEMA_REGISTRY_PORT: Kafka Schema Registry port
- SCHEMA_REGISTRY_USER: Schema Registry username
- SCHEMA_REGISTRY_PASSWORD: Schema Registry password
- KAFKA_CONNECT_USER: Kafka Connect username (with connector creation privileges)
- KAFKA_CONNECT_PASSWORD: Kafka Connect user password
These details can be found in the connection info pages of the respective clusters.
Step 1: Configure the OpenSearch and Kafka Schema Registry firewall to allow Kafka Connect access
The Kafka Connect public IPs need to be added to the firewall allow list for the source and the sink cluster
- See this guide for detailed instructions on how to allow IPs through the firewall on Kafka Schema Registry clusters. Once you have added the IPs to the firewall the Kafka cluster firewall rules should contain entries like the following:
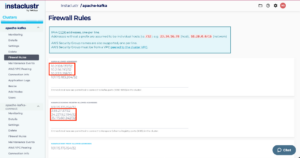
Example with IPs to the firewall the Kafka cluster firewall configuration
- See this guide for detailed instructions on how to allow IPs through the firewall on OpenSearch clusters. If your OpenSearch cluster, is on the Instaclustr managed service, you can also use the connected clusters tab to add the necessary IPs with the click of a button as shown below:
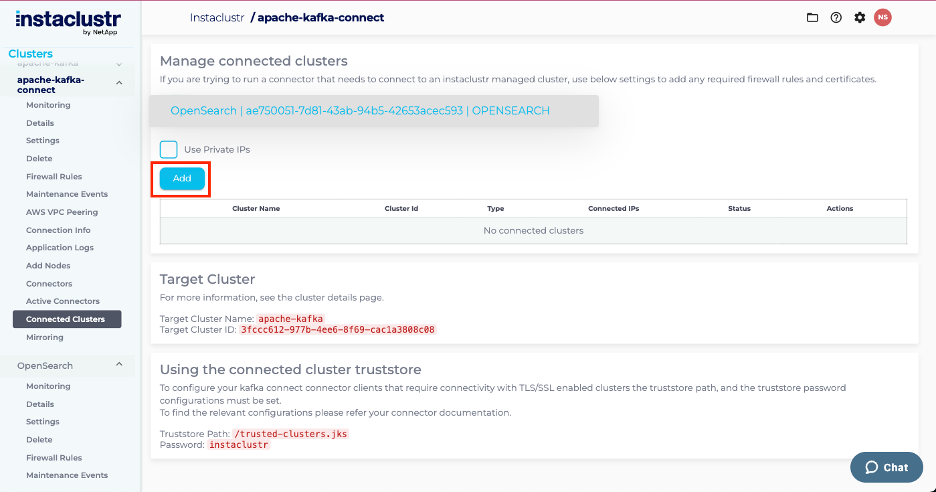
- Upon saving the cluster, it should appear in the connected cluster as:

- At the end of this step, the OpenSearch firewall rules should contain the following:
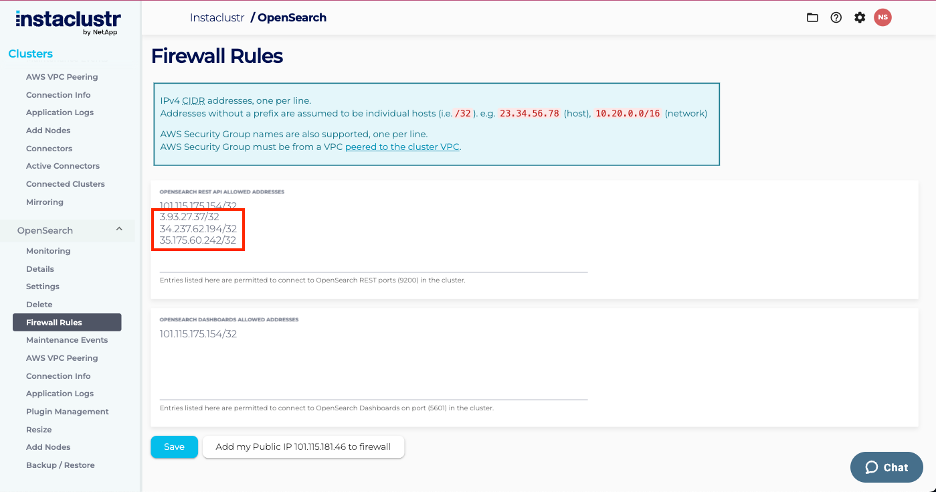
Example with IPs to the firewall the OpenSearch cluster firewall configuration
For this guide we have used public IPs, however if you’re using VPC-peered clusters, private IPs can be used instead of public IPs and Kafka Connect can be easily VPC peered to the Kafka cluster at creation if they both are in the Instaclustr Managed Service. See this guide for more details on manual VPC peering.
Step 2: Create the configuration file
In this guide we use the topic with AVRO formats, however, if you wish to use JSON formats, you can change the key.converter and the value.converter in the configuration below to org.apache.kafka.connect.json.JsonConverter as required.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "name": "sink-connector-example", "config": { "connector.class": "io.aiven.kafka.connect.opensearch.OpensearchSinkConnector", "topics": TOPIC_LIST, "connection.url": OS_CONNECTION_URL, "connection.username": OS_ USERNAME, "connection.password": OS_PASSWORD, "tasks.max": "1", "key.converter": "io.confluent.connect.avro.AvroConverter", "value.converter": "io.confluent.connect.avro.AvroConverter", "value.converter.schema.registry.url": "SCHEMA_REGISTRY_HOST: SCHEMA_REGISTRY_PORT", "value.converter.basic.auth.credentials.source": "USER_INFO", "value.converter.schema.registry.basic.auth.user.info": "SCHEMA_REGISTRY_USER: SCHEMA_REGISTRY_PASSWORD", "key.ignore": "true" } } |
Save this to a file like example-config.json.
NOTE: You may want to transform the topic by appending the current day to form a new daily index. They can be achieved using the Kafka Connect transformer properties as follows:
|
1 2 3 4 |
"transforms": "TimestampRouter", "transforms.TimestampRouter.topic.format": "${topic}-${timestamp}", "transforms.TimestampRouter.timestamp.format": "yyyy-MM-dd", "transforms.TimestampRouter.type": "org.apache.kafka.connect.transforms.TimestampRouter" |
Step 3: Post the configuration to the Kafka Connect rest API
In this example, we use curl but to interact with the Kafka Connect API as follows:
|
1 |
curl https://<kafka-connect node ip>:8083/connectors -X POST -H 'Content-Type: application/json' -d @example.json -k -u < KAFKA_CONNECT_USER: KAFKA_CONNECT_PASSWORD > |
If the request is accepted by Kafka Connect, you will see a 20x response containing the configuration.
You can verify the connector’s status in the Kafka Connect Active Connectors tab.
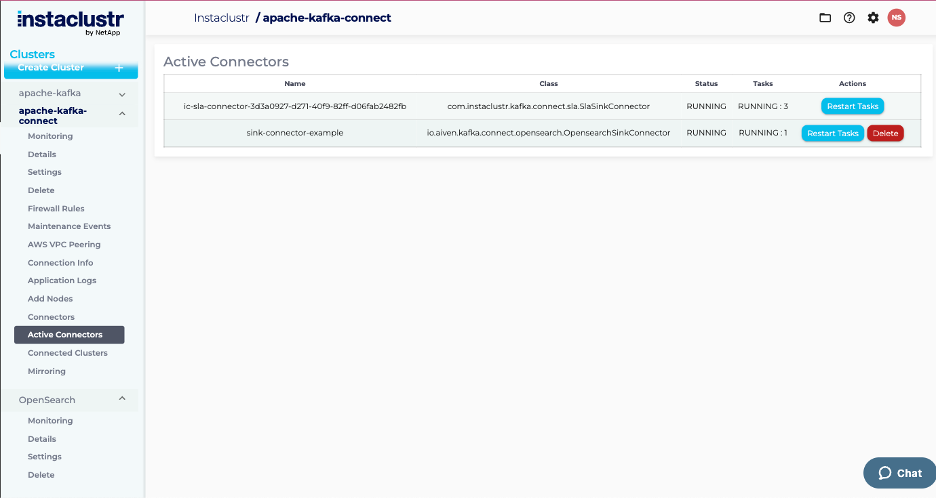
Active connectors page after OpenSearch sink connector is added
Step 4: Post messages to the Kafka topic and ensure they are forwarded to the OpenSearch Sink
At this stage, the OpenSearch sink connector is active, but the configured Kafka topic (e.g., orders) may not yet exist or contain messages. You can start producing messages to the Kafka topics using this guide.
Step 5: Check that the messages are being stored in OpenSearch
After a brief interval, the corresponding OpenSearch index should be created and populated with these messages.
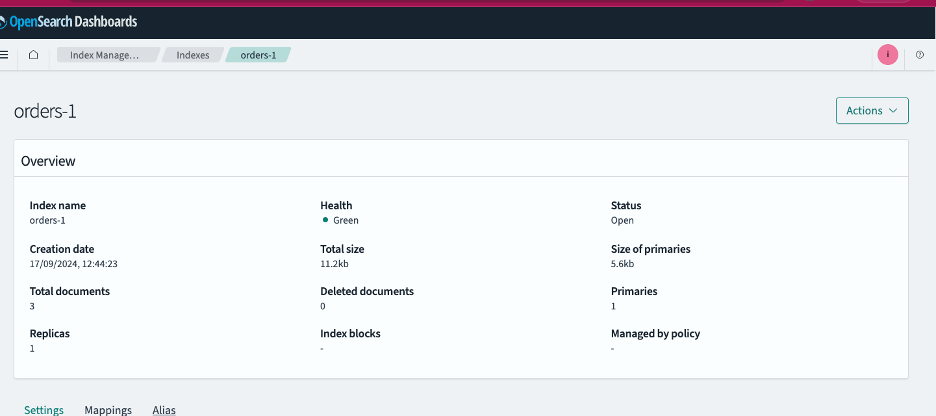
Example of topic index on OpenSearch Dashboard after messages have been sent to Kafka Schema Registry and sinked into OpenSearch
Troubleshooting
If messages are not arriving in OpenSearch, first check the active connectors tab to see if the connector has failed. If so, you can review application logs to identify configuration issues. To find the application logs, refer to this guide. If you require further help, contact Instaclustr support.